 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairQE: Multi-Agent Framework for Mitigating Gender Bias in Translation Quality Estimation
Apr 23, 2026Quality Estimation (QE) aims to assess machine translation quality without reference translations, but recent studies have shown that existing QE models exhibit systematic gender bias. In particular, they tend to favor masculine realizations in gender-ambiguous contexts and may assign higher scores to gender-misaligned translations even when gender is explicitly specified. To address these issues, we propose FairQE, a multi-agent-based, fairness-aware QE framework that mitigates gender bias in both gender-ambiguous and gender-explicit scenarios. FairQE detects gender cues, generates gender-flipped translation variants, and combines conventional QE scores with LLM-based bias-mitigating reasoning through a dynamic bias-aware aggregation mechanism. This design preserves the strengths of existing QE models while calibrating their gender-related biases in a plug-and-play manner. Extensive experiments across multiple gender bias evaluation settings demonstrate that FairQE consistently improves gender fairness over strong QE baselines. Moreover, under MQM-based meta-evaluation following the WMT 2023 Metrics Shared Task, FairQE achieves competitive or improved general QE performance. These results show that gender bias in QE can be effectively mitigated without sacrificing evaluation accuracy, enabling fairer and more reliable translation evaluation.
ParTY: Part-Guidance for Expressive Text-to-Motion Synthesis
Mar 10, 2026Text-to-motion synthesis aims to generate natural and expressive human motions from textual descriptions. While existing approaches primarily focus on generating holistic motions from text descriptions, they struggle to accurately reflect actions involving specific body parts. Recent part-wise motion generation methods attempt to resolve this but face two critical limitations: (i) they lack explicit mechanisms for aligning textual semantics with individual body parts, and (ii) they often generate incoherent full-body motions due to integrating independently generated part motions. To overcome these issues and resolve the fundamental trade-off in existing methods, we propose ParTY, a novel framework that enhances part expressiveness while generating coherent full-body motions. ParTY comprises: (1) Part-Guided Network, which first generates part motions to obtain part guidance, then uses it to generate holistic motions; (2) Part-aware Text Grounding, which diversely transforms text embeddings and appropriately aligns them with each body part; and (3) Holistic-Part Fusion, which adaptively fuses holistic motions and part motions. Extensive experiments, including part-level and coherence-level evaluations, demonstrate that ParTY achieves substantial improvements over previous methods.
Steering LLMs toward Korean Local Speech: Iterative Refinement Framework for Faithful Dialect Translation
Nov 10, 2025Standard-to-dialect machine translation remains challenging due to a persistent dialect gap in large language models and evaluation distortions inherent in n-gram metrics, which favor source copying over authentic dialect translation. In this paper, we propose the dialect refinement (DIA-REFINE) framework, which guides LLMs toward faithful target dialect outputs through an iterative loop of translation, verification, and feedback using external dialect classifiers. To address the limitations of n-gram-based metrics, we introduce the dialect fidelity score (DFS) to quantify linguistic shift and the target dialect ratio (TDR) to measure the success of dialect translation. Experiments on Korean dialects across zero-shot and in-context learning baselines demonstrate that DIA-REFINE consistently enhances dialect fidelity. The proposed metrics distinguish between False Success cases, where high n-gram scores obscure failures in dialectal translation, and True Attempt cases, where genuine attempts at dialectal translation yield low n-gram scores. We also observed that models exhibit varying degrees of responsiveness to the framework, and that integrating in-context examples further improves the translation of dialectal expressions. Our work establishes a robust framework for goal-directed, inclusive dialect translation, providing both rigorous evaluation and critical insights into model performance.
From Ground Trust to Truth: Disparities in Offensive Language Judgments on Contemporary Korean Political Discourse
Sep 18, 2025Although offensive language continually evolves over time, even recent studies using LLMs have predominantly relied on outdated datasets and rarely evaluated the generalization ability on unseen texts. In this study, we constructed a large-scale dataset of contemporary political discourse and employed three refined judgments in the absence of ground truth. Each judgment reflects a representative offensive language detection method and is carefully designed for optimal conditions. We identified distinct patterns for each judgment and demonstrated tendencies of label agreement using a leave-one-out strategy. By establishing pseudo-labels as ground trust for quantitative performance assessment, we observed that a strategically designed single prompting achieves comparable performance to more resource-intensive methods. This suggests a feasible approach applicable in real-world settings with inherent constraints.
