 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multimodal Safety via Conditional Decoding
Mar 31, 2026Multimodal large-language models (MLLMs) often experience degraded safety alignment when harmful queries exploit cross-modal interactions. Models aligned on text alone show a higher rate of successful attacks when extended to two or more modalities. In this work, we propose a simple conditional decoding strategy, CASA (Classification Augmented with Safety Attention) that utilizes internal representations of MLLMs to predict a binary safety token before response generation. We introduce a novel safety attention module designed to enhance the model's ability to detect malicious queries. Our design ensures robust safety alignment without relying on any external classifier or auxiliary head, and without the need for modality-specific safety fine-tuning. On diverse benchmarks such as MM-SafetyBench, JailbreakV-28k, and adversarial audio tests, CASA lowers the average attack success rate by more than 97% across modalities and across attack types. Our empirical evaluations also show that CASA maintains strong utility in benign inputs, a result validated through both automated and human evaluations (via 13 trained annotators). Together, these results highlight CASA as a simple and generalizable framework to improve multimodal LLM safety.
SEAL: Speaker Error Correction using Acoustic-conditioned Large Language Models
Jan 14, 2025



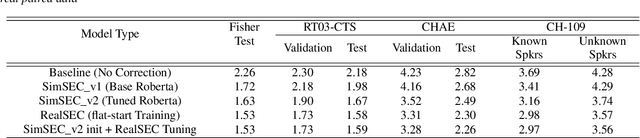
Speaker Diarization (SD) is a crucial component of modern end-to-end ASR pipelines. Traditional SD systems, which are typically audio-based and operate independently of ASR, often introduce speaker errors, particularly during speaker transitions and overlapping speech. Recently, language models including fine-tuned large language models (LLMs) have shown to be effective as a second-pass speaker error corrector by leveraging lexical context in the transcribed output. In this work, we introduce a novel acoustic conditioning approach to provide more fine-grained information from the acoustic diarizer to the LLM. We also show that a simpler constrained decoding strategy reduces LLM hallucinations, while avoiding complicated post-processing. Our approach significantly reduces the speaker error rates by 24-43% across Fisher, Callhome, and RT03-CTS datasets, compared to the first-pass Acoustic SD.
Speakers Unembedded: Embedding-free Approach to Long-form Neural Diarization
Jun 26, 2024



End-to-end neural diarization (EEND) models offer significant improvements over traditional embedding-based Speaker Diarization (SD) approaches but falls short on generalizing to long-form audio with large number of speakers. EEND-vector-clustering method mitigates this by combining local EEND with global clustering of speaker embeddings from local windows, but this requires an additional speaker embedding framework alongside the EEND module. In this paper, we propose a novel framework applying EEND both locally and globally for long-form audio without separate speaker embeddings. This approach achieves significant relative DER reduction of 13% and 10% over the conventional 1-pass EEND on Callhome American English and RT03-CTS datasets respectively and marginal improvements over EEND-vector-clustering without the need for additional speaker embeddings. Furthermore, we discuss the computational complexity of our proposed framework and explore strategies for reducing processing times.
