 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom National Curricula to Cultural Awareness: Constructing Open-Ended Culture-Specific Question Answering Dataset
Jan 08, 2026Large language models (LLMs) achieve strong performance on many tasks, but their progress remains uneven across languages and cultures, often reflecting values latent in English-centric training data. To enable practical cultural alignment, we propose a scalable approach that leverages national social studies curricula as a foundation for culture-aware supervision. We introduce CuCu, an automated multi-agent LLM framework that transforms national textbook curricula into open-ended, culture-specific question-answer pairs. Applying CuCu to the Korean national social studies curriculum, we construct KCaQA, comprising 34.1k open-ended QA pairs. Our quantitative and qualitative analyses suggest that KCaQA covers culture-specific topics and produces responses grounded in local sociocultural contexts.
RICoTA: Red-teaming of In-the-wild Conversation with Test Attempts
Jan 29, 2025

User interactions with conversational agents (CAs) evolve in the era of heavily guardrailed large language models (LLMs). As users push beyond programmed boundaries to explore and build relationships with these systems, there is a growing concern regarding the potential for unauthorized access or manipulation, commonly referred to as "jailbreaking." Moreover, with CAs that possess highly human-like qualities, users show a tendency toward initiating intimate sexual interactions or attempting to tame their chatbots. To capture and reflect these in-the-wild interactions into chatbot designs, we propose RICoTA, a Korean red teaming dataset that consists of 609 prompts challenging LLMs with in-the-wild user-made dialogues capturing jailbreak attempts. We utilize user-chatbot conversations that were self-posted on a Korean Reddit-like community, containing specific testing and gaming intentions with a social chatbot. With these prompts, we aim to evaluate LLMs' ability to identify the type of conversation and users' testing purposes to derive chatbot design implications for mitigating jailbreaking risks. Our dataset will be made publicly available via GitHub.
Hermit Kingdom Through the Lens of Multiple Perspectives: A Case Study of LLM Hallucination on North Korea
Jan 10, 2025Hallucination in large language models (LLMs) remains a significant challenge for their safe deployment, particularly due to its potential to spread misinformation. Most existing solutions address this challenge by focusing on aligning the models with credible sources or by improving how models communicate their confidence (or lack thereof) in their outputs. While these measures may be effective in most contexts, they may fall short in scenarios requiring more nuanced approaches, especially in situations where access to accurate data is limited or determining credible sources is challenging. In this study, we take North Korea - a country characterised by an extreme lack of reliable sources and the prevalence of sensationalist falsehoods - as a case study. We explore and evaluate how some of the best-performing multilingual LLMs and specific language-based models generate information about North Korea in three languages spoken in countries with significant geo-political interests: English (United States, United Kingdom), Korean (South Korea), and Mandarin Chinese (China). Our findings reveal significant differences, suggesting that the choice of model and language can lead to vastly different understandings of North Korea, which has important implications given the global security challenges the country poses.
Single Ground Truth Is Not Enough: Add Linguistic Variability to Aspect-based Sentiment Analysis Evaluation
Oct 13, 2024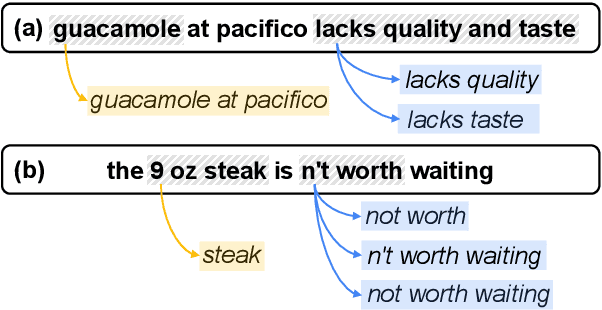
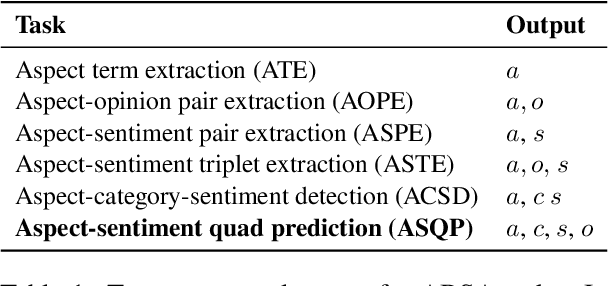
