 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Diff-TTS: A Denoising Diffusion Model for Text-to-Speech
Apr 03, 2021

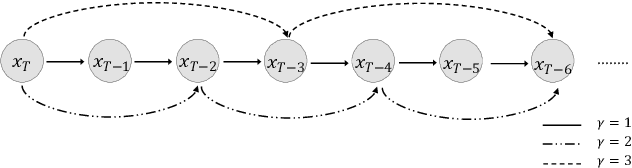
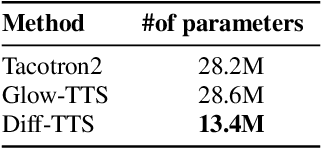
Although neural text-to-speech (TTS) models have attracted a lot of attention and succeeded in generating human-like speech, there is still room for improvements to its naturalness and architectural efficiency. In this work, we propose a novel non-autoregressive TTS model, namely Diff-TTS, which achieves highly natural and efficient speech synthesis. Given the text, Diff-TTS exploits a denoising diffusion framework to transform the noise signal into a mel-spectrogram via diffusion time steps. In order to learn the mel-spectrogram distribution conditioned on the text, we present a likelihood-based optimization method for TTS. Furthermore, to boost up the inference speed, we leverage the accelerated sampling method that allows Diff-TTS to generate raw waveforms much faster without significantly degrading perceptual quality. Through experiments, we verified that Diff-TTS generates 28 times faster than the real-time with a single NVIDIA 2080Ti GPU.
Expressive Text-to-Speech using Style Tag
Apr 01, 2021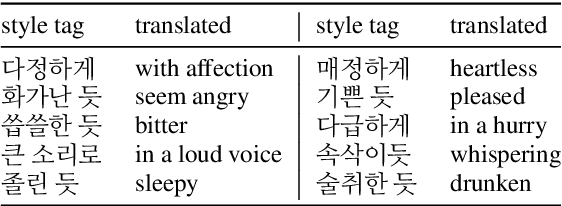
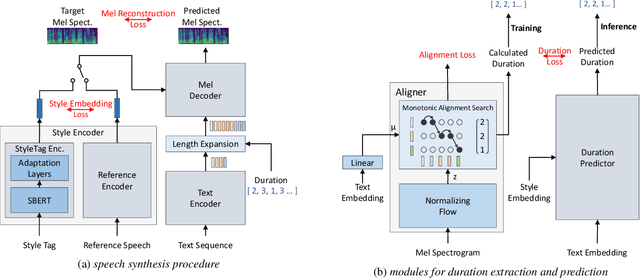
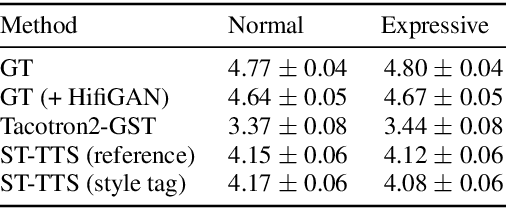
As recent text-to-speech (TTS) systems have been rapidly improved in speech quality and generation speed, many researchers now focus on a more challenging issue: expressive TTS. To control speaking styles, existing expressive TTS models use categorical style index or reference speech as style input. In this work, we propose StyleTagging-TTS (ST-TTS), a novel expressive TTS model that utilizes a style tag written in natural language. Using a style-tagged TTS dataset and a pre-trained language model, we modeled the relationship between linguistic embedding and speaking style domain, which enables our model to work even with style tags unseen during training. As style tag is written in natural language, it can control speaking style in a more intuitive, interpretable, and scalable way compared with style index or reference speech. In addition, in terms of model architecture, we propose an efficient non-autoregressive (NAR) TTS architecture with single-stage training. The experimental result shows that ST-TTS outperforms the existing expressive TTS model, Tacotron2-GST in speech quality and expressiveness.
