 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Ground Truth Is Not Enough: Add Linguistic Variability to Aspect-based Sentiment Analysis Evaluation
Oct 13, 2024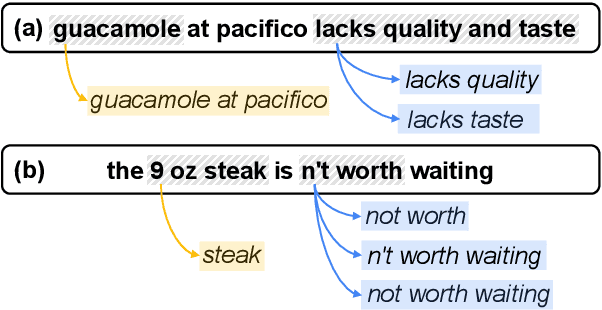
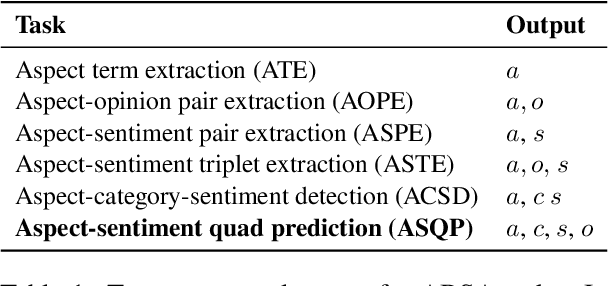
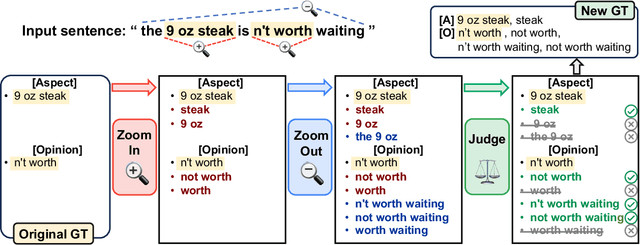
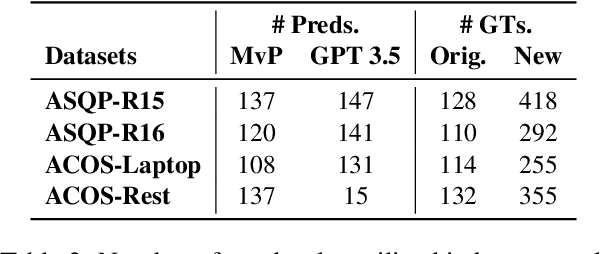
Aspect-based sentiment analysis (ABSA) is the challenging task of extracting sentiment along with its corresponding aspects and opinions from human language. Due to the inherent variability of natural language, aspect and opinion terms can be expressed in various surface forms, making their accurate identification complex. Current evaluation methods for this task often restrict answers to a single ground truth, penalizing semantically equivalent predictions that differ in surface form. To address this limitation, we propose a novel, fully automated pipeline that augments existing test sets with alternative valid responses for aspect and opinion terms. This approach enables a fairer assessment of language models by accommodating linguistic diversity, resulting in higher human agreement than single-answer test sets (up to 10%p improvement in Kendall's Tau score). Our experimental results demonstrate that Large Language Models (LLMs) show substantial performance improvements over T5 models when evaluated using our augmented test set, suggesting that LLMs' capabilities in ABSA tasks may have been underestimated. This work contributes to a more comprehensive evaluation framework for ABSA, potentially leading to more accurate assessments of model performance in information extraction tasks, particularly those involving span extraction.
Evaluating Span Extraction in Generative Paradigm: A Reflection on Aspect-Based Sentiment Analysis
Apr 17, 2024

