 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiSPA: Differential Substructure-Pathway Attention for Drug Response Prediction
Jan 20, 2026Accurate prediction of drug response in precision medicine requires models that capture how specific chemical substructures interact with cellular pathway states. However, most existing deep learning approaches treat chemical and transcriptomic modalities independently or combine them only at late stages, limiting their ability to model fine-grained, context-dependent mechanisms of drug action. In addition, standard attention mechanisms are often sensitive to noise and sparsity in high-dimensional biological networks, hindering both generalization and interpretability. We present DiSPA, a representation learning framework that explicitly disentangles structure-driven and context-driven mechanisms of drug response through bidirectional conditioning between chemical substructures and pathway-level gene expression. DiSPA introduces a differential cross-attention module that suppresses spurious pathway-substructure associations while amplifying contextually relevant interactions. Across multiple evaluation settings on the GDSC benchmark, DiSPA achieves state-of-the-art performance, with particularly strong improvements in the disjoint-set setting, which assesses generalization to unseen drug-cell combinations. Beyond predictive accuracy, DiSPA yields mechanistically informative representations: learned attention patterns recover known pharmacophores, distinguish structure-driven from context-dependent compounds, and exhibit coherent organization across biological pathways. Furthermore, we demonstrate that DiSPA trained solely on bulk RNA-seq data enables zero-shot transfer to spatial transcriptomics, revealing region-specific drug sensitivity patterns without retraining. Together, these results establish DiSPA as a robust and interpretable framework for integrative pharmacogenomic modeling, enabling principled analysis of drug response mechanisms beyond post hoc interpretation.
MARBLE: Multi-Agent Reasoning for Bioinformatics Learning and Evolution
Jan 20, 2026Motivation: Developing high-performing bioinformatics models typically requires repeated cycles of hypothesis formulation, architectural redesign, and empirical validation, making progress slow, labor-intensive, and difficult to reproduce. Although recent LLM-based assistants can automate isolated steps, they lack performance-grounded reasoning and stability-aware mechanisms required for reliable, iterative model improvement in bioinformatics workflows. Results: We introduce MARBLE, an execution-stable autonomous model refinement framework for bioinformatics models. MARBLE couples literature-aware reference selection with structured, debate-driven architectural reasoning among role-specialized agents, followed by autonomous execution, evaluation, and memory updates explicitly grounded in empirical performance. Across spatial transcriptomics domain segmentation, drug-target interaction prediction, and drug response prediction, MARBLE consistently achieves sustained performance improvements over strong baselines across multiple refinement cycles, while maintaining high execution robustness and low regression rates. Framework-level analyses demonstrate that structured debate, balanced evidence selection, and performance-grounded memory are critical for stable, repeatable model evolution, rather than single-run or brittle gains. Availability: Source code, data and Supplementary Information are available at https://github.com/PRISM-DGU/MARBLE.
Isometric Representation Learning for Disentangled Latent Space of Diffusion Models
Jul 16, 2024The latent space of diffusion model mostly still remains unexplored, despite its great success and potential in the field of generative modeling. In fact, the latent space of existing diffusion models are entangled, with a distorted mapping from its latent space to image space. To tackle this problem, we present Isometric Diffusion, equipping a diffusion model with a geometric regularizer to guide the model to learn a geometrically sound latent space of the training data manifold. This approach allows diffusion models to learn a more disentangled latent space, which enables smoother interpolation, more accurate inversion, and more precise control over attributes directly in the latent space. Our extensive experiments consisting of image interpolations, image inversions, and linear editing show the effectiveness of our method.
