 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEART: Coordination of Heterogeneous Expert Agents for Physically Grounded Robotic Task Planning
Jun 24, 2026Large Language Models (LLMs) can reason over complex instructions but often fail to satisfy the physical and spatial constraints required for robotic task planning. Recent LLM-based planners directly translate text into action sequences, yet they lack structured reasoning about feasibility, reachability, and logical order, resulting in invalid or incomplete plans. We present a heterogeneous multi-LLM framework that decomposes instructions into atomic reasoning tasks and allocates them to role-specialized expert agents under a token budget for real-world computational and communicational constraints. By combining role-oriented reasoning from heterogeneous agents followed by constraint-driven plan synthesis, HEART validates capability, reachability, and constraint conditions before planning and helps produce physically executable plans while maintaining efficiency. Experiments across different household benchmarks show that HEART consistently improves plan success compared to single-LLM and rule-based planners, demonstrating that heterogeneous LLM collaboration enables robust and scalable robotic task planning under resource constraints.
Geometry-Aware Image Flow Matching
May 24, 2026Recent advances in generative models highlight the power of geometry-aware modeling in manifold-constrained settings. Yet, for natural images, the field remains confined to Euclidean assumptions, failing to exploit the potential of intrinsic geometric structures within the data. In this work, we investigate the geometry of natural images and observe that semantic information is predominantly encoded in directional components, while norm components can be approximated by the global average. This property holds across both RGB and latent spaces, suggesting that natural images can be effectively modeled on a hypersphere. Building on this finding, we introduce Spherical Optimal Transport Flow Matching (SOT-CFM), which utilizes angular distance, and Spherical Flow Matching (SFM), which constrains dynamics directly on the manifold. Our experiments demonstrate that these geometry-aware methods achieve superior performance against Euclidean baselines. Ultimately, this work provides a novel perspective that bridges the gap between Riemannian manifold-based modeling and natural image generation.
Is There a Better Source Distribution than Gaussian? Exploring Source Distributions for Image Flow Matching
Dec 20, 2025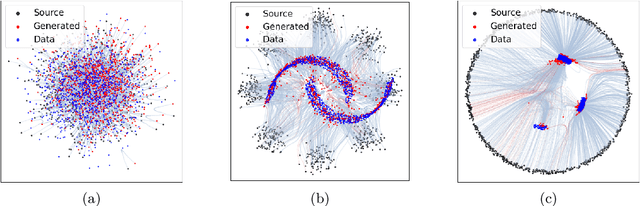

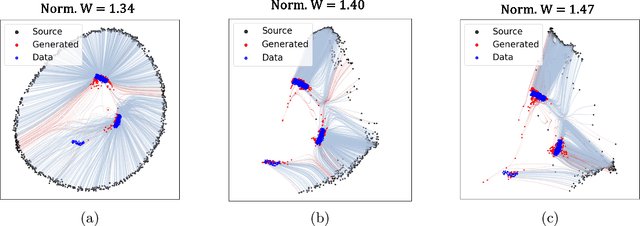

Flow matching has emerged as a powerful generative modeling approach with flexible choices of source distribution. While Gaussian distributions are commonly used, the potential for better alternatives in high-dimensional data generation remains largely unexplored. In this paper, we propose a novel 2D simulation that captures high-dimensional geometric properties in an interpretable 2D setting, enabling us to analyze the learning dynamics of flow matching during training. Based on this analysis, we derive several key insights about flow matching behavior: (1) density approximation can paradoxically degrade performance due to mode discrepancy, (2) directional alignment suffers from path entanglement when overly concentrated, (3) Gaussian's omnidirectional coverage ensures robust learning, and (4) norm misalignment incurs substantial learning costs. Building on these insights, we propose a practical framework that combines norm-aligned training with directionally-pruned sampling. This approach maintains the robust omnidirectional supervision essential for stable flow learning, while eliminating initializations in data-sparse regions during inference. Importantly, our pruning strategy can be applied to any flow matching model trained with a Gaussian source, providing immediate performance gains without the need for retraining. Empirical evaluations demonstrate consistent improvements in both generation quality and sampling efficiency. Our findings provide practical insights and guidelines for source distribution design and introduce a readily applicable technique for improving existing flow matching models. Our code is available at https://github.com/kwanseokk/SourceFM.
Finding NeMo: Negative-mined Mosaic Augmentation for Referring Image Segmentation
Nov 03, 2024