In the era of rapid evolution of generative language models within the realm of natural language processing, there is an imperative call to revisit and reformulate evaluation methodologies, especially in the domain of aspect-based sentiment analysis (ABSA). This paper addresses the emerging challenges introduced by the generative paradigm, which has moderately blurred traditional boundaries between understanding and generation tasks. Building upon prevailing practices in the field, we analyze the advantages and shortcomings associated with the prevalent ABSA evaluation paradigms. Through an in-depth examination, supplemented by illustrative examples, we highlight the intricacies involved in aligning generative outputs with other evaluative metrics, specifically those derived from other tasks, including question answering. While we steer clear of advocating for a singular and definitive metric, our contribution lies in paving the path for a comprehensive guideline tailored for ABSA evaluations in this generative paradigm. In this position paper, we aim to provide practitioners with profound reflections, offering insights and directions that can aid in navigating this evolving landscape, ensuring evaluations that are both accurate and reflective of generative capabilities.
HistRED: A Historical Document-Level Relation Extraction Dataset
Jul 10, 2023
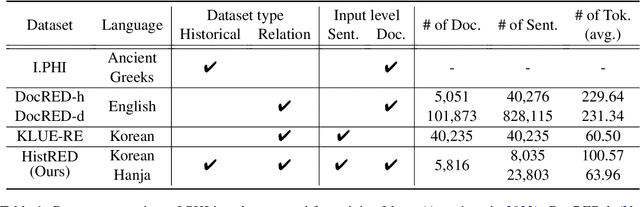
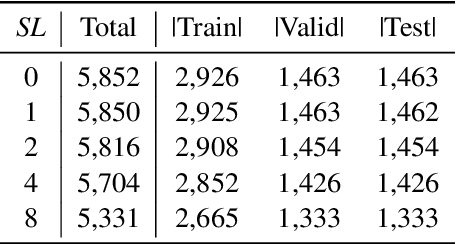
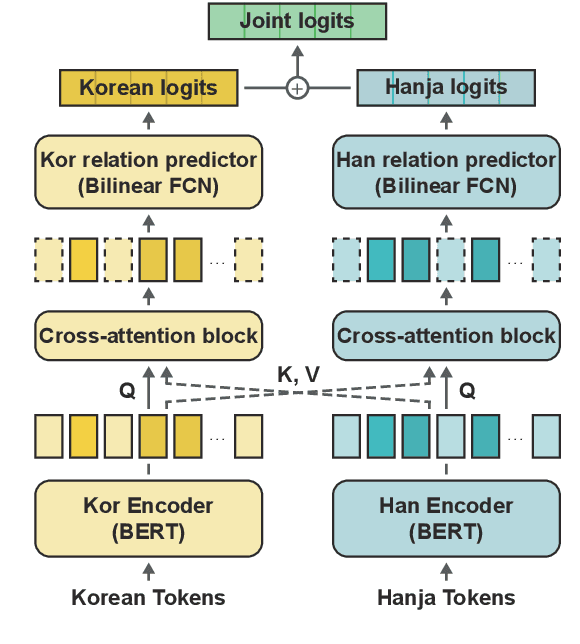
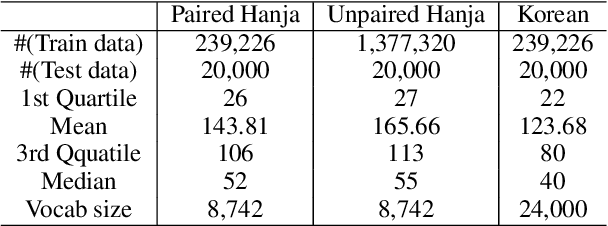
Despite the extensive applications of relation extraction (RE) tasks in various domains, little has been explored in the historical context, which contains promising data across hundreds and thousands of years. To promote the historical RE research, we present HistRED constructed from Yeonhaengnok. Yeonhaengnok is a collection of records originally written in Hanja, the classical Chinese writing, which has later been translated into Korean. HistRED provides bilingual annotations such that RE can be performed on Korean and Hanja texts. In addition, HistRED supports various self-contained subtexts with different lengths, from a sentence level to a document level, supporting diverse context settings for researchers to evaluate the robustness of their RE models. To demonstrate the usefulness of our dataset, we propose a bilingual RE model that leverages both Korean and Hanja contexts to predict relations between entities. Our model outperforms monolingual baselines on HistRED, showing that employing multiple language contexts supplements the RE predictions. The dataset is publicly available at: https://huggingface.co/datasets/Soyoung/HistRED under CC BY-NC-ND 4.0 license.
Guiding Users to Where to Give Color Hints for Efficient Interactive Sketch Colorization via Unsupervised Region Prioritization
Oct 25, 2022



Existing deep interactive colorization models have focused on ways to utilize various types of interactions, such as point-wise color hints, scribbles, or natural-language texts, as methods to reflect a user's intent at runtime. However, another approach, which actively informs the user of the most effective regions to give hints for sketch image colorization, has been under-explored. This paper proposes a novel model-guided deep interactive colorization framework that reduces the required amount of user interactions, by prioritizing the regions in a colorization model. Our method, called GuidingPainter, prioritizes these regions where the model most needs a color hint, rather than just relying on the user's manual decision on where to give a color hint. In our extensive experiments, we show that our approach outperforms existing interactive colorization methods in terms of the conventional metrics, such as PSNR and FID, and reduces required amount of interactions.
CG-NeRF: Conditional Generative Neural Radiance Fields
Dec 07, 2021
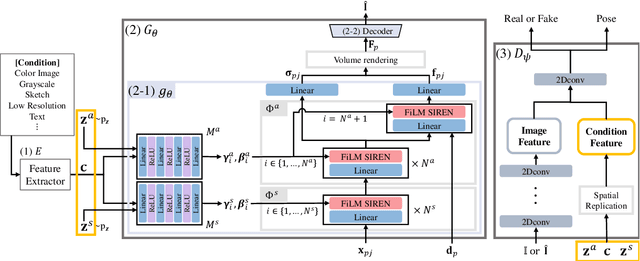