GraphPipe: Improving Performance and Scalability of DNN Training with Graph Pipeline Parallelism
Jun 24, 2024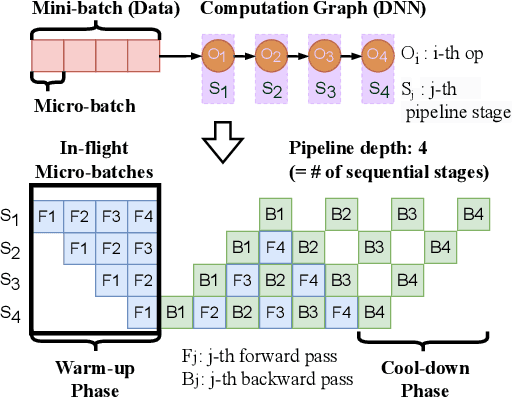

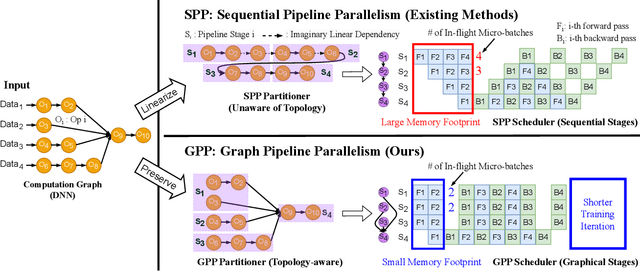
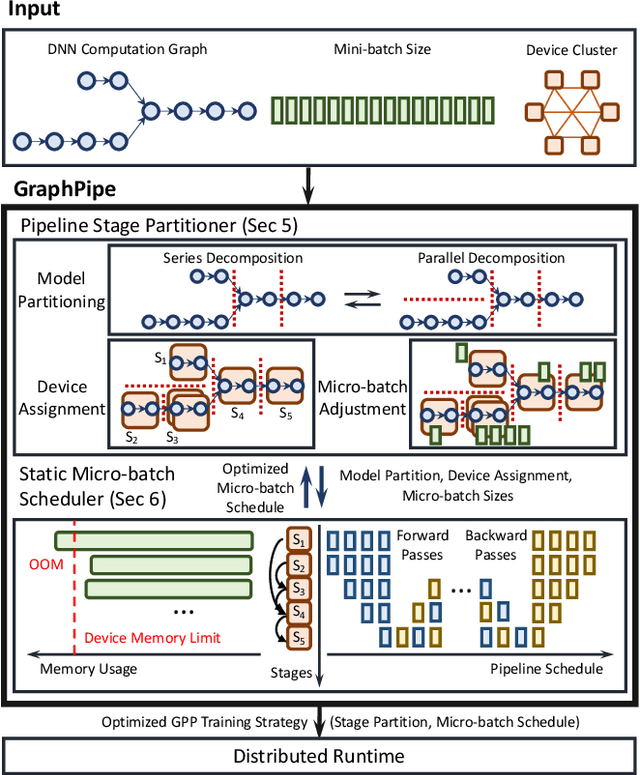
Deep neural networks (DNNs) continue to grow rapidly in size, making them infeasible to train on a single device. Pipeline parallelism is commonly used in existing DNN systems to support large-scale DNN training by partitioning a DNN into multiple stages, which concurrently perform DNN training for different micro-batches in a pipeline fashion. However, existing pipeline-parallel approaches only consider sequential pipeline stages and thus ignore the topology of a DNN, resulting in missed model-parallel opportunities. This paper presents graph pipeline parallelism (GPP), a new pipeline-parallel scheme that partitions a DNN into pipeline stages whose dependencies are identified by a directed acyclic graph. GPP generalizes existing sequential pipeline parallelism and preserves the inherent topology of a DNN to enable concurrent execution of computationally-independent operators, resulting in reduced memory requirement and improved GPU performance. In addition, we develop GraphPipe, a distributed system that exploits GPP strategies to enable performant and scalable DNN training. GraphPipe partitions a DNN into a graph of stages, optimizes micro-batch schedules for these stages, and parallelizes DNN training using the discovered GPP strategies. Evaluation on a variety of DNNs shows that GraphPipe outperforms existing pipeline-parallel systems such as PipeDream and Piper by up to 1.6X. GraphPipe also reduces the search time by 9-21X compared to PipeDream and Piper.
Efficient Strong Scaling Through Burst Parallel Training
Dec 19, 2021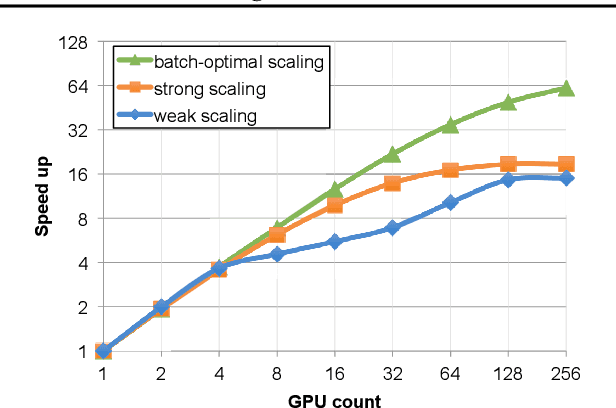
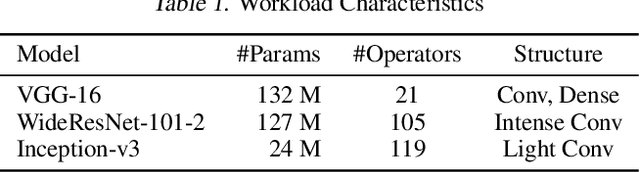
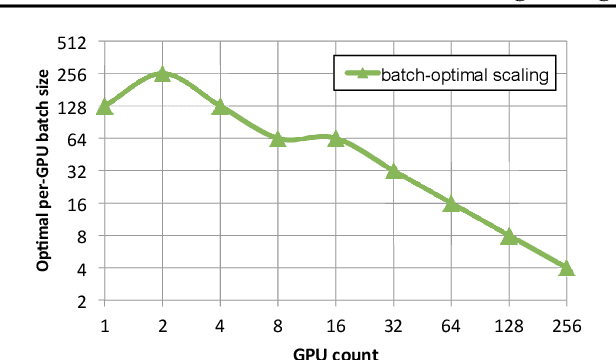

As emerging deep neural network (DNN) models continue to grow in size, using large GPU clusters to train DNNs is becoming an essential requirement to achieving acceptable training times. In this paper, we consider the case where future increases in cluster size will cause the global batch size that can be used to train models to reach a fundamental limit: beyond a certain point, larger global batch sizes cause sample efficiency to degrade, increasing overall time to accuracy. As a result, to achieve further improvements in training performance, we