Delving into Multilingual Ethical Bias: The MSQAD with Statistical Hypothesis Tests for Large Language Models
May 25, 2025Despite the recent strides in large language models, studies have underscored the existence of social biases within these systems. In this paper, we delve into the validation and comparison of the ethical biases of LLMs concerning globally discussed and potentially sensitive topics, hypothesizing that these biases may arise from language-specific distinctions. Introducing the Multilingual Sensitive Questions & Answers Dataset (MSQAD), we collected news articles from Human Rights Watch covering 17 topics, and generated socially sensitive questions along with corresponding responses in multiple languages. We scrutinized the biases of these responses across languages and topics, employing two statistical hypothesis tests. The results showed that the null hypotheses were rejected in most cases, indicating biases arising from cross-language differences. It demonstrates that ethical biases in responses are widespread across various languages, and notably, these biases were prevalent even among different LLMs. By making the proposed MSQAD openly available, we aim to facilitate future research endeavors focused on examining cross-language biases in LLMs and their variant models.
IM-BERT: Enhancing Robustness of BERT through the Implicit Euler Method
May 11, 2025Pre-trained Language Models (PLMs) have achieved remarkable performance on diverse NLP tasks through pre-training and fine-tuning. However, fine-tuning the model with a large number of parameters on limited downstream datasets often leads to vulnerability to adversarial attacks, causing overfitting of the model on standard datasets. To address these issues, we propose IM-BERT from the perspective of a dynamic system by conceptualizing a layer of BERT as a solution of Ordinary Differential Equations (ODEs). Under the situation of initial value perturbation, we analyze the numerical stability of two main numerical ODE solvers: the explicit and implicit Euler approaches. Based on these analyses, we introduce a numerically robust IM-connection incorporating BERT's layers. This strategy enhances the robustness of PLMs against adversarial attacks, even in low-resource scenarios, without introducing additional parameters or adversarial training strategies. Experimental results on the adversarial GLUE (AdvGLUE) dataset validate the robustness of IM-BERT under various conditions. Compared to the original BERT, IM-BERT exhibits a performance improvement of approximately 8.3\%p on the AdvGLUE dataset. Furthermore, in low-resource scenarios, IM-BERT outperforms BERT by achieving 5.9\%p higher accuracy.
DIAL: Dense Image-text ALignment for Weakly Supervised Semantic Segmentation
Sep 24, 2024
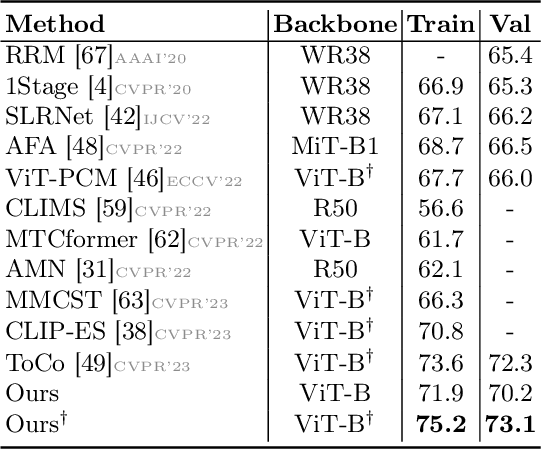
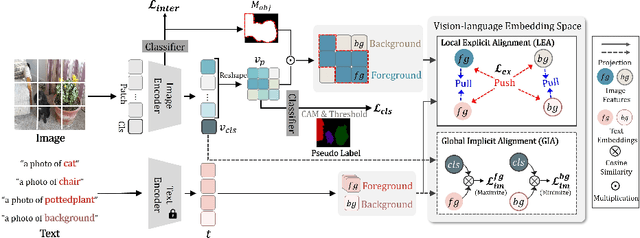
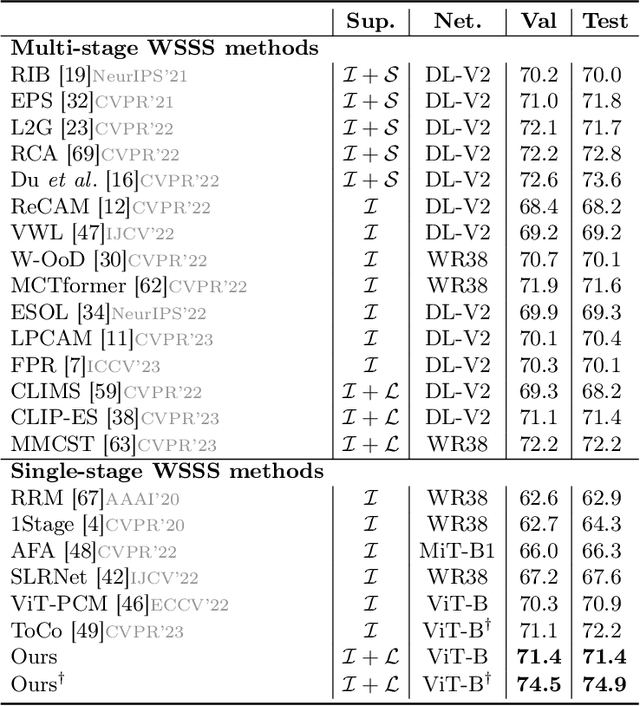
Weakly supervised semantic segmentation (WSSS) approaches typically rely on class activation maps (CAMs) for initial seed generation, which often fail to capture global context due to limited supervision from image-level labels. To address this issue, we introduce DALNet, Dense Alignment Learning Network that leverages text embeddings to enhance the comprehensive understanding and precise localization of objects across different levels of granularity. Our key insight is to employ a dual-level alignment strategy: (1) Global Implicit Alignment (GIA) to capture global semantics by maximizing the similarity between the class token and the corresponding text embeddings while minimizing the similarity with background embeddings, and (2) Local Explicit Alignment (LEA) to improve object localization by utilizing spatial information from patch tokens. Moreover, we propose a cross-contrastive learning approach that aligns foreground features between image and text modalities while separating them from the background, encouraging activation in missing regions and suppressing distractions. Through extensive experiments on the PASCAL VOC and MS COCO datasets, we demonstrate that DALNet significantly outperforms state-of-the-art WSSS methods. Our approach, in particular, allows for more efficient end-to-end process as a single-stage method.
