 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoVieDrive: Multi-Modal Multi-View Urban Scene Video Generation
Aug 20, 2025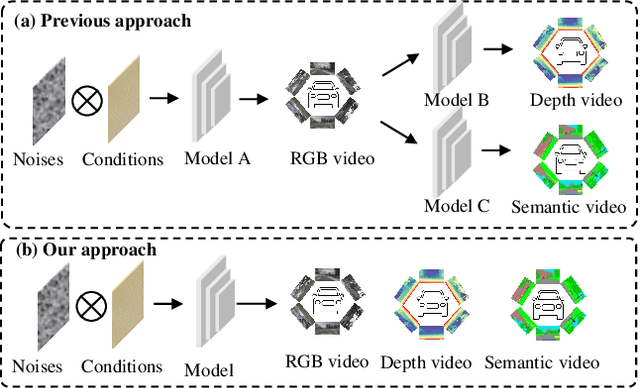
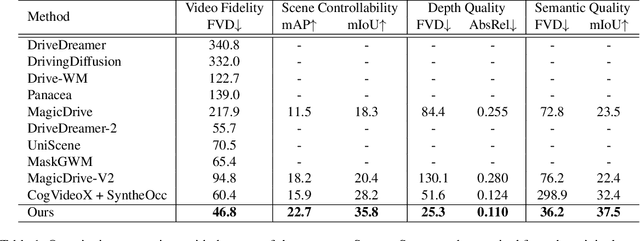
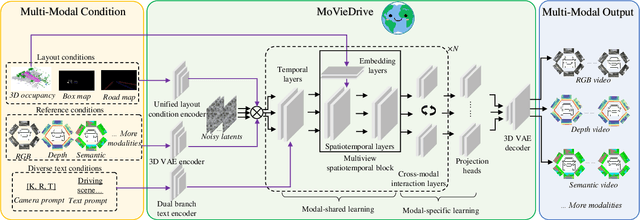
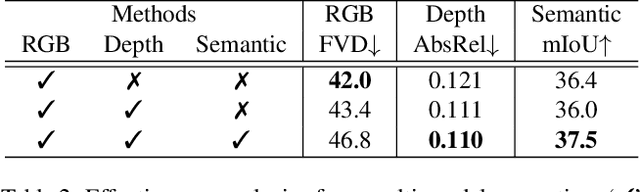
Video generation has recently shown superiority in urban scene synthesis for autonomous driving. Existing video generation approaches to autonomous driving primarily focus on RGB video generation and lack the ability to support multi-modal video generation. However, multi-modal data, such as depth maps and semantic maps, are crucial for holistic urban scene understanding in autonomous driving. Although it is feasible to use multiple models to generate different modalities, this increases the difficulty of model deployment and does not leverage complementary cues for multi-modal data generation. To address this problem, in this work, we propose a novel multi-modal multi-view video generation approach to autonomous driving. Specifically, we construct a unified diffusion transformer model composed of modal-shared components and modal-specific components. Then, we leverage diverse conditioning inputs to encode controllable scene structure and content cues into the unified diffusion model for multi-modal multi-view video generation. In this way, our approach is capable of generating multi-modal multi-view driving scene videos in a unified framework. Our experiments on the challenging real-world autonomous driving dataset, nuScenes, show that our approach can generate multi-modal multi-view urban scene videos with high fidelity and controllability, surpassing the state-of-the-art methods.
Robo-DM: Data Management For Large Robot Datasets
May 21, 2025
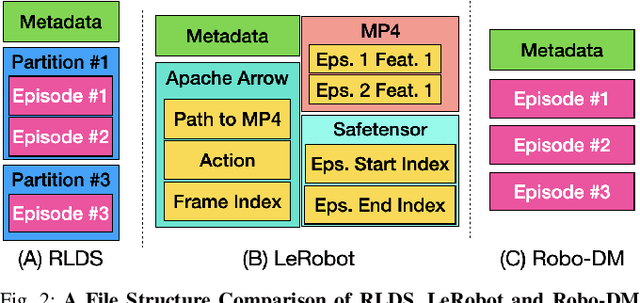


Recent results suggest that very large datasets of teleoperated robot demonstrations can be used to train transformer-based models that have the potential to generalize to new scenes, robots, and tasks. However, curating, distributing, and loading large datasets of robot trajectories, which typically consist of video, textual, and numerical modalities - including streams from multiple cameras - remains challenging. We propose Robo-DM, an efficient open-source cloud-based data management toolkit for collecting, sharing, and learning with robot data. With Robo-DM, robot datasets are stored in a self-contained format with Extensible Binary Meta Language (EBML). Robo-DM can significantly reduce the size of robot trajectory data, transfer costs, and data load time during training. Compared to the RLDS format used in OXE datasets, Robo-DM's compression saves space by up to 70x (lossy) and 3.5x (lossless). Robo-DM also accelerates data retrieval by load-balancing video decoding with memory-mapped decoding caches. Compared to LeRobot, a framework that also uses lossy video compression, Robo-DM is up to 50x faster when decoding sequentially. We physically evaluate a model trained by Robo-DM with lossy compression, a pick-and-place task, and In-Context Robot Transformer. Robo-DM uses 75x compression of the original dataset and does not suffer reduction in downstream task accuracy.