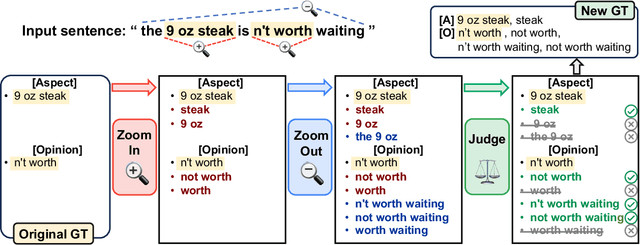
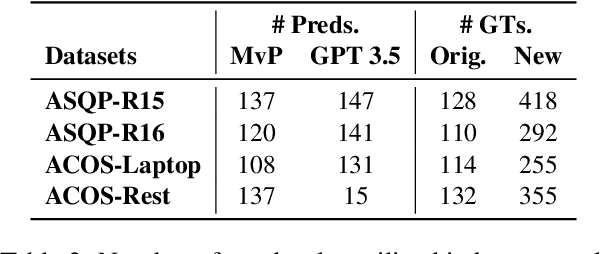
Aspect-based sentiment analysis (ABSA) is the challenging task of extracting sentiment along with its corresponding aspects and opinions from human language. Due to the inherent variability of natural language, aspect and opinion terms can be expressed in various surface forms, making their accurate identification complex. Current evaluation methods for this task often restrict answers to a single ground truth, penalizing semantically equivalent predictions that differ in surface form. To address this limitation, we propose a novel, fully automated pipeline that augments existing test sets with alternative valid responses for aspect and opinion terms. This approach enables a fairer assessment of language models by accommodating linguistic diversity, resulting in higher human agreement than single-answer test sets (up to 10%p improvement in Kendall's Tau score). Our experimental results demonstrate that Large Language Models (LLMs) show substantial performance improvements over T5 models when evaluated using our augmented test set, suggesting that LLMs' capabilities in ABSA tasks may have been underestimated. This work contributes to a more comprehensive evaluation framework for ABSA, potentially leading to more accurate assessments of model performance in information extraction tasks, particularly those involving span extraction.
Evaluating Span Extraction in Generative Paradigm: A Reflection on Aspect-Based Sentiment Analysis
Apr 17, 2024

In the era of rapid evolution of generative language models within the realm of natural language processing, there is an imperative call to revisit and reformulate evaluation methodologies, especially in the domain of aspect-based sentiment analysis (ABSA). This paper addresses the emerging challenges introduced by the generative paradigm, which has moderately blurred traditional boundaries between understanding and generation tasks. Building upon prevailing practices in the field, we analyze the advantages and shortcomings associated with the prevalent ABSA evaluation paradigms. Through an in-depth examination, supplemented by illustrative examples, we highlight the intricacies involved in aligning generative outputs with other evaluative metrics, specifically those derived from other tasks, including question answering. While we steer clear of advocating for a singular and definitive metric, our contribution lies in paving the path for a comprehensive guideline tailored for ABSA evaluations in this generative paradigm. In this position paper, we aim to provide practitioners with profound reflections, offering insights and directions that can aid in navigating this evolving landscape, ensuring evaluations that are both accurate and reflective of generative capabilities.
When Crowd Meets Persona: Creating a Large-Scale Open-Domain Persona Dialogue Corpus
Apr 01, 2023



Building a natural language dataset requires caution since word semantics is vulnerable to subtle text change or the definition of the annotated concept. Such a tendency can be seen in generative tasks like question-answering and dialogue generation and also in tasks that create a categorization-based corpus, like topic classification or sentiment analysis. Open-domain conversations involve two or more crowdworkers freely conversing about any topic, and collecting such data is particularly difficult for two reasons: 1) the dataset should be ``crafted" rather than ``obtained" due to privacy concerns, and 2) paid creation of such dialogues may differ from how crowdworkers behave in real-world settings. In this study, we tackle these issues when creating a large-scale open-domain persona dialogue corpus, where persona implies that the conversation is performed by several actors with a fixed persona and user-side workers from an unspecified crowd.
