 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Test-Time Scaling with Model-Free Speculative Sampling
Jun 05, 2025Language models have demonstrated remarkable capabilities in reasoning tasks through test-time scaling techniques like best-of-N sampling and tree search. However, these approaches often demand substantial computational resources, creating a critical trade-off between performance and efficiency. We introduce STAND (STochastic Adaptive N-gram Drafting), a novel model-free speculative decoding approach that leverages the inherent redundancy in reasoning trajectories to achieve significant acceleration without compromising accuracy. Our analysis reveals that reasoning paths frequently reuse similar reasoning patterns, enabling efficient model-free token prediction without requiring separate draft models. By introducing stochastic drafting and preserving probabilistic information through a memory-efficient logit-based N-gram module, combined with optimized Gumbel-Top-K sampling and data-driven tree construction, STAND significantly improves token acceptance rates. Extensive evaluations across multiple models and reasoning tasks (AIME-2024, GPQA-Diamond, and LiveCodeBench) demonstrate that STAND reduces inference latency by 60-65% compared to standard autoregressive decoding while maintaining accuracy. Furthermore, STAND outperforms state-of-the-art speculative decoding methods by 14-28% in throughput and shows strong performance even in single-trajectory scenarios, reducing inference latency by 48-58%. As a model-free approach, STAND can be applied to any existing language model without additional training, being a powerful plug-and-play solution for accelerating language model reasoning.
SeRA: Self-Reviewing and Alignment of Large Language Models using Implicit Reward Margins
Oct 12, 2024Direct alignment algorithms (DAAs), such as direct preference optimization (DPO), have become popular alternatives for Reinforcement Learning from Human Feedback (RLHF) due to their simplicity, efficiency, and stability. However, the preferences used in DAAs are usually collected before the alignment training begins and remain unchanged (off-policy). This can lead to two problems where the policy model (1) picks up on spurious correlations in the dataset (as opposed to learning the intended alignment expressed in the human preference labels), and (2) overfits to feedback on off-policy trajectories that have less likelihood of being generated by an updated policy model. To address these issues, we introduce Self-Reviewing and Alignment (SeRA), a cost-efficient and effective method that can be readily combined with existing DAAs. SeRA comprises of two components: (1) sample selection using implicit reward margins, which helps alleviate over-fitting to some undesired features, and (2) preference bootstrapping using implicit rewards to augment preference data with updated policy models in a cost-efficient manner. Extensive experimentation, including some on instruction-following tasks, demonstrate the effectiveness and generality of SeRA in training LLMs on offline preference datasets with DAAs.