AG-LSEC: Audio Grounded Lexical Speaker Error Correction
Jun 25, 2024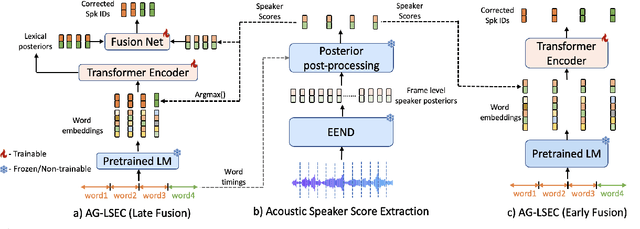

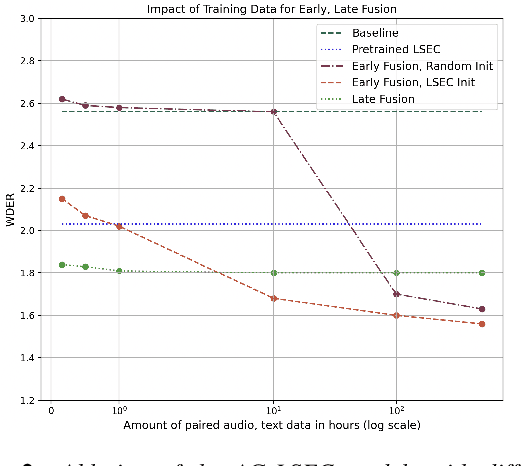
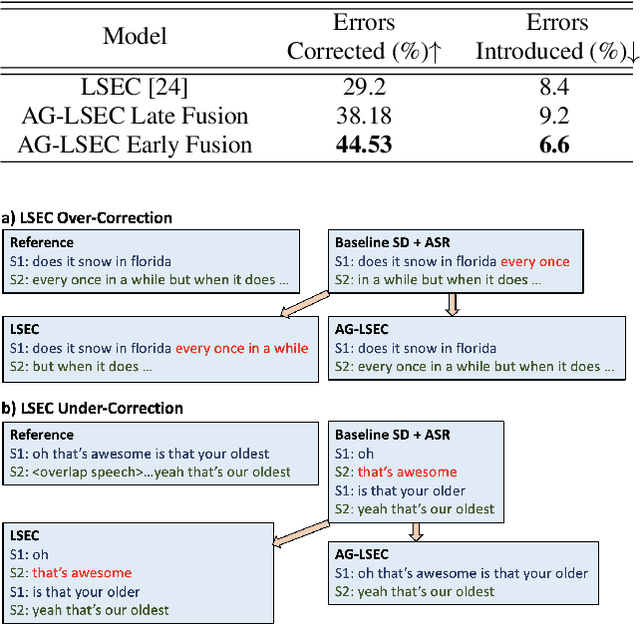
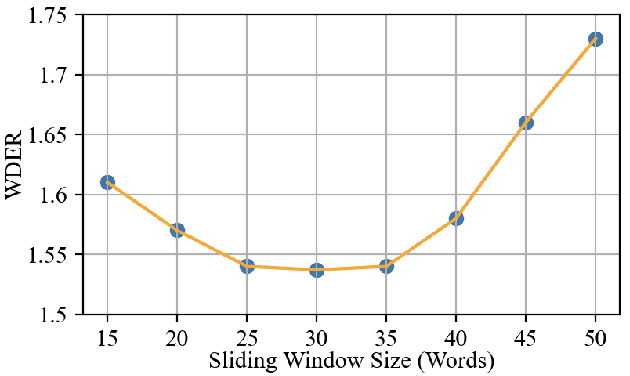
Speaker Diarization (SD) systems are typically audio-based and operate independently of the ASR system in traditional speech transcription pipelines and can have speaker errors due to SD and/or ASR reconciliation, especially around speaker turns and regions of speech overlap. To reduce these errors, a Lexical Speaker Error Correction (LSEC), in which an external language model provides lexical information to correct the speaker errors, was recently proposed. Though the approach achieves good Word Diarization error rate (WDER) improvements, it does not use any additional acoustic information and is prone to miscorrections. In this paper, we propose to enhance and acoustically ground the LSEC system with speaker scores directly derived from the existing SD pipeline. This approach achieves significant relative WDER reductions in the range of 25-40% over the audio-based SD, ASR system and beats the LSEC system by 15-25% relative on RT03-CTS, Callhome American English and Fisher datasets.