DAGAM: Data Augmentation with Generation And Modification
Apr 06, 2022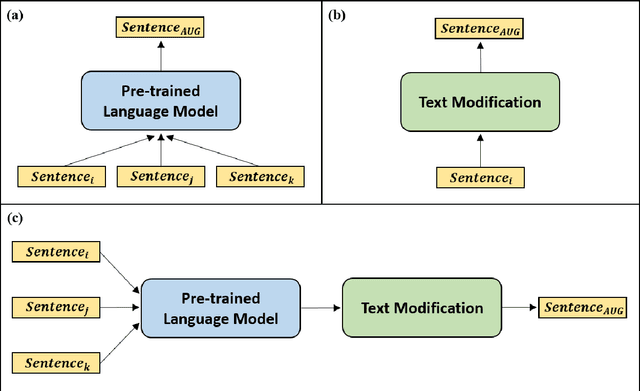
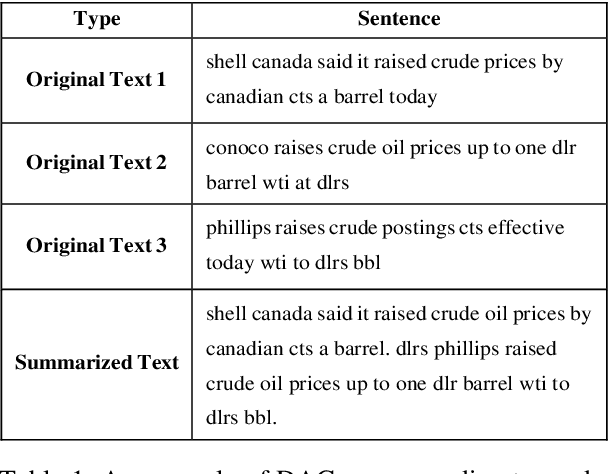

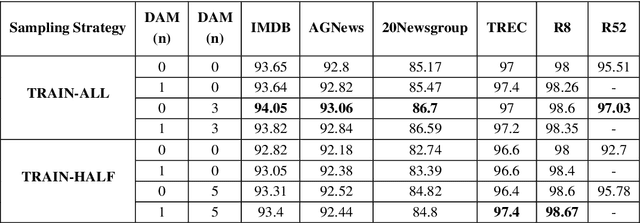
Text classification is a representative downstream task of natural language processing, and has exhibited excellent performance since the advent of pre-trained language models based on Transformer architecture. However, in pre-trained language models, under-fitting often occurs due to the size of the model being very large compared to the amount of available training data. Along with significant importance of data collection in modern machine learning paradigm, studies have been actively conducted for natural language data augmentation. In light of this, we introduce three data augmentation schemes that help reduce underfitting problems of large-scale language models. Primarily we use a generation model for data augmentation, which is defined as Data Augmentation with Generation (DAG). Next, we augment data using text modification techniques such as corruption and word order change (Data Augmentation with Modification, DAM). Finally, we propose Data Augmentation with Generation And Modification (DAGAM), which combines DAG and DAM techniques for a boosted performance. We conduct data augmentation for six benchmark datasets of text classification task, and verify the usefulness of DAG, DAM, and DAGAM through BERT-based fine-tuning and evaluation, deriving better results compared to the performance with original datasets.
APEACH: Attacking Pejorative Expressions with Analysis on Crowd-Generated Hate Speech Evaluation Datasets
Feb 25, 2022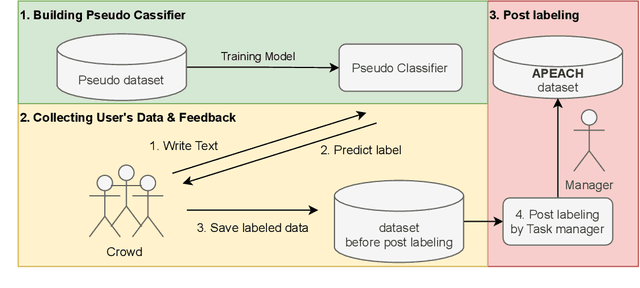
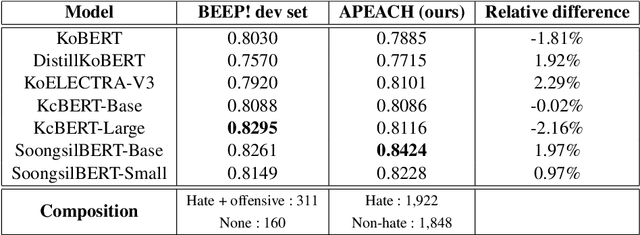
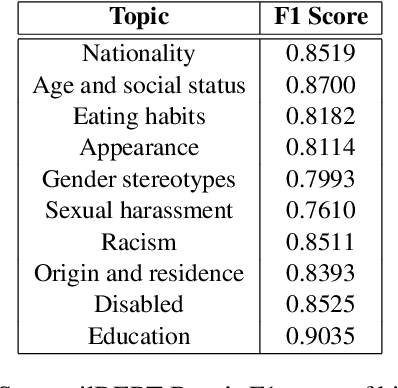
Detecting toxic or pejorative expressions in online communities has become one of the main concerns for preventing the users' mental harm. This led to the development of large-scale hate speech detection datasets of various domains, which are mainly built upon web-crawled texts with labels by crowd workers. However, for languages other than English, researchers might have to rely on only a small-sized corpus due to the lack of data-driven research of hate speech detection. This sometimes misleads the evaluation of prevalently used pretrained language models (PLMs) such as BERT, given that PLMs often share the domain of pretraining corpus with the evaluation set, resulting in over-representation of the detection performance. Also, the scope of pejorative expressions might be restricted if the dataset is built on a single domain text. To alleviate the above problems in Korean hate speech detection, we propose APEACH,a method that allows the collection of hate speech generated by unspecified users. By controlling the crowd-generation of hate speech and adding only a minimum post-labeling, we create a corpus that enables the generalizable and fair evaluation of hate speech detection regarding text domain and topic. We Compare our outcome with prior work on an annotation-based toxic news comment dataset using publicly available PLMs. We check that our dataset is less sensitive to the lexical overlap between the evaluation set and pretraining corpus of PLMs, showing that it helps mitigate the unexpected under/over-representation of model performance. We distribute our dataset publicly online to further facilitate the general-domain hate speech detection in Korean.