must instead consider "strong scaling" strategies that hold the global batch size constant and allocate smaller batches to each GPU. Unfortunately, this makes it significantly more difficult to use cluster resources efficiently. We present DeepPool, a system that addresses this efficiency challenge through two key ideas. First, burst parallelism allocates large numbers of GPUs to foreground jobs in bursts to exploit the unevenness in parallelism across layers. Second, GPU multiplexing prioritizes throughput for foreground training jobs, while packing in background training jobs to reclaim underutilized GPU resources, thereby improving cluster-wide utilization. Together, these two ideas enable DeepPool to deliver a 2.2 - 2.4x improvement in total cluster throughput over standard data parallelism with a single task when the cluster scale is large.
Top-$K$ Ranking from Pairwise Comparisons: When Spectral Ranking is Optimal
Mar 14, 2016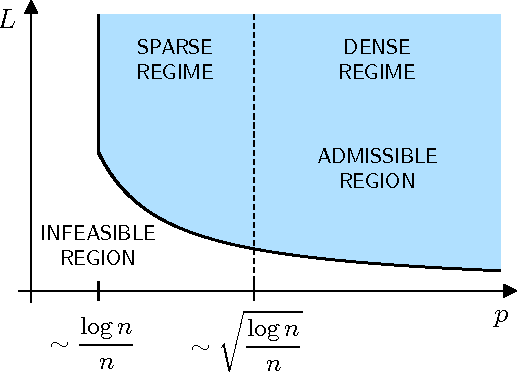
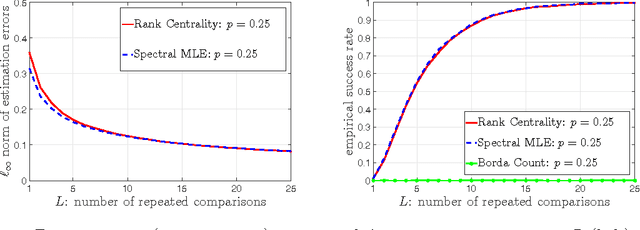
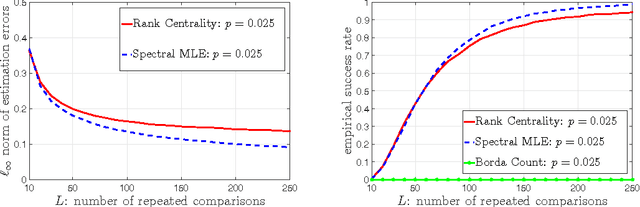
We explore the top-$K$ rank aggregation problem. Suppose a collection of items is compared in pairs repeatedly, and we aim to recover a consistent ordering that focuses on the top-$K$ ranked items based on partially revealed preference information. We investigate the Bradley-Terry-Luce model in which one ranks items according to their perceived utilities modeled as noisy observations of their underlying true utilities. Our main contributions are two-fold. First, in a general comparison model where item pairs to compare are given a priori, we attain an upper and lower bound on the sample size for reliable recovery of the top-$K$ ranked items. Second, more importantly, extending the result to a random comparison model where item pairs to compare are chosen independently with some probability, we show that in slightly restricted regimes, the gap between the derived bounds reduces to a constant factor, hence reveals that a spectral method can achieve the minimax optimality on the (order-wise) sample size required for top-$K$ ranking. That is to say, we demonstrate a spectral method alone to be sufficient to achieve the optimality and advantageous in terms of computational complexity, as it does not require an additional stage of maximum likelihood estimation that a state-of-the-art scheme employs to achieve the optimality. We corroborate our main results by numerical experiments.