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
Generalized zero-shot audio-to-intent classification
Nov 04, 2023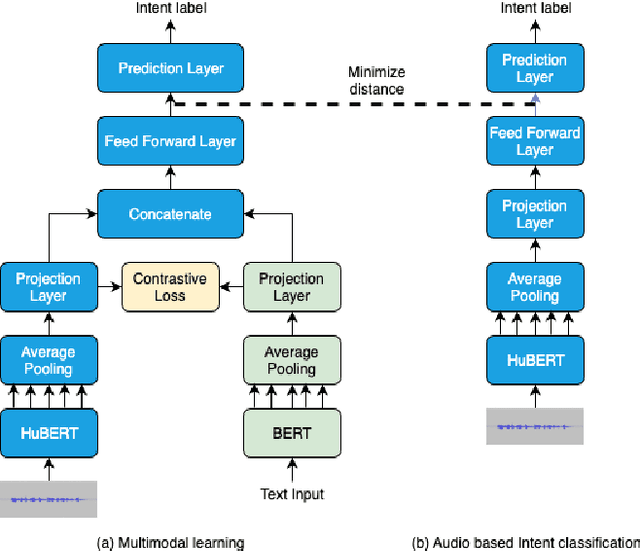
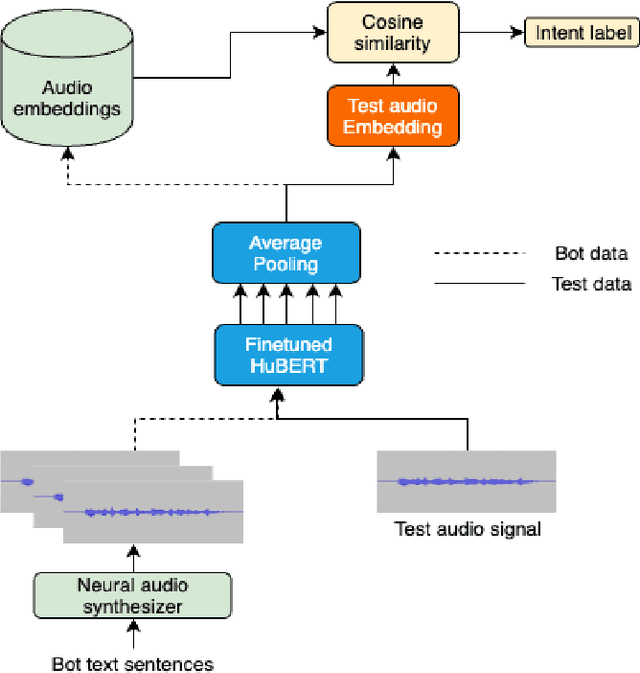
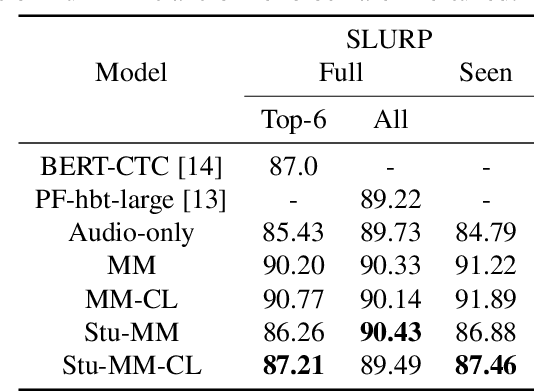
Spoken language understanding systems using audio-only data are gaining popularity, yet their ability to handle unseen intents remains limited. In this study, we propose a generalized zero-shot audio-to-intent classification framework with only a few sample text sentences per intent. To achieve this, we first train a supervised audio-to-intent classifier by making use of a self-supervised pre-trained model. We then leverage a neural audio synthesizer to create audio embeddings for sample text utterances and perform generalized zero-shot classification on unseen intents using cosine similarity. We also propose a multimodal training strategy that incorporates lexical information into the audio representation to improve zero-shot performance. Our multimodal training approach improves the accuracy of zero-shot intent classification on unseen intents of SLURP by 2.75% and 18.2% for the SLURP and internal goal-oriented dialog datasets, respectively, compared to audio-only training.
