 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivasis: Synthesizing the Largest "Public" Private Dataset from Scratch
Feb 03, 2026Research involving privacy-sensitive data has always been constrained by data scarcity, standing in sharp contrast to other areas that have benefited from data scaling. This challenge is becoming increasingly urgent as modern AI agents--such as OpenClaw and Gemini Agent--are granted persistent access to highly sensitive personal information. To tackle this longstanding bottleneck and the rising risks, we present Privasis (i.e., privacy oasis), the first million-scale fully synthetic dataset entirely built from scratch--an expansive reservoir of texts with rich and diverse private information--designed to broaden and accelerate research in areas where processing sensitive social data is inevitable. Compared to existing datasets, Privasis, comprising 1.4 million records, offers orders-of-magnitude larger scale with quality, and far greater diversity across various document types, including medical history, legal documents, financial records, calendars, and text messages with a total of 55.1 million annotated attributes such as ethnicity, date of birth, workplace, etc. We leverage Privasis to construct a parallel corpus for text sanitization with our pipeline that decomposes texts and applies targeted sanitization. Our compact sanitization models (<=4B) trained on this dataset outperform state-of-the-art large language models, such as GPT-5 and Qwen-3 235B. We plan to release data, models, and code to accelerate future research on privacy-sensitive domains and agents.
ROMA: Recursive Open Meta-Agent Framework for Long-Horizon Multi-Agent Systems
Feb 02, 2026Current agentic frameworks underperform on long-horizon tasks. As reasoning depth increases, sequential orchestration becomes brittle, context windows impose hard limits that degrade performance, and opaque execution traces make failures difficult to localize or debug. We introduce ROMA (Recursive Open Meta-Agents), a domain-agnostic framework that addresses these limitations through recursive task decomposition and structured aggregation. ROMA decomposes goals into dependency-aware subtask trees that can be executed in parallel, while aggregation compresses and validates intermediate results to control context growth. Our framework standardizes agent construction around four modular roles --Atomizer (which decides whether a task should be decomposed), Planner, Executor, and Aggregator -- which cleanly separate orchestration from model selection and enable transparent, hierarchical execution traces. This design supports heterogeneous multi-agent systems that mix models and tools according to cost, latency, and capability. To adapt ROMA to specific tasks without fine-tuning, we further introduce GEPA$+$, an improved Genetic-Pareto prompt proposer that searches over prompts within ROMA's component hierarchy while preserving interface contracts. We show that ROMA, combined with GEPA+, delivers leading system-level performance on reasoning and long-form generation benchmarks. On SEAL-0, which evaluates reasoning over conflicting web evidence, ROMA instantiated with GLM-4.6 improves accuracy by 9.9\% over Kimi-Researcher. On EQ-Bench, a long-form writing benchmark, ROMA enables DeepSeek-V3 to match the performance of leading closed-source models such as Claude Sonnet 4.5. Our results demonstrate that recursive, modular agent architectures can scale reasoning depth while remaining interpretable, flexible, and model-agnostic.
Understanding the Gain from Data Filtering in Multimodal Contrastive Learning
Dec 16, 2025



The success of modern multimodal representation learning relies on internet-scale datasets. Due to the low quality of a large fraction of raw web data, data curation has become a critical step in the training pipeline. Filtering using a trained model (i.e., teacher-based filtering) has emerged as a successful solution, leveraging a pre-trained model to compute quality scores. To explain the empirical success of teacher-based filtering, we characterize the performance of filtered contrastive learning under the standard bimodal data generation model. Denoting $η\in(0,1]$ as the fraction of data with correctly matched modalities among $n$ paired samples, we utilize a linear contrastive learning setup to show a provable benefit of data filtering: $(i)$ the error without filtering is upper and lower bounded by $\frac{1}{η\sqrt{n}}$, and $(ii)$ the error with teacher-based filtering is upper bounded by $\frac{1}{\sqrt{ηn}}$ in the large $η$ regime, and by $\frac{1}{\sqrt{n}}$ in the small $η$ regime.
Are Robust LLM Fingerprints Adversarially Robust?