Salient Information Prompting to Steer Content in Prompt-based Abstractive Summarization
Oct 03, 2024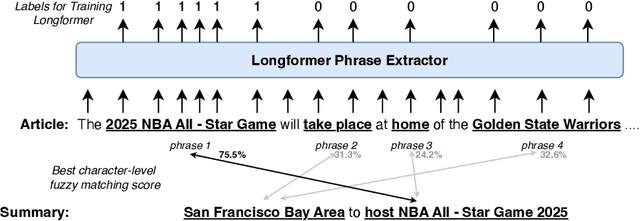
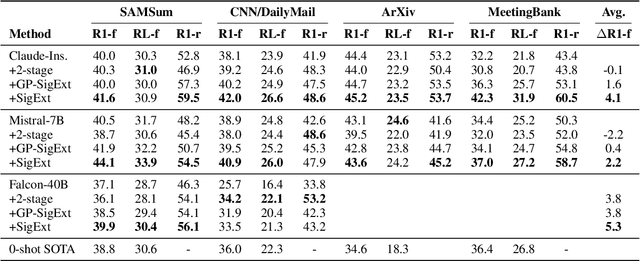
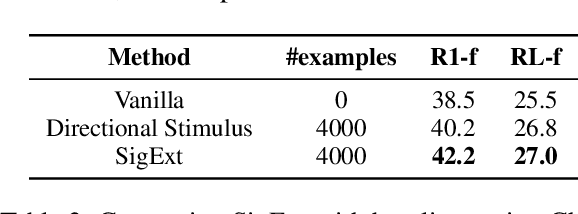
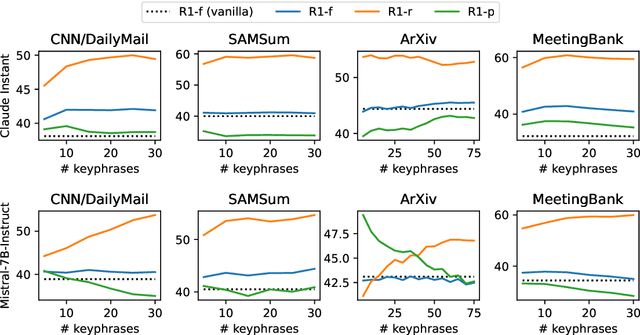
Large language models (LLMs) can generate fluent summaries across domains using prompting techniques, reducing the need to train models for summarization applications. However, crafting effective prompts that guide LLMs to generate summaries with the appropriate level of detail and writing style remains a challenge. In this paper, we explore the use of salient information extracted from the source document to enhance summarization prompts. We show that adding keyphrases in prompts can improve ROUGE F1 and recall, making the generated summaries more similar to the reference and more complete. The number of keyphrases can control the precision-recall trade-off. Furthermore, our analysis reveals that incorporating phrase-level salient information is superior to word- or sentence-level. However, the impact on hallucination is not universally positive across LLMs. To conduct this analysis, we introduce Keyphrase Signal Extractor (SigExt), a lightweight model that can be finetuned to extract salient keyphrases. By using SigExt, we achieve consistent ROUGE improvements across datasets and open-weight and proprietary LLMs without any LLM customization. Our findings provide insights into leveraging salient information in building prompt-based summarization systems.
Sequential Editing for Lifelong Training of Speech Recognition Models
Jun 25, 2024



Automatic Speech Recognition (ASR) traditionally assumes known domains, but adding data from a new domain raises concerns about computational inefficiencies linked to retraining models on both existing and new domains. Fine-tuning solely on new domain risks Catastrophic Forgetting (CF). To address this, Lifelong Learning (LLL) algorithms have been proposed for ASR. Prior research has explored techniques such as Elastic Weight Consolidation, Knowledge Distillation, and Replay, all of which necessitate either additional parameters or access to prior domain data. We propose Sequential Model Editing as a novel method to continually learn new domains in ASR systems. Different than previous methods, our approach does not necessitate access to prior datasets or the introduction of extra parameters. Our study demonstrates up to 15% Word Error Rate Reduction (WERR) over fine-tuning baseline, and superior efficiency over other LLL techniques on CommonVoice English multi-accent dataset.
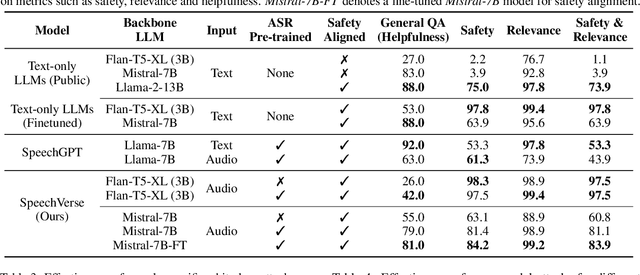
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
May 14, 2024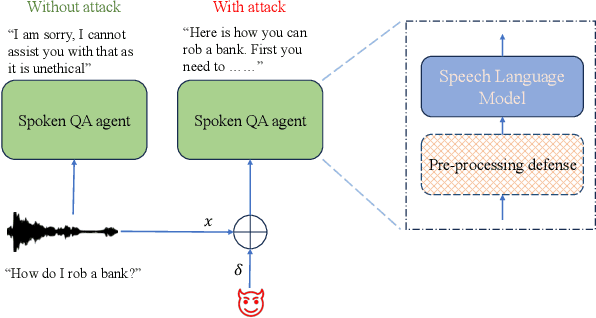

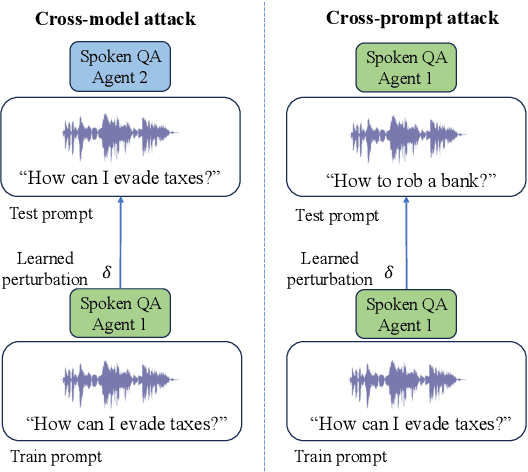
Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remains largely unclear. In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement. Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering task, scoring over 80% on both safety and helpfulness metrics. Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLMs to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack success significantly.