End-to-End Single-Channel Speaker-Turn Aware Conversational Speech Translation
Nov 01, 2023



Conventional speech-to-text translation (ST) systems are trained on single-speaker utterances, and they may not generalize to real-life scenarios where the audio contains conversations by multiple speakers. In this paper, we tackle single-channel multi-speaker conversational ST with an end-to-end and multi-task training model, named Speaker-Turn Aware Conversational Speech Translation, that combines automatic speech recognition, speech translation and speaker turn detection using special tokens in a serialized labeling format. We run experiments on the Fisher-CALLHOME corpus, which we adapted by merging the two single-speaker channels into one multi-speaker channel, thus representing the more realistic and challenging scenario with multi-speaker turns and cross-talk. Experimental results across single- and multi-speaker conditions and against conventional ST systems, show that our model outperforms the reference systems on the multi-speaker condition, while attaining comparable performance on the single-speaker condition. We release scripts for data processing and model training.
Speaker Diarization of Scripted Audiovisual Content
Aug 04, 2023

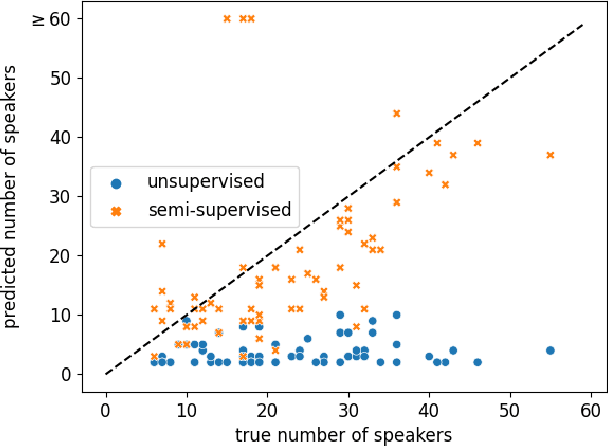
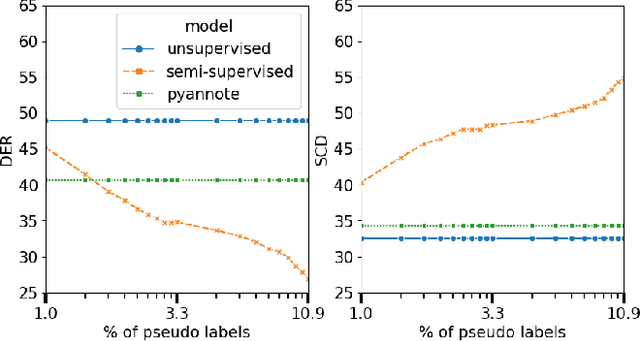
The media localization industry usually requires a verbatim script of the final film or TV production in order to create subtitles or dubbing scripts in a foreign language. In particular, the verbatim script (i.e. as-broadcast script) must be structured into a sequence of dialogue lines each including time codes, speaker name and transcript. Current speech recognition technology alleviates the transcription step. However, state-of-the-art speaker diarization models still fall short on TV shows for two main reasons: (i) their inability to track a large number of speakers, (ii) their low accuracy in detecting frequent speaker changes. To mitigate this problem, we present a novel approach to leverage production scripts used during the shooting process, to extract pseudo-labeled data for the speaker diarization task. We propose a novel semi-supervised approach and demonstrate improvements of 51.7% relative to two unsupervised baseline models on our metrics on a 66 show test set.