WaveNODE: A Continuous Normalizing Flow for Speech Synthesis
Jul 02, 2020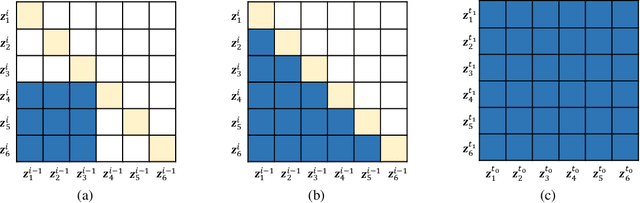
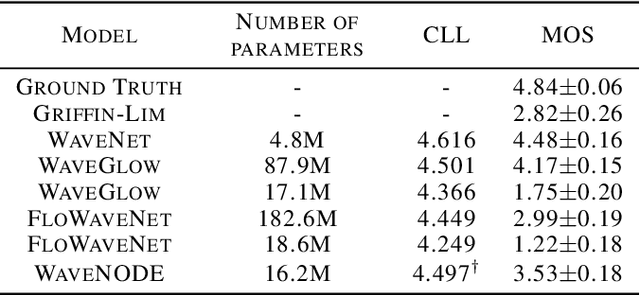
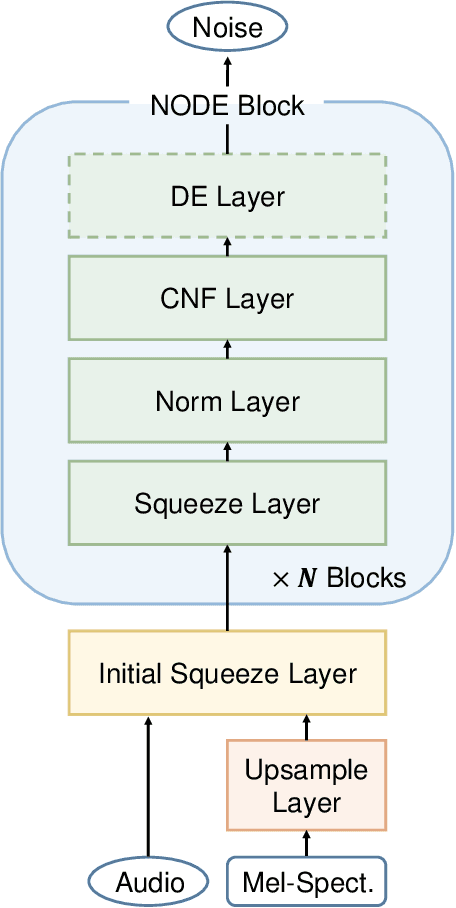

In recent years, various flow-based generative models have been proposed to generate high-fidelity waveforms in real-time. However, these models require either a well-trained teacher network or a number of flow steps making them memory-inefficient. In this paper, we propose a novel generative model called WaveNODE which exploits a continuous normalizing flow for speech synthesis. Unlike the conventional models, WaveNODE places no constraint on the function used for flow operation, thus allowing the usage of more flexible and complex functions. Moreover, WaveNODE can be optimized to maximize the likelihood without requiring any teacher network or auxiliary loss terms. We experimentally show that WaveNODE achieves comparable performance with fewer parameters compared to the conventional flow-based vocoders.
Real-time Automatic Word Segmentation for User-generated Text
Oct 31, 2018
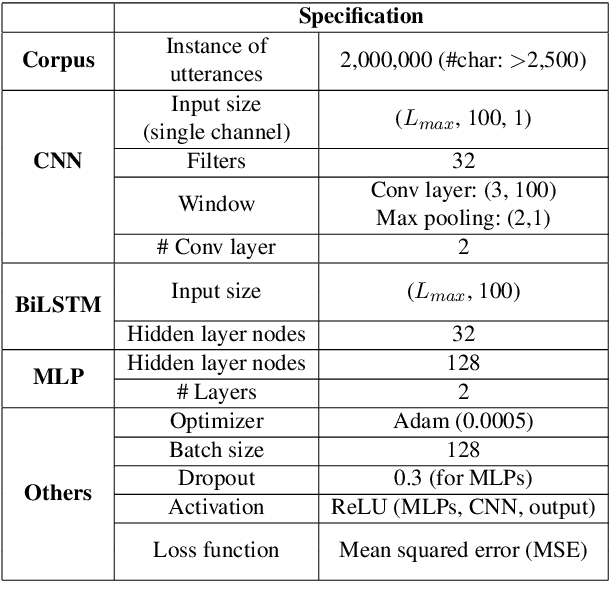
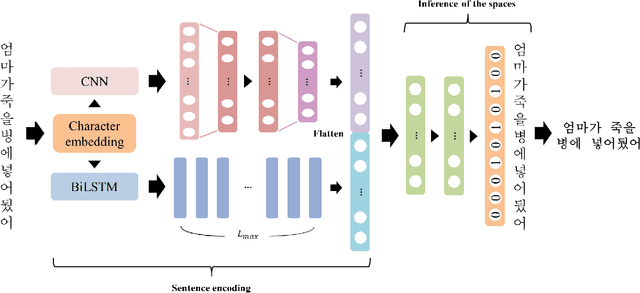
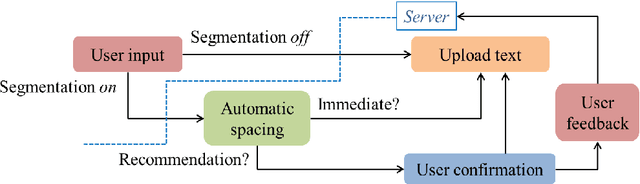
For readability and possibly for disambiguation, appropriate word segmentation is recommended for written text. In this paper, we propose a real-time assistive technology that utilizes an automatic segmentation. The language primarily investigated is Korean, a head-final language with the various morpho-syllabic blocks as a character set. The training scheme is fully neural network-based and extensible to other languages, as is implemented in this study for English. Besides, we show how the proposed system can be utilized in a web-based fine-tuning for a user-generated text. With a qualitative and quantitative comparison with widely used text processing toolkits, we show the reliability of the proposed system and how it fits with conversation-style and non-canonical texts. Demonstration for both languages is freely available online.