Focus on the Core: Efficient Attention via Pruned Token Compression for Document Classification
Jun 03, 2024Transformer-based models have achieved dominant performance in numerous NLP tasks. Despite their remarkable successes, pre-trained transformers such as BERT suffer from a computationally expensive self-attention mechanism that interacts with all tokens, including the ones unfavorable to classification performance. To overcome these challenges, we propose integrating two strategies: token pruning and token combining. Token pruning eliminates less important tokens in the attention mechanism's key and value as they pass through the layers. Additionally, we adopt fuzzy logic to handle uncertainty and alleviate potential mispruning risks arising from an imbalanced distribution of each token's importance. Token combining, on the other hand, condenses input sequences into smaller sizes in order to further compress the model. By integrating these two approaches, we not only improve the model's performance but also reduce its computational demands. Experiments with various datasets demonstrate superior performance compared to baseline models, especially with the best improvement over the existing BERT model, achieving +5%p in accuracy and +5.6%p in F1 score. Additionally, memory cost is reduced to 0.61x, and a speedup of 1.64x is achieved.
Enhancing Effectiveness and Robustness in a Low-Resource Regime via Decision-Boundary-aware Data Augmentation
Mar 22, 2024Efforts to leverage deep learning models in low-resource regimes have led to numerous augmentation studies. However, the direct application of methods such as mixup and cutout to text data, is limited due to their discrete characteristics. While methods using pretrained language models have exhibited efficiency, they require additional considerations for robustness. Inspired by recent studies on decision boundaries, this paper proposes a decision-boundary-aware data augmentation strategy to enhance robustness using pretrained language models. The proposed technique first focuses on shifting the latent features closer to the decision boundary, followed by reconstruction to generate an ambiguous version with a soft label. Additionally, mid-K sampling is suggested to enhance the diversity of the generated sentences. This paper demonstrates the performance of the proposed augmentation strategy compared to other methods through extensive experiments. Furthermore, the ablation study reveals the effect of soft labels and mid-K sampling and the extensibility of the method with curriculum data augmentation.
Don't be a Fool: Pooling Strategies in Offensive Language Detection from User-Intended Adversarial Attacks
Mar 20, 2024


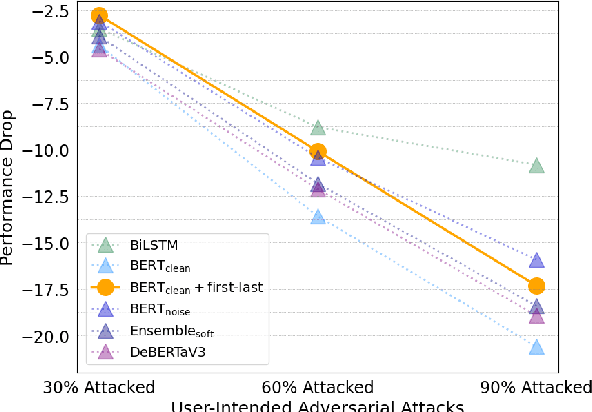
Offensive language detection is an important task for filtering out abusive expressions and improving online user experiences. However, malicious users often attempt to avoid filtering systems through the involvement of textual noises. In this paper, we propose these evasions as user-intended adversarial attacks that insert special symbols or leverage the distinctive features of the Korean language. Furthermore, we introduce simple yet effective pooling strategies in a layer-wise manner to defend against the proposed attacks, focusing on the preceding layers not just the last layer to capture both offensiveness and token embeddings. We demonstrate that these pooling strategies are more robust to performance degradation even when the attack rate is increased, without directly training of such patterns. Notably, we found that models pre-trained on clean texts could achieve a comparable performance in detecting attacked offensive language, to models pre-trained on noisy texts by employing these pooling strategies.