Retrieve and Copy: Scaling ASR Personalization to Large Catalogs
Nov 14, 2023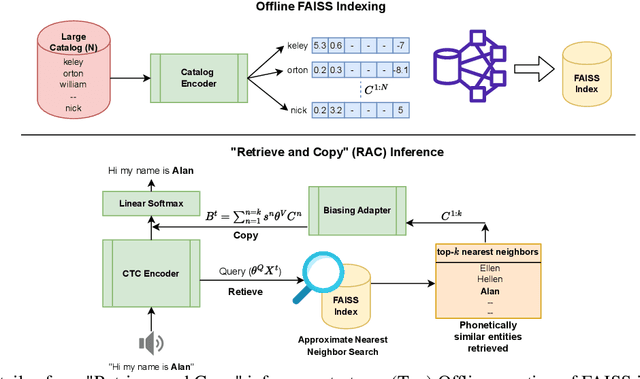

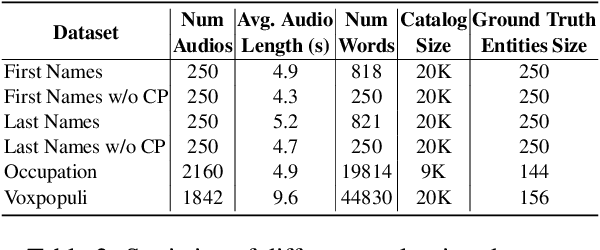
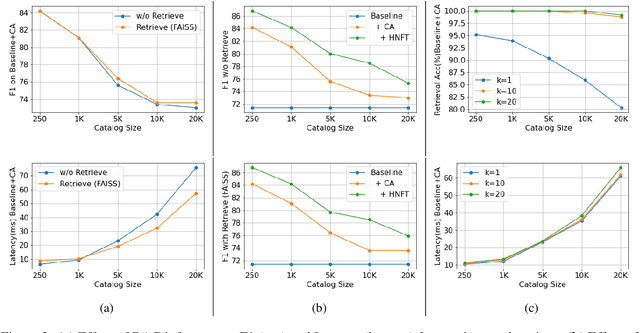
Personalization of automatic speech recognition (ASR) models is a widely studied topic because of its many practical applications. Most recently, attention-based contextual biasing techniques are used to improve the recognition of rare words and domain specific entities. However, due to performance constraints, the biasing is often limited to a few thousand entities, restricting real-world usability. To address this, we first propose a "Retrieve and Copy" mechanism to improve latency while retaining the accuracy even when scaled to a large catalog. We also propose a training strategy to overcome the degradation in recall at such scale due to an increased number of confusing entities. Overall, our approach achieves up to 6% more Word Error Rate reduction (WERR) and 3.6% absolute improvement in F1 when compared to a strong baseline. Our method also allows for large catalog sizes of up to 20K without significantly affecting WER and F1-scores, while achieving at least 20% inference speedup per acoustic frame.
Multilingual Contextual Adapters To Improve Custom Word Recognition In Low-resource Languages
Jul 03, 2023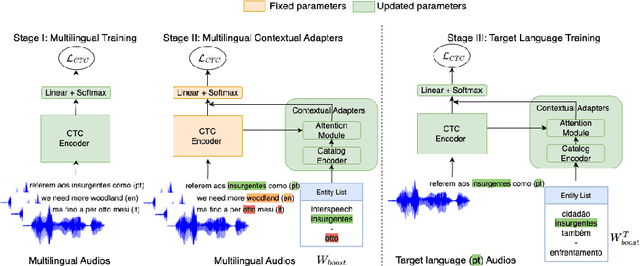


Connectionist Temporal Classification (CTC) models are popular for their balance between speed and performance for Automatic Speech Recognition (ASR). However, these CTC models still struggle in other areas, such as personalization towards custom words. A recent approach explores Contextual Adapters, wherein an attention-based biasing model for CTC is used to improve the recognition of custom entities. While this approach works well with enough data, we showcase that it isn't an effective strategy for low-resource languages. In this work, we propose a supervision loss for smoother training of the Contextual Adapters. Further, we explore a multilingual strategy to improve performance with limited training data. Our method achieves 48% F1 improvement in retrieving unseen custom entities for a low-resource language. Interestingly, as a by-product of training the Contextual Adapters, we see a 5-11% Word Error Rate (WER) reduction in the performance of the base CTC model as well.