Measuring General Intelligence with Generated Games
May 12, 2025We present gg-bench, a collection of game environments designed to evaluate general reasoning capabilities in language models. Unlike most static benchmarks, gg-bench is a data generating process where new evaluation instances can be generated at will. In particular, gg-bench is synthetically generated by (1) using a large language model (LLM) to generate natural language descriptions of novel games, (2) using the LLM to implement each game in code as a Gym environment, and (3) training reinforcement learning (RL) agents via self-play on the generated games. We evaluate language models by their winrate against these RL agents by prompting models with the game description, current board state, and a list of valid moves, after which models output the moves they wish to take. gg-bench is challenging: state-of-the-art LLMs such as GPT-4o and Claude 3.7 Sonnet achieve winrates of 7-9% on gg-bench using in-context learning, while reasoning models such as o1, o3-mini and DeepSeek-R1 achieve average winrates of 31-36%. We release the generated games, data generation process, and evaluation code in order to support future modeling work and expansion of our benchmark.
Improving LLM Safety Alignment with Dual-Objective Optimization
Mar 05, 2025



Existing training-time safety alignment techniques for large language models (LLMs) remain vulnerable to jailbreak attacks. Direct preference optimization (DPO), a widely deployed alignment method, exhibits limitations in both experimental and theoretical contexts as its loss function proves suboptimal for refusal learning. Through gradient-based analysis, we identify these shortcomings and propose an improved safety alignment that disentangles DPO objectives into two components: (1) robust refusal training, which encourages refusal even when partial unsafe generations are produced, and (2) targeted unlearning of harmful knowledge. This approach significantly increases LLM robustness against a wide range of jailbreak attacks, including prefilling, suffix, and multi-turn attacks across both in-distribution and out-of-distribution scenarios. Furthermore, we introduce a method to emphasize critical refusal tokens by incorporating a reward-based token-level weighting mechanism for refusal learning, which further improves the robustness against adversarial exploits. Our research also suggests that robustness to jailbreak attacks is correlated with token distribution shifts in the training process and internal representations of refusal and harmful tokens, offering valuable directions for future research in LLM safety alignment. The code is available at https://github.com/wicai24/DOOR-Alignment
Accelerated Preference Elicitation with LLM-Based Proxies
Jan 24, 2025Bidders in combinatorial auctions face significant challenges when describing their preferences to an auctioneer. Classical work on preference elicitation focuses on query-based techniques inspired from proper learning--often via proxies that interface between bidders and an auction mechanism--to incrementally learn bidder preferences as needed to compute efficient allocations. Although such elicitation mechanisms enjoy theoretical query efficiency, the amount of communication required may still be too cognitively taxing in practice. We propose a family of efficient LLM-based proxy designs for eliciting preferences from bidders using natural language. Our proposed mechanism combines LLM pipelines and DNF-proper-learning techniques to quickly approximate preferences when communication is limited. To validate our approach, we create a testing sandbox for elicitation mechanisms that communicate in natural language. In our experiments, our most promising LLM proxy design reaches approximately efficient outcomes with five times fewer queries than classical proper learning based elicitation mechanisms.
