 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveNODE: A Continuous Normalizing Flow for Speech Synthesis
Paper and Code
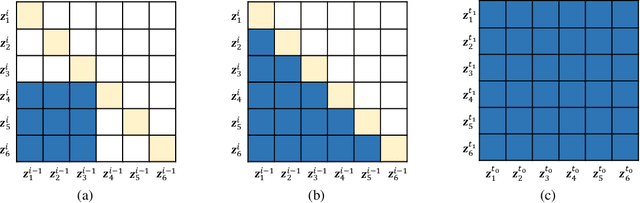
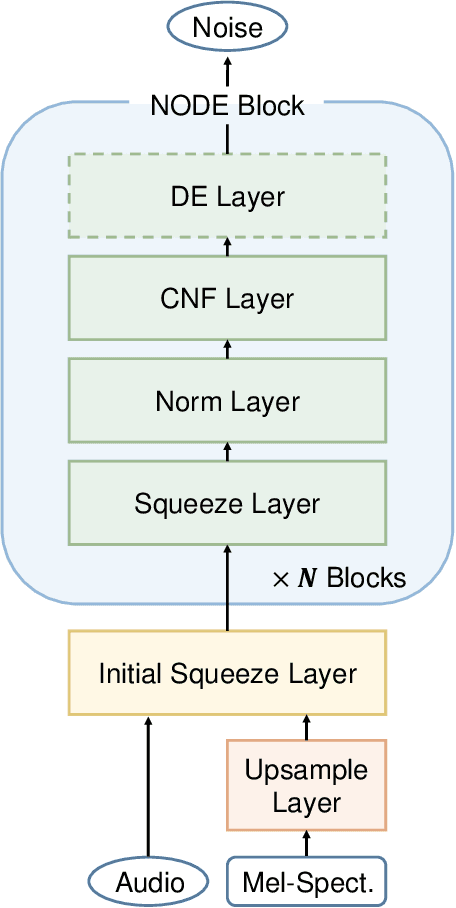

In recent years, various flow-based generative models have been proposed to generate high-fidelity waveforms in real-time. However, these models require either a well-trained teacher network or a number of flow steps making them memory-inefficient. In this paper, we propose a novel generative model called WaveNODE which exploits a continuous normalizing flow for speech synthesis. Unlike the conventional models, WaveNODE places no constraint on the function used for flow operation, thus allowing the usage of more flexible and complex functions. Moreover, WaveNODE can be optimized to maximize the likelihood without requiring any teacher network or auxiliary loss terms. We experimentally show that WaveNODE achieves comparable performance with fewer parameters compared to the conventional flow-based vocoders.