 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Gains from Repeated Self-Distillation
Paper and Code
Jul 05, 2024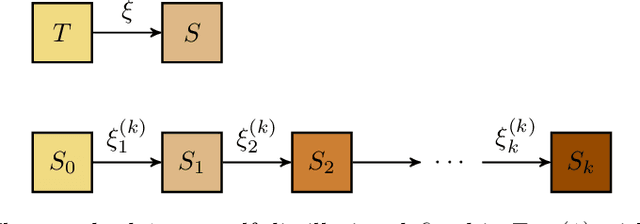
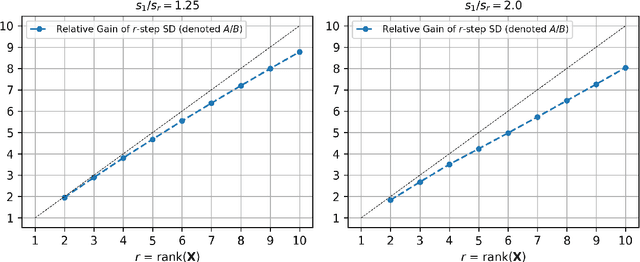
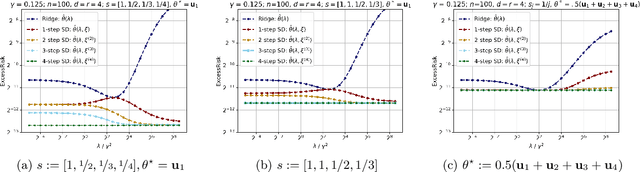
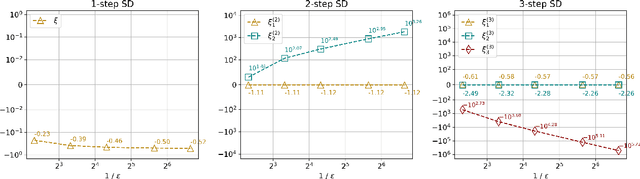
Self-Distillation is a special type of knowledge distillation where the student model has the same architecture as the teacher model. Despite using the same architecture and the same training data, self-distillation has been empirically observed to improve performance, especially when applied repeatedly. For such a process, there is a fundamental question of interest: How much gain is possible by applying multiple steps of self-distillation? To investigate this relative gain, we propose studying the simple but canonical task of linear regression. Our analysis shows that the excess risk achieved by multi-step self-distillation can significantly improve upon a single step of self-distillation, reducing the excess risk by a factor as large as $d$, where $d$ is the input dimension. Empirical results on regression tasks from the UCI repository show a reduction in the learnt model's risk (MSE) by up to 47%.