Enhanced Momentum with Momentum Transformers
Dec 17, 2024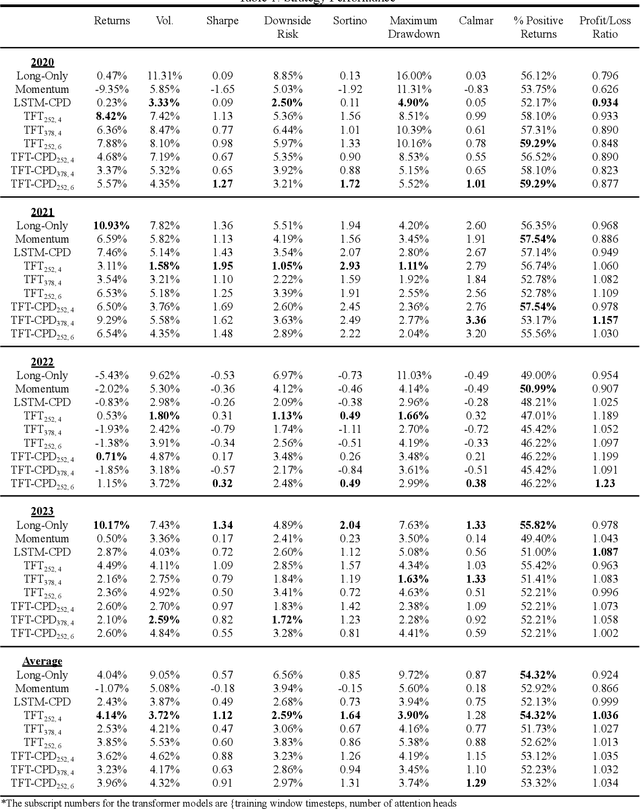
The primary objective of this research is to build a Momentum Transformer that is expected to outperform benchmark time-series momentum and mean-reversion trading strategies. We extend the ideas introduced in the paper Trading with the Momentum Transformer: An Intelligent and Interpretable Architecture to equities as the original paper primarily only builds upon futures and equity indices. Unlike conventional Long Short-Term Memory (LSTM) models, which operate sequentially and are optimized for processing local patterns, an attention mechanism equips our architecture with direct access to all prior time steps in the training window. This hybrid design, combining attention with an LSTM, enables the model to capture long-term dependencies, enhance performance in scenarios accounting for transaction costs, and seamlessly adapt to evolving market conditions, such as those witnessed during the Covid Pandemic. We average 4.14% returns which is similar to the original papers results. Our Sharpe is lower at an average of 1.12 due to much higher volatility which may be due to stocks being inherently more volatile than futures and indices.
A Hybrid Deep Learning Classification of Perimetric Glaucoma Using Peripapillary Nerve Fiber Layer Reflectance and Other OCT Parameters from Three Anatomy Regions
Jun 06, 2024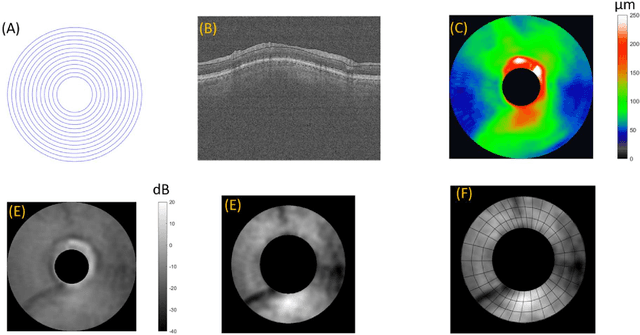
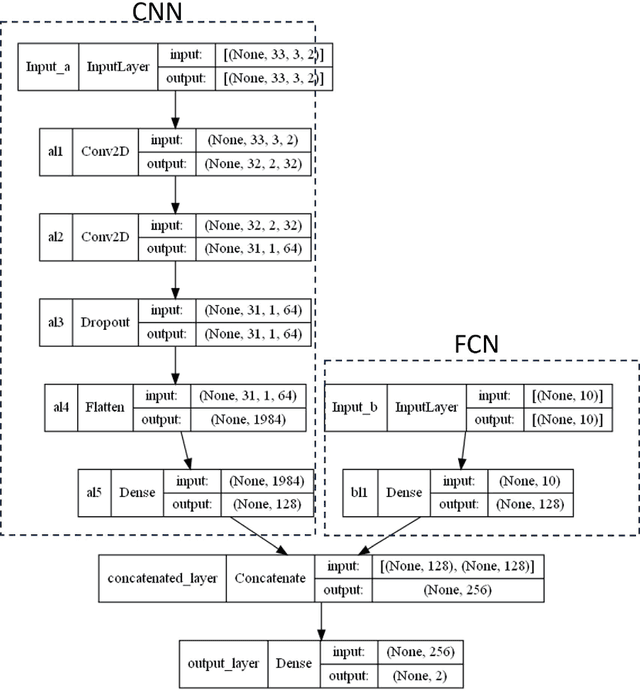
Precis: A hybrid deep-learning model combines NFL reflectance and other OCT parameters to improve glaucoma diagnosis. Objective: To investigate if a deep learning model could be used to combine nerve fiber layer (NFL) reflectance and other OCT parameters for glaucoma diagnosis. Patients and Methods: This is a prospective observational study where of 106 normal subjects and 164 perimetric glaucoma (PG) patients. Peripapillary NFL reflectance map, NFL thickness map, optic head analysis of disc, and macular ganglion cell complex thickness were obtained using spectral domain OCT. A hybrid deep learning model combined a fully connected network (FCN) and a convolution neural network (CNN) to develop and combine those OCT maps and parameters to distinguish normal and PG eyes. Two deep learning models were compared based on whether the NFL reflectance map was used as part of the input or not. Results: The hybrid deep learning model with reflectance achieved 0.909 sensitivity at 99% specificity and 0.926 at 95%. The overall accuracy was 0.948 with 0.893 sensitivity and 1.000 specificity, and the AROC was 0.979, which is significantly better than the logistic regression models (p < 0.001). The second best model is the hybrid deep learning model w/o reflectance, which also had significantly higher AROC than logistic regression models (p < 0.001). Logistic regression with reflectance model had slightly higher AROC or sensitivity than the other logistic regression model without reflectance (p = 0.024). Conclusions: Hybrid deep learning model significantly improved the diagnostic accuracy, without or without NFL reflectance. Hybrid deep learning model, combining reflectance/NFL thickness/GCC thickness/ONH parameter, may be a practical model for glaucoma screen purposes.
