 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
Device Directedness with Contextual Cues for Spoken Dialog Systems
Nov 23, 2022In this work, we define barge-in verification as a supervised learning task where audio-only information is used to classify user spoken dialogue into true and false barge-ins. Following the success of pre-trained models, we use low-level speech representations from a self-supervised representation learning model for our downstream classification task. Further, we propose a novel technique to infuse lexical information directly into speech representations to improve the domain-specific language information implicitly learned during pre-training. Experiments conducted on spoken dialog data show that our proposed model trained to validate barge-in entirely from speech representations is faster by 38% relative and achieves 4.5% relative F1 score improvement over a baseline LSTM model that uses both audio and Automatic Speech Recognition (ASR) 1-best hypotheses. On top of this, our best proposed model with lexically infused representations along with contextual features provides a further relative improvement of 5.7% in the F1 score but only 22% faster than the baseline.
Remember the context! ASR slot error correction through memorization
Sep 18, 2021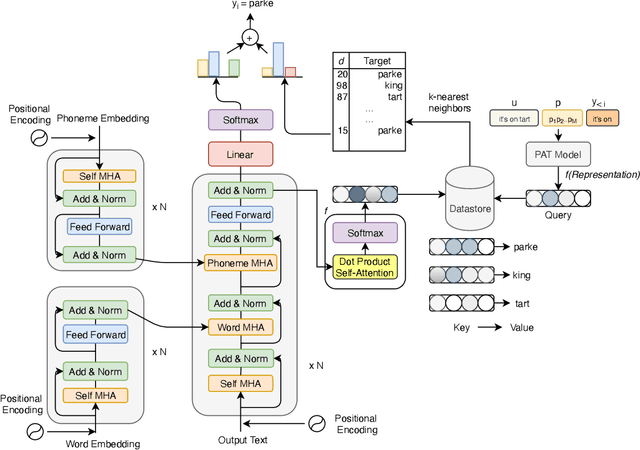
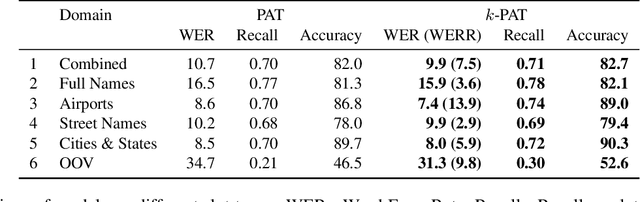
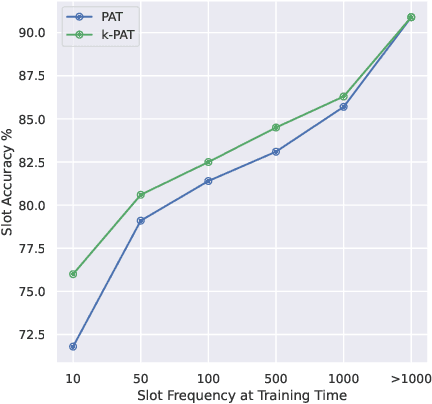
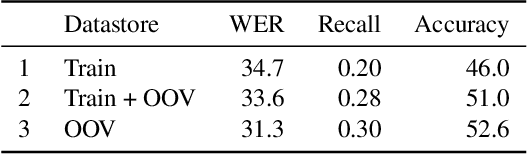
Accurate recognition of slot values such as domain specific words or named entities by automatic speech recognition (ASR) systems forms the core of the Goal-oriented Dialogue Systems. Although it is a critical step with direct impact on downstream tasks such as language understanding, many domain agnostic ASR systems tend to perform poorly on domain specific or long tail words. They are often supplemented with slot error correcting systems but it is often hard for any neural model to directly output such rare entity words. To address this problem, we propose k-nearest neighbor (k-NN) search that outputs domain-specific entities from an explicit datastore. We improve error correction rate by conveniently augmenting a pretrained joint phoneme and text based transformer sequence to sequence model with k-NN search during inference. We evaluate our proposed approach on five different domains containing long tail slot entities such as full names, airports, street names, cities, states. Our best performing error correction model shows a relative improvement of 7.4% in word error rate (WER) on rare word entities over the baseline and also achieves a relative WER improvement of 9.8% on an out of vocabulary (OOV) test set.
Multimodal Semi-supervised Learning Framework for Punctuation Prediction in Conversational Speech
Aug 03, 2020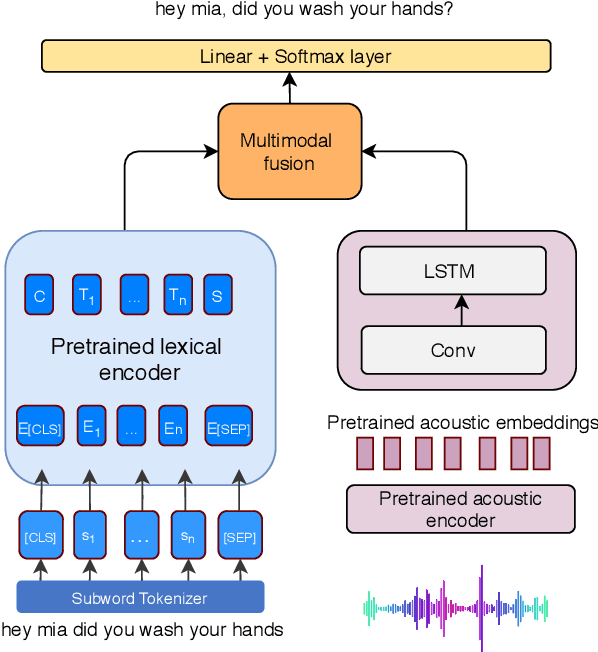
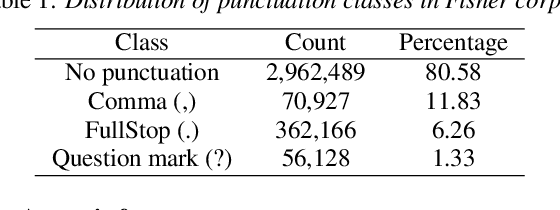
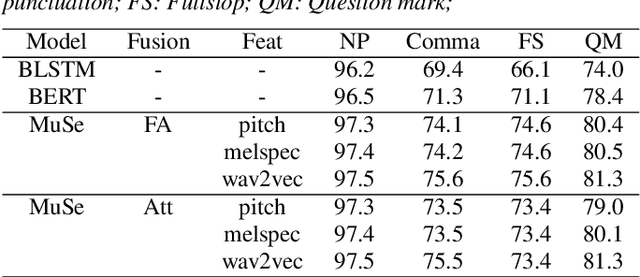
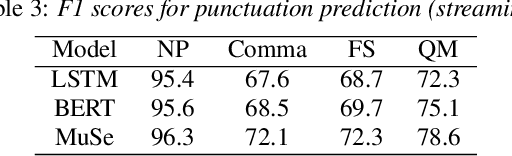
In this work, we explore a multimodal semi-supervised learning approach for punctuation prediction by learning representations from large amounts of unlabelled audio and text data. Conventional approaches in speech processing typically use forced alignment to encoder per frame acoustic features to word level features and perform multimodal fusion of the resulting acoustic and lexical representations. As an alternative, we explore attention based multimodal fusion and compare its performance with forced alignment based fusion. Experiments conducted on the Fisher corpus show that our proposed approach achieves ~6-9% and ~3-4% absolute improvement (F1 score) over the baseline BLSTM model on reference transcripts and ASR outputs respectively. We further improve the model robustness to ASR errors by performing data augmentation with N-best lists which achieves up to an additional ~2-6% improvement on ASR outputs. We also demonstrate the effectiveness of semi-supervised learning approach by performing ablation study on various sizes of the corpus. When trained on 1 hour of speech and text data, the proposed model achieved ~9-18% absolute improvement over baseline model.
Text Generation from Knowledge Graphs with Graph Transformers
May 18, 2019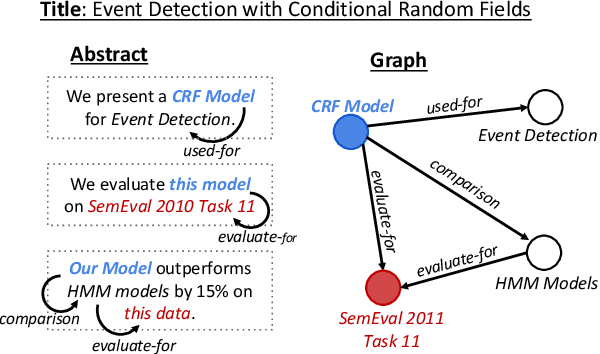
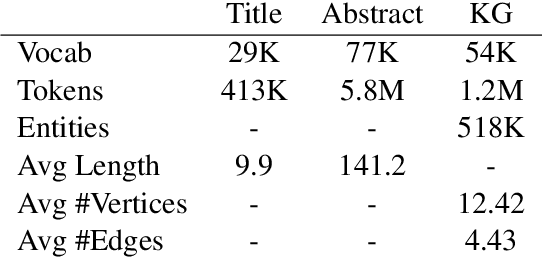
