 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Gain from Data Filtering in Multimodal Contrastive Learning
Dec 16, 2025



The success of modern multimodal representation learning relies on internet-scale datasets. Due to the low quality of a large fraction of raw web data, data curation has become a critical step in the training pipeline. Filtering using a trained model (i.e., teacher-based filtering) has emerged as a successful solution, leveraging a pre-trained model to compute quality scores. To explain the empirical success of teacher-based filtering, we characterize the performance of filtered contrastive learning under the standard bimodal data generation model. Denoting $η\in(0,1]$ as the fraction of data with correctly matched modalities among $n$ paired samples, we utilize a linear contrastive learning setup to show a provable benefit of data filtering: $(i)$ the error without filtering is upper and lower bounded by $\frac{1}{η\sqrt{n}}$, and $(ii)$ the error with teacher-based filtering is upper bounded by $\frac{1}{\sqrt{ηn}}$ in the large $η$ regime, and by $\frac{1}{\sqrt{n}}$ in the small $η$ regime.
Understanding the Gains from Repeated Self-Distillation
Jul 05, 2024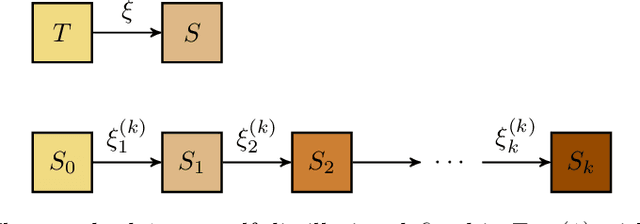
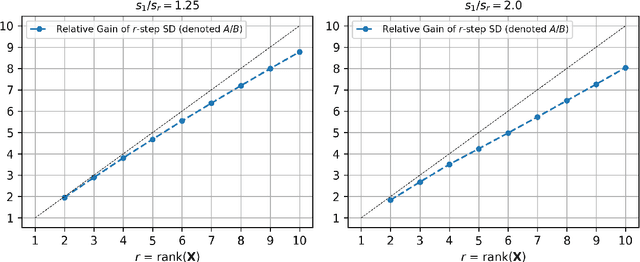
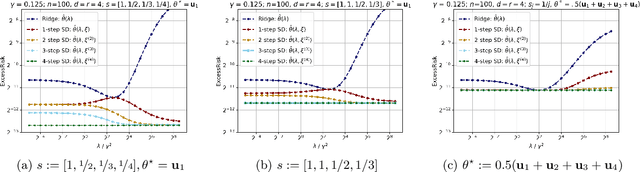
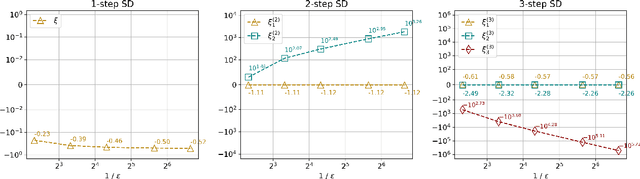
Self-Distillation is a special type of knowledge distillation where the student model has the same architecture as the teacher model. Despite using the same architecture and the same training data, self-distillation has been empirically observed to improve performance, especially when applied repeatedly. For such a process, there is a fundamental question of interest: How much gain is possible by applying multiple steps of self-distillation? To investigate this relative gain, we propose studying the simple but canonical task of linear regression. Our analysis shows that the excess risk achieved by multi-step self-distillation can significantly improve upon a single step of self-distillation, reducing the excess risk by a factor as large as $d$, where $d$ is the input dimension. Empirical results on regression tasks from the UCI repository show a reduction in the learnt model's risk (MSE) by up to 47%.
The Effects of Invertibility on the Representational Complexity of Encoders in Variational Autoencoders
Jul 09, 2021Training and using modern neural-network based latent-variable generative models (like Variational Autoencoders) often require simultaneously training a generative direction along with an inferential(encoding) direction, which approximates the posterior distribution over the latent variables. Thus, the question arises: how complex does the inferential model need to be, in order to be able to accurately model the posterior distribution of a given generative model? In this paper, we identify an important property of the generative map impacting the required size of the encoder. We show that if the generative map is "strongly invertible" (in a sense we suitably formalize), the inferential model need not be much more complex. Conversely, we prove that there exist non-invertible generative maps, for which the encoding direction needs to be exponentially larger (under standard assumptions in computational complexity). Importantly, we do not require the generative model to be layerwise invertible, which a lot of the related literature assumes and isn't satisfied by many architectures used in practice (e.g. convolution and pooling based networks). Thus, we provide theoretical support for the empirical wisdom that learning deep generative models is harder when data lies on a low-dimensional manifold.
Finding Input Characterizations for Output Properties in ReLU Neural Networks
Mar 09, 2020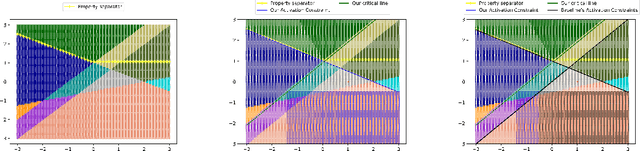
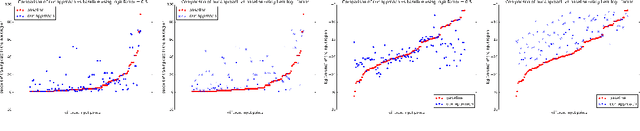
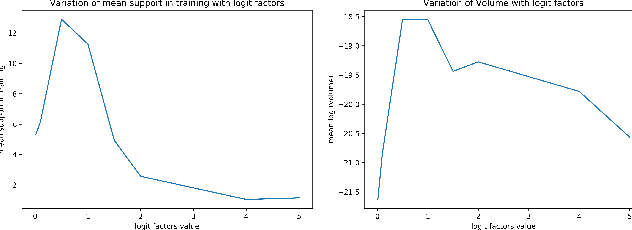
Deep Neural Networks (DNNs) have emerged as a powerful mechanism and are being increasingly deployed in real-world safety-critical domains. Despite the widespread success, their complex architecture makes proving any formal guarantees about them difficult. Identifying how logical notions of high-level correctness relate to the complex low-level network architecture is a significant challenge. In this project, we extend the ideas presented in and introduce a way to bridge the gap between the architecture and the high-level specifications. Our key insight is that instead of directly proving the safety properties that are required, we first prove properties that relate closely to the structure of the neural net and use them to reason about the safety properties. We build theoretical foundations for our approach, and empirically evaluate the performance through various experiments, achieving promising results than the existing approach by identifying a larger region of input space that guarantees a certain property on the output.