Sep 30, 2025Model fingerprinting has emerged as a promising paradigm for claiming model ownership. However, robustness evaluations of these schemes have mostly focused on benign perturbations such as incremental fine-tuning, model merging, and prompting. Lack of systematic investigations into {\em adversarial robustness} against a malicious model host leaves current systems vulnerable. To bridge this gap, we first define a concrete, practical threat model against model fingerprinting. We then take a critical look at existing model fingerprinting schemes to identify their fundamental vulnerabilities. Based on these, we develop adaptive adversarial attacks tailored for each vulnerability, and demonstrate that these can bypass model authentication completely for ten recently proposed fingerprinting schemes while maintaining high utility of the model for the end users. Our work encourages fingerprint designers to adopt adversarial robustness by design. We end with recommendations for future fingerprinting methods.
Sampling from Your Language Model One Byte at a Time
Jun 17, 2025Tokenization is used almost universally by modern language models, enabling efficient text representation using multi-byte or multi-character tokens. However, prior work has shown that tokenization can introduce distortion into the model's generations. For example, users are often advised not to end their prompts with a space because it prevents the model from including the space as part of the next token. This Prompt Boundary Problem (PBP) also arises in languages such as Chinese and in code generation, where tokens often do not line up with syntactic boundaries. Additionally mismatching tokenizers often hinder model composition and interoperability. For example, it is not possible to directly ensemble models with different tokenizers due to their mismatching vocabularies. To address these issues, we present an inference-time method to convert any autoregressive LM with a BPE tokenizer into a character-level or byte-level LM, without changing its generative distribution at the text level. Our method efficient solves the PBP and is also able to unify the vocabularies of language models with different tokenizers, allowing one to ensemble LMs with different tokenizers at inference time as well as transfer the post-training from one model to another using proxy-tuning. We demonstrate in experiments that the ensemble and proxy-tuned models outperform their constituents on downstream evals.
Spurious Rewards: Rethinking Training Signals in RLVR
Jun 12, 2025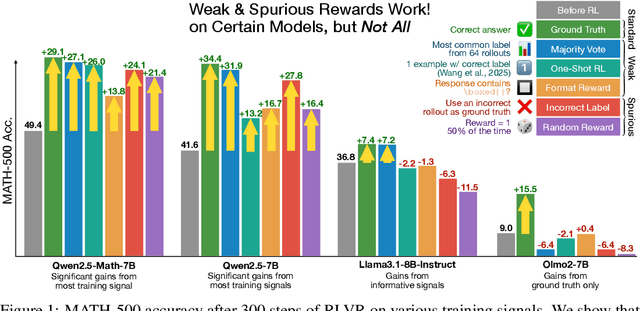
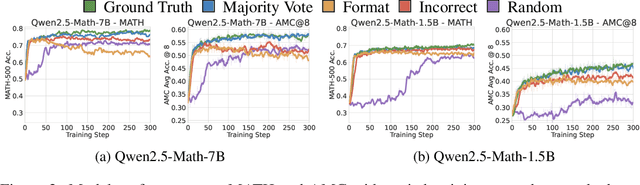
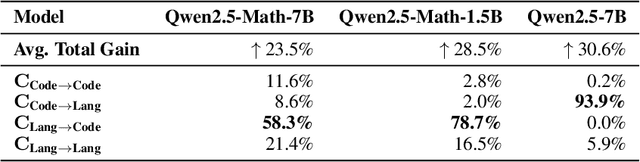
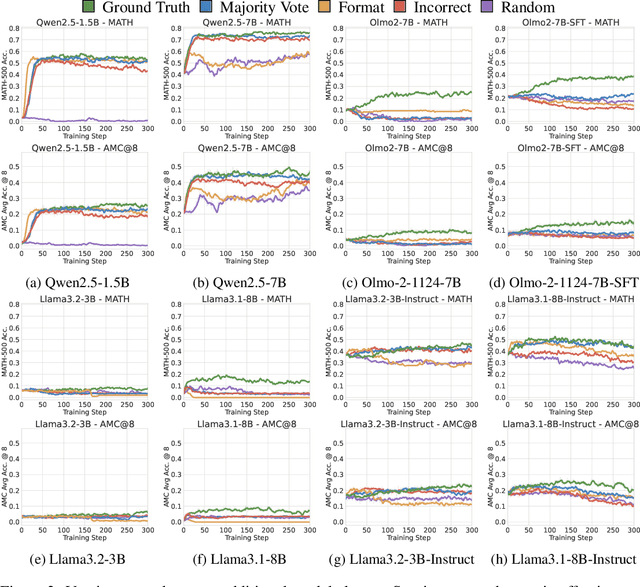
We show that reinforcement learning with verifiable rewards (RLVR) can elicit strong mathematical reasoning in certain models even with spurious rewards that have little, no, or even negative correlation with the correct answer. For example, RLVR improves MATH-500 performance for Qwen2.5-Math-7B in absolute points by 21.4% (random reward), 13.8% (format reward), 24.1% (incorrect label), 26.0% (1-shot RL), and 27.1% (majority voting) -- nearly matching the 29.1% gained with ground truth rewards. However, the spurious rewards that work for Qwen often fail to yield gains with other model families like Llama3 or OLMo2. In particular, we find code reasoning -- thinking in code without actual code execution -- to be a distinctive Qwen2.5-Math behavior that becomes significantly more frequent after RLVR, from 65% to over 90%, even with spurious rewards. Overall, we hypothesize that, given the lack of useful reward signal, RLVR must somehow be surfacing useful reasoning representations learned during pretraining, although the exact mechanism remains a topic for future work. We suggest that future RLVR research should possibly be validated on diverse models rather than a single de facto choice, as we show that it is easy to get significant performance gains on Qwen models even with completely spurious reward signals.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Zeroth-Order Optimization Finds Flat Minima