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
Defending Against Transfer Attacks From Public Models
Oct 26, 2023Adversarial attacks have been a looming and unaddressed threat in the industry. However, through a decade-long history of the robustness evaluation literature, we have learned that mounting a strong or optimal attack is challenging. It requires both machine learning and domain expertise. In other words, the white-box threat model, religiously assumed by a large majority of the past literature, is unrealistic. In this paper, we propose a new practical threat model where the adversary relies on transfer attacks through publicly available surrogate models. We argue that this setting will become the most prevalent for security-sensitive applications in the future. We evaluate the transfer attacks in this setting and propose a specialized defense method based on a game-theoretic perspective. The defenses are evaluated under 24 public models and 11 attack algorithms across three datasets (CIFAR-10, CIFAR-100, and ImageNet). Under this threat model, our defense, PubDef, outperforms the state-of-the-art white-box adversarial training by a large margin with almost no loss in the normal accuracy. For instance, on ImageNet, our defense achieves 62% accuracy under the strongest transfer attack vs only 36% of the best adversarially trained model. Its accuracy when not under attack is only 2% lower than that of an undefended model (78% vs 80%). We release our code at https://github.com/wagner-group/pubdef.
Interpretable Diabetic Retinopathy Diagnosis based on Biomarker Activation Map
Dec 13, 2022



Deep learning classifiers provide the most accurate means of automatically diagnosing diabetic retinopathy (DR) based on optical coherence tomography (OCT) and its angiography (OCTA). The power of these models is attributable in part to the inclusion of hidden layers that provide the complexity required to achieve a desired task. However, hidden layers also render algorithm outputs difficult to interpret. Here we introduce a novel biomarker activation map (BAM) framework based on generative adversarial learning that allows clinicians to verify and understand classifiers decision-making. A data set including 456 macular scans were graded as non-referable or referable DR based on current clinical standards. A DR classifier that was used to evaluate our BAM was first trained based on this data set. The BAM generation framework was designed by combing two U-shaped generators to provide meaningful interpretability to this classifier. The main generator was trained to take referable scans as input and produce an output that would be classified by the classifier as non-referable. The BAM is then constructed as the difference image between the output and input of the main generator. To ensure that the BAM only highlights classifier-utilized biomarkers an assistant generator was trained to do the opposite, producing scans that would be classified as referable by the classifier from non-referable scans. The generated BAMs highlighted known pathologic features including nonperfusion area and retinal fluid. A fully interpretable classifier based on these highlights could help clinicians better utilize and verify automated DR diagnosis.