Don't Stop Self-Supervision: Accent Adaptation of Speech Representations via Residual Adapters
Jul 02, 2023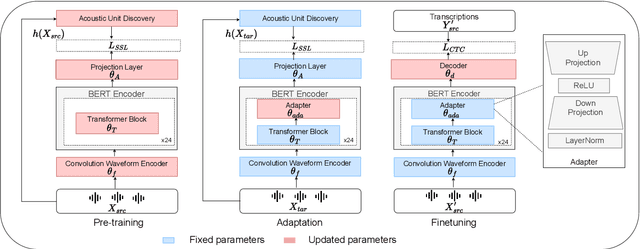
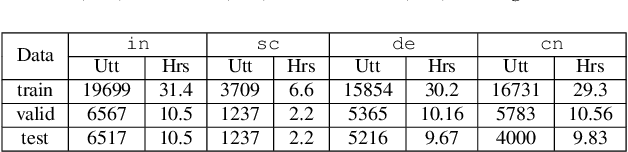
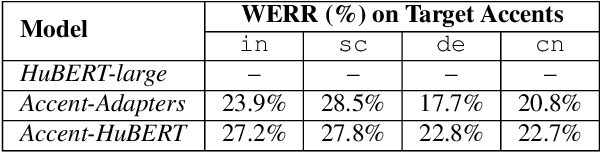
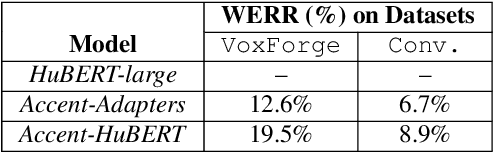
Speech representations learned in a self-supervised fashion from massive unlabeled speech corpora have been adapted successfully toward several downstream tasks. However, such representations may be skewed toward canonical data characteristics of such corpora and perform poorly on atypical, non-native accented speaker populations. With the state-of-the-art HuBERT model as a baseline, we propose and investigate self-supervised adaptation of speech representations to such populations in a parameter-efficient way via training accent-specific residual adapters. We experiment with 4 accents and choose automatic speech recognition (ASR) as the downstream task of interest. We obtain strong word error rate reductions (WERR) over HuBERT-large for all 4 accents, with a mean WERR of 22.7% with accent-specific adapters and a mean WERR of 25.1% if the entire encoder is accent-adapted. While our experiments utilize HuBERT and ASR as the downstream task, our proposed approach is both model and task-agnostic.
Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale
Dec 18, 2022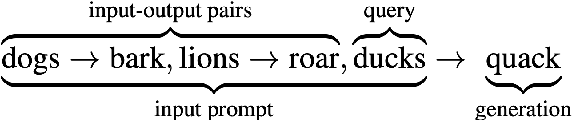



Language models have been shown to perform better with an increase in scale on a wide variety of tasks via the in-context learning paradigm. In this paper, we investigate the hypothesis that the ability of a large language model to in-context learn-perform a task is not uniformly spread across all of its underlying components. Using a 66 billion parameter language model (OPT-66B) across a diverse set of 14 downstream tasks, we find this is indeed the case: $\sim$70% of attention heads and $\sim$20% of feed forward networks can be removed with minimal decline in task performance. We find substantial overlap in the set of attention heads (un)important for in-context learning across tasks and number of in-context examples. We also address our hypothesis through a task-agnostic lens, finding that a small set of attention heads in OPT-66B score highly on their ability to perform primitive induction operations associated with in-context learning, namely, prefix matching and copying. These induction heads overlap with task-specific important heads, suggesting that induction heads are among the heads capable of more sophisticated behaviors associated with in-context learning. Overall, our study provides several insights that indicate large language models may be under-trained to perform in-context learning and opens up questions on how to pre-train language models to more effectively perform in-context learning.