Kosp2e: Korean Speech to English Translation Corpus
Jul 06, 2021Most speech-to-text (S2T) translation studies use English speech as a source, which makes it difficult for non-English speakers to take advantage of the S2T technologies. For some languages, this problem was tackled through corpus construction, but the farther linguistically from English or the more under-resourced, this deficiency and underrepresentedness becomes more significant. In this paper, we introduce kosp2e (read as `kospi'), a corpus that allows Korean speech to be translated into English text in an end-to-end manner. We adopt open license speech recognition corpus, translation corpus, and spoken language corpora to make our dataset freely available to the public, and check the performance through the pipeline and training-based approaches. Using pipeline and various end-to-end schemes, we obtain the highest BLEU of 21.3 and 18.0 for each based on the English hypothesis, validating the feasibility of our data. We plan to supplement annotations for other target languages through community contributions in the future.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021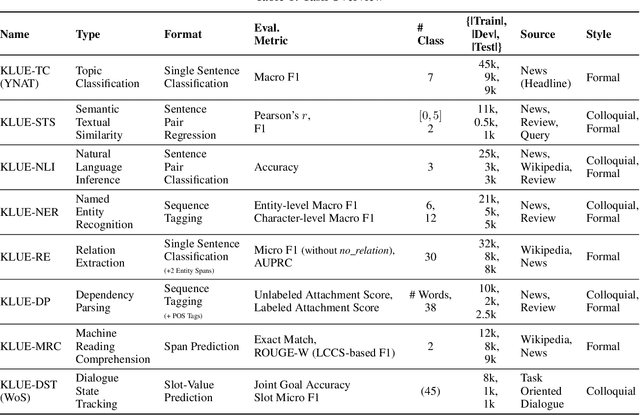
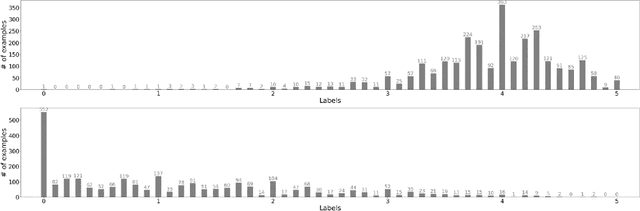
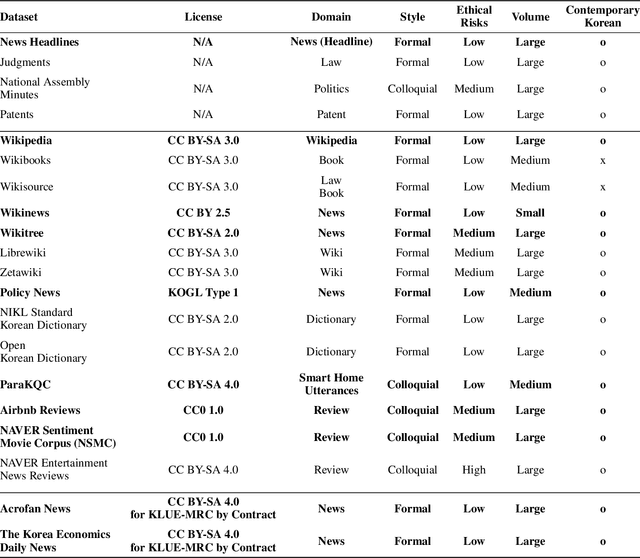
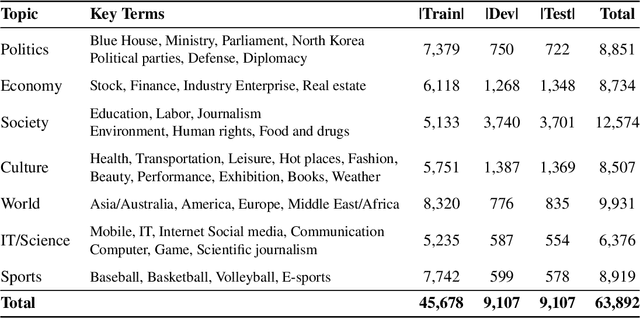
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.