Lexical Speaker Error Correction: Leveraging Language Models for Speaker Diarization Error Correction
Jun 15, 2023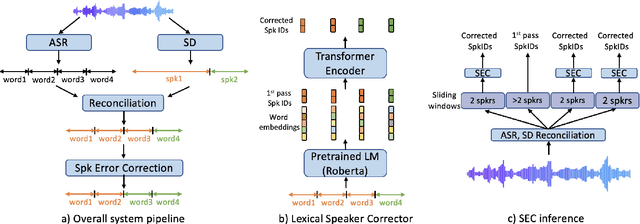
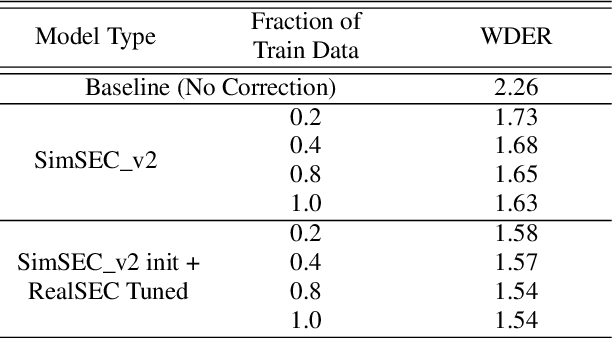
Speaker diarization (SD) is typically used with an automatic speech recognition (ASR) system to ascribe speaker labels to recognized words. The conventional approach reconciles outputs from independently optimized ASR and SD systems, where the SD system typically uses only acoustic information to identify the speakers in the audio stream. This approach can lead to speaker errors especially around speaker turns and regions of speaker overlap. In this paper, we propose a novel second-pass speaker error correction system using lexical information, leveraging the power of modern language models (LMs). Our experiments across multiple telephony datasets show that our approach is both effective and robust. Training and tuning only on the Fisher dataset, this error correction approach leads to relative word-level diarization error rate (WDER) reductions of 15-30% on three telephony datasets: RT03-CTS, Callhome American English and held-out portions of Fisher.
Directed Speech Separation for Automatic Speech Recognition of Long Form Conversational Speech
Dec 10, 2021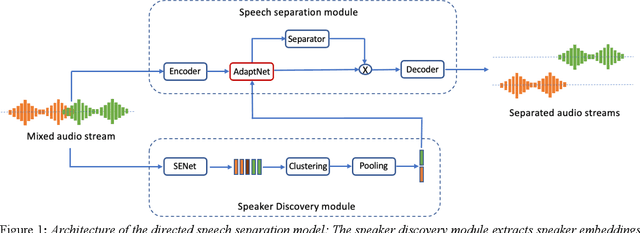
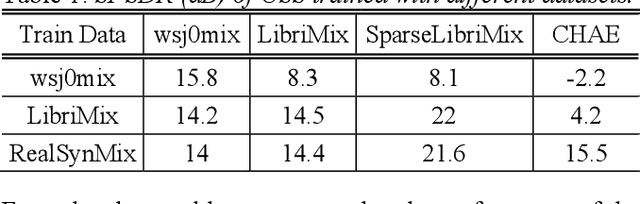
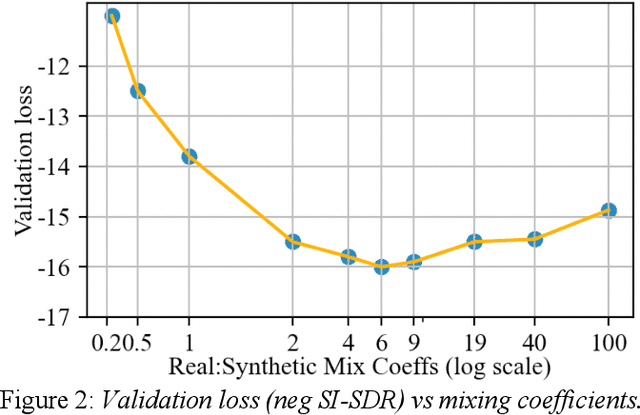

Many of the recent advances in speech separation are primarily aimed at synthetic mixtures of short audio utterances with high degrees of overlap. These datasets significantly differ from the real conversational data and hence, the models trained and evaluated on these datasets do not generalize to real conversational scenarios. Another issue with using most of these models for long form speech is the nondeterministic ordering of separated speech segments due to either unsupervised clustering for time-frequency masks or Permutation Invariant training (PIT) loss. This leads to difficulty in accurately stitching homogenous speaker segments for downstream tasks like Automatic Speech Recognition (ASR). In this paper, we propose a speaker conditioned separator trained on speaker embeddings extracted directly from the mixed signal. We train this model using a directed loss which regulates the order of the separated segments. With this model, we achieve significant improvements on Word error rate (WER) for real conversational data without the need for an additional re-stitching step.