While recent NeRF-based generative models achieve the generation of diverse 3D-aware images, these approaches have limitations when generating images that contain user-specified characteristics. In this paper, we propose a novel model, referred to as the conditional generative neural radiance fields (CG-NeRF), which can generate multi-view images reflecting extra input conditions such as images or texts. While preserving the common characteristics of a given input condition, the proposed model generates diverse images in fine detail. We propose: 1) a novel unified architecture which disentangles the shape and appearance from a condition given in various forms and 2) the pose-consistent diversity loss for generating multimodal outputs while maintaining consistency of the view. Experimental results show that the proposed method maintains consistent image quality on various condition types and achieves superior fidelity and diversity compared to existing NeRF-based generative models.
Restoring and Mining the Records of the Joseon Dynasty via Neural Language Modeling and Machine Translation
May 07, 2021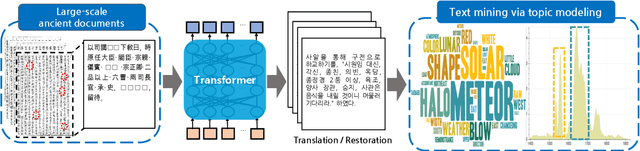


Understanding voluminous historical records provides clues on the past in various aspects, such as social and political issues and even natural science facts. However, it is generally difficult to fully utilize the historical records, since most of the documents are not written in a modern language and part of the contents are damaged over time. As a result, restoring the damaged or unrecognizable parts as well as translating the records into modern languages are crucial tasks. In response, we present a multi-task learning approach to restore and translate historical documents based on a self-attention mechanism, specifically utilizing two Korean historical records, ones of the most voluminous historical records in the world. Experimental results show that our approach significantly improves the accuracy of the translation task than baselines without multi-task learning. In addition, we present an in-depth exploratory analysis on our translated results via topic modeling, uncovering several significant historical events.
Meta-Learning for Low-Resource Unsupervised Neural MachineTranslation
Oct 18, 2020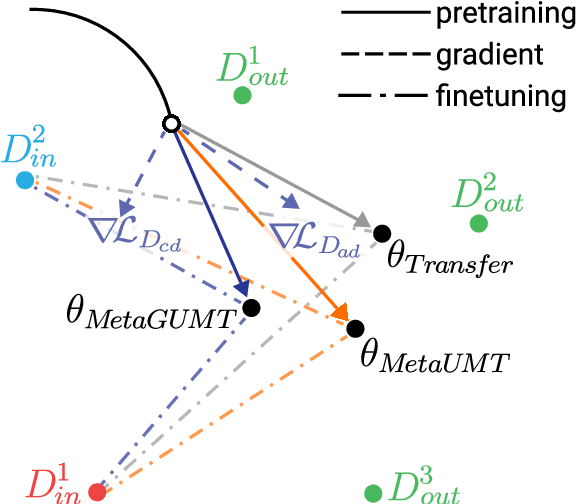
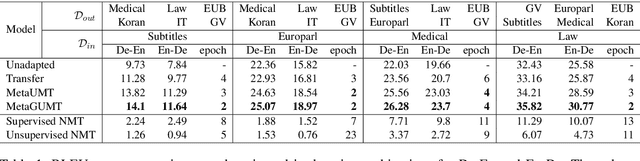
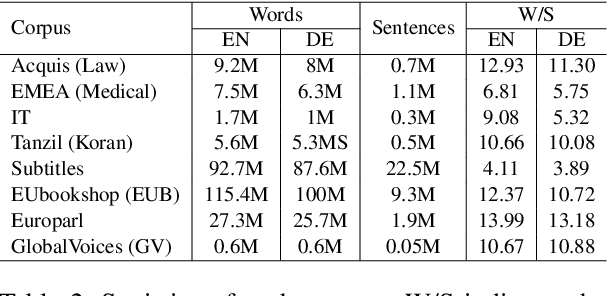

Unsupervised machine translation, which utilizes unpaired monolingual corpora as training data, has achieved comparable performance against supervised machine translation. However, it still suffers from data-scarce domains. To address this issue, this paper presents a meta-learning algorithm for unsupervised neural machine translation (UNMT) that trains the model to adapt to another domain by utilizing only a small amount of training data. We assume that domain-general knowledge is a significant factor in handling data-scarce domains. Hence, we extend the meta-learning algorithm, which utilizes knowledge learned from high-resource domains to boost the performance of low-resource UNMT. Our model surpasses a transfer learning-based approach by up to 2-4 BLEU scores. Extensive experimental results show that our proposed algorithm is pertinent for fast adaptation and consistently outperforms other baseline models.