 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Ground Truth Is Not Enough: Add Linguistic Variability to Aspect-based Sentiment Analysis Evaluation
Paper and Code
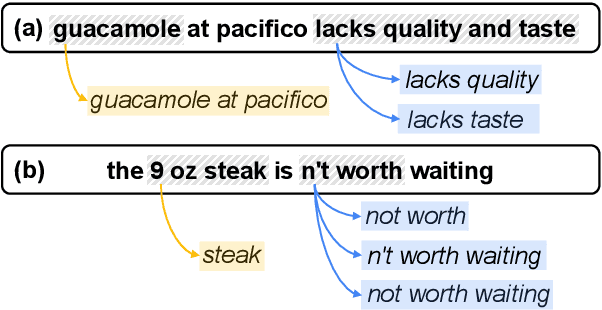
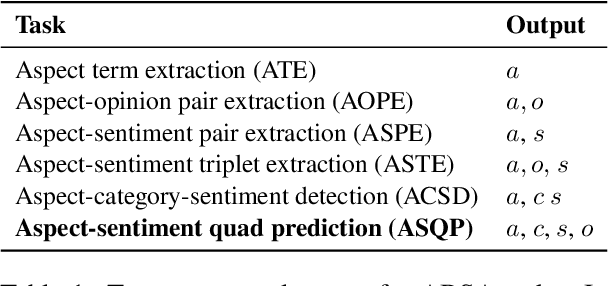
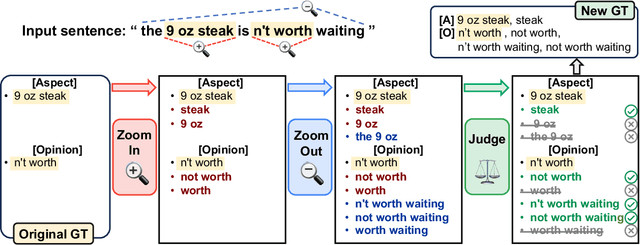
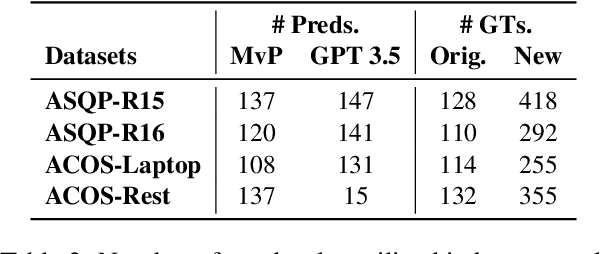
Aspect-based sentiment analysis (ABSA) is the challenging task of extracting sentiment along with its corresponding aspects and opinions from human language. Due to the inherent variability of natural language, aspect and opinion terms can be expressed in various surface forms, making their accurate identification complex. Current evaluation methods for this task often restrict answers to a single ground truth, penalizing semantically equivalent predictions that differ in surface form. To address this limitation, we propose a novel, fully automated pipeline that augments existing test sets with alternative valid responses for aspect and opinion terms. This approach enables a fairer assessment of language models by accommodating linguistic diversity, resulting in higher human agreement than single-answer test sets (up to 10%p improvement in Kendall's Tau score). Our experimental results demonstrate that Large Language Models (LLMs) show substantial performance improvements over T5 models when evaluated using our augmented test set, suggesting that LLMs' capabilities in ABSA tasks may have been underestimated. This work contributes to a more comprehensive evaluation framework for ABSA, potentially leading to more accurate assessments of model performance in information extraction tasks, particularly those involving span extraction.