Jun 05, 2025Zeroth-order methods are extensively used in machine learning applications where gradients are infeasible or expensive to compute, such as black-box attacks, reinforcement learning, and language model fine-tuning. Existing optimization theory focuses on convergence to an arbitrary stationary point, but less is known on the implicit regularization that provides a fine-grained characterization on which particular solutions are finally reached. We show that zeroth-order optimization with the standard two-point estimator favors solutions with small trace of Hessian, which is widely used in previous work to distinguish between sharp and flat minima. We further provide convergence rates of zeroth-order optimization to approximate flat minima for convex and sufficiently smooth functions, where flat minima are defined as the minimizers that achieve the smallest trace of Hessian among all optimal solutions. Experiments on binary classification tasks with convex losses and language model fine-tuning support our theoretical findings.
Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models
Jun 05, 2025Scaling laws predict that the performance of large language models improves with increasing model size and data size. In practice, pre-training has been relying on massive web crawls, using almost all data sources publicly available on the internet so far. However, this pool of natural data does not grow at the same rate as the compute supply. Furthermore, the availability of high-quality texts is even more limited: data filtering pipelines often remove up to 99% of the initial web scrapes to achieve state-of-the-art. To address the "data wall" of pre-training scaling, our work explores ways to transform and recycle data discarded in existing filtering processes. We propose REWIRE, REcycling the Web with guIded REwrite, a method to enrich low-quality documents so that they could become useful for training. This in turn allows us to increase the representation of synthetic data in the final pre-training set. Experiments at 1B, 3B and 7B scales of the DCLM benchmark show that mixing high-quality raw texts and our rewritten texts lead to 1.0, 1.3 and 2.5 percentage points improvement respectively across 22 diverse tasks, compared to training on only filtered web data. Training on the raw-synthetic data mix is also more effective than having access to 2x web data. Through further analysis, we demonstrate that about 82% of the mixed in texts come from transforming lower-quality documents that would otherwise be discarded. REWIRE also outperforms related approaches of generating synthetic data, including Wikipedia-style paraphrasing, question-answer synthesizing and knowledge extraction. These results suggest that recycling web texts holds the potential for being a simple and effective approach for scaling pre-training data.
Foundation model for mass spectrometry proteomics
May 19, 2025Mass spectrometry is the dominant technology in the field of proteomics, enabling high-throughput analysis of the protein content of complex biological samples. Due to the complexity of the instrumentation and resulting data, sophisticated computational methods are required for the processing and interpretation of acquired mass spectra. Machine learning has shown great promise to improve the analysis of mass spectrometry data, with numerous purpose-built methods for improving specific steps in the data acquisition and analysis pipeline reaching widespread adoption. Here, we propose unifying various spectrum prediction tasks under a single foundation model for mass spectra. To this end, we pre-train a spectrum encoder using de novo sequencing as a pre-training task. We then show that using these pre-trained spectrum representations improves our performance on the four downstream tasks of spectrum quality prediction, chimericity prediction, phosphorylation prediction, and glycosylation status prediction. Finally, we perform multi-task fine-tuning and find that this approach improves the performance on each task individually. Overall, our work demonstrates that a foundation model for tandem mass spectrometry proteomics trained on de novo sequencing learns generalizable representations of spectra, improves performance on downstream tasks where training data is limited, and can ultimately enhance data acquisition and analysis in proteomics experiments.