Referring Image Segmentation is a comprehensive task to segment an object referred by a textual query from an image. In nature, the level of difficulty in this task is affected by the existence of similar objects and the complexity of the referring expression. Recent RIS models still show a significant performance gap between easy and hard scenarios. We pose that the bottleneck exists in the data, and propose a simple but powerful data augmentation method, Negative-mined Mosaic Augmentation (NeMo). This method augments a training image into a mosaic with three other negative images carefully curated by a pretrained multimodal alignment model, e.g., CLIP, to make the sample more challenging. We discover that it is critical to properly adjust the difficulty level, neither too ambiguous nor too trivial. The augmented training data encourages the RIS model to recognize subtle differences and relationships between similar visual entities and to concretely understand the whole expression to locate the right target better. Our approach shows consistent improvements on various datasets and models, verified by extensive experiments.
Scalable Frame Sampling for Video Classification: A Semi-Optimal Policy Approach with Reduced Search Space
Sep 09, 2024Given a video with $T$ frames, frame sampling is a task to select $N \ll T$ frames, so as to maximize the performance of a fixed video classifier. Not just brute-force search, but most existing methods suffer from its vast search space of $\binom{T}{N}$, especially when $N$ gets large. To address this challenge, we introduce a novel perspective of reducing the search space from $O(T^N)$ to $O(T)$. Instead of exploring the entire $O(T^N)$ space, our proposed semi-optimal policy selects the top $N$ frames based on the independently estimated value of each frame using per-frame confidence, significantly reducing the computational complexity. We verify that our semi-optimal policy can efficiently approximate the optimal policy, particularly under practical settings. Additionally, through extensive experiments on various datasets and model architectures, we demonstrate that learning our semi-optimal policy ensures stable and high performance regardless of the size of $N$ and $T$.
Isometric Representation Learning for Disentangled Latent Space of Diffusion Models
Jul 16, 2024The latent space of diffusion model mostly still remains unexplored, despite its great success and potential in the field of generative modeling. In fact, the latent space of existing diffusion models are entangled, with a distorted mapping from its latent space to image space. To tackle this problem, we present Isometric Diffusion, equipping a diffusion model with a geometric regularizer to guide the model to learn a geometrically sound latent space of the training data manifold. This approach allows diffusion models to learn a more disentangled latent space, which enables smoother interpolation, more accurate inversion, and more precise control over attributes directly in the latent space. Our extensive experiments consisting of image interpolations, image inversions, and linear editing show the effectiveness of our method.
Semi-Supervised Domain Adaptation Using Target-Oriented Domain Augmentation for 3D Object Detection
Jun 17, 2024



3D object detection is crucial for applications like autonomous driving and robotics. However, in real-world environments, variations in sensor data distribution due to sensor upgrades, weather changes, and geographic differences can adversely affect detection performance. Semi-Supervised Domain Adaptation (SSDA) aims to mitigate these challenges by transferring knowledge from a source domain, abundant in labeled data, to a target domain where labels are scarce. This paper presents a new SSDA method referred to as Target-Oriented Domain Augmentation (TODA) specifically tailored for LiDAR-based 3D object detection. TODA efficiently utilizes all available data, including labeled data in the source domain, and both labeled data and unlabeled data in the target domain to enhance domain adaptation performance. TODA consists of two stages: TargetMix and AdvMix. TargetMix employs mixing augmentation accounting for LiDAR sensor characteristics to facilitate feature alignment between the source-domain and target-domain. AdvMix applies point-wise adversarial augmentation with mixing augmentation, which perturbs the unlabeled data to align the features within both labeled and unlabeled data in the target domain. Our experiments conducted on the challenging domain adaptation tasks demonstrate that TODA outperforms existing domain adaptation techniques designed for 3D object detection by significant margins. The code is available at: https://github.com/rasd3/TODA.
Enhancing Effectiveness and Robustness in a Low-Resource Regime via Decision-Boundary-aware Data Augmentation
Mar 22, 2024Efforts to leverage deep learning models in low-resource regimes have led to numerous augmentation studies. However, the direct application of methods such as mixup and cutout to text data, is limited due to their discrete characteristics. While methods using pretrained language models have exhibited efficiency, they require additional considerations for robustness. Inspired by recent studies on decision boundaries, this paper proposes a decision-boundary-aware data augmentation strategy to enhance robustness using pretrained language models. The proposed technique first focuses on shifting the latent features closer to the decision boundary, followed by reconstruction to generate an ambiguous version with a soft label. Additionally, mid-K sampling is suggested to enhance the diversity of the generated sentences. This paper demonstrates the performance of the proposed augmentation strategy compared to other methods through extensive experiments. Furthermore, the ablation study reveals the effect of soft labels and mid-K sampling and the extensibility of the method with curriculum data augmentation.
SoftEDA: Rethinking Rule-Based Data Augmentation with Soft Labels
Feb 08, 2024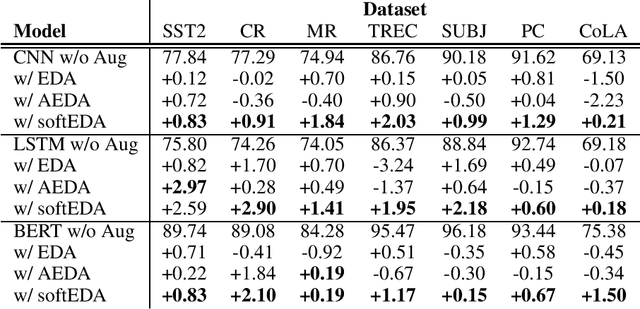
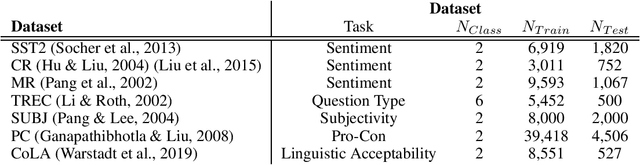
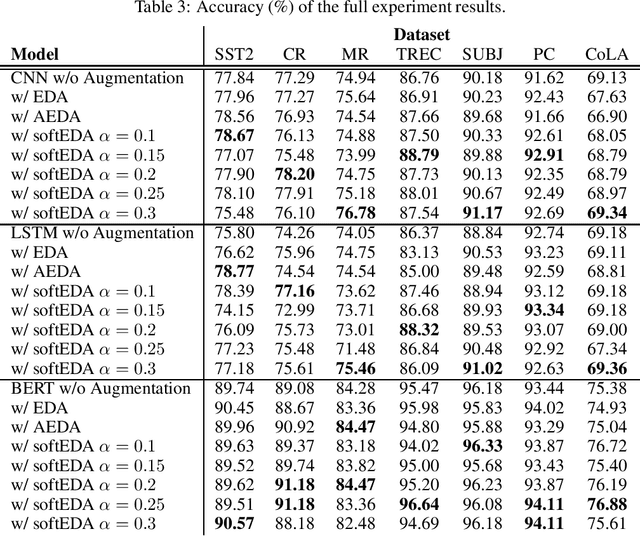
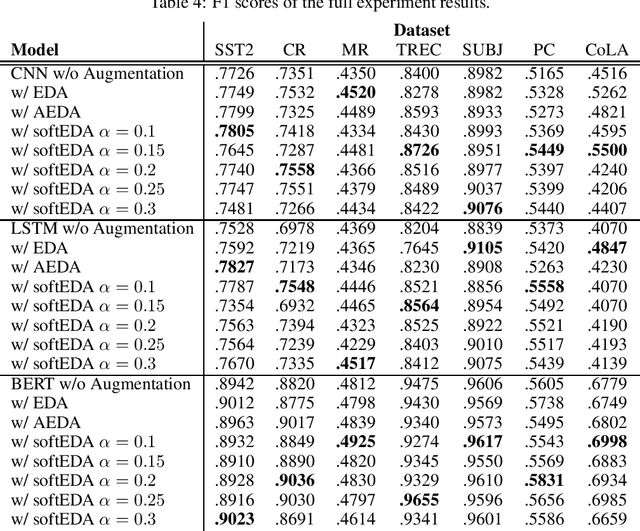
Rule-based text data augmentation is widely used for NLP tasks due to its simplicity. However, this method can potentially damage the original meaning of the text, ultimately hurting the performance of the model. To overcome this limitation, we propose a straightforward technique for applying soft labels to augmented data. We conducted experiments across seven different classification tasks and empirically demonstrated the effectiveness of our proposed approach. We have publicly opened our source code for reproducibility.
AutoAugment Is What You Need: Enhancing Rule-based Augmentation Methods in Low-resource Regimes
Feb 08, 2024


Text data augmentation is a complex problem due to the discrete nature of sentences. Although rule-based augmentation methods are widely adopted in real-world applications because of their simplicity, they suffer from potential semantic damage. Previous researchers have suggested easy data augmentation with soft labels (softEDA), employing label smoothing to mitigate this problem. However, finding the best factor for each model and dataset is challenging; therefore, using softEDA in real-world applications is still difficult. In this paper, we propose adapting AutoAugment to solve this problem. The experimental results suggest that the proposed method can boost existing augmentation methods and that rule-based methods can enhance cutting-edge pre-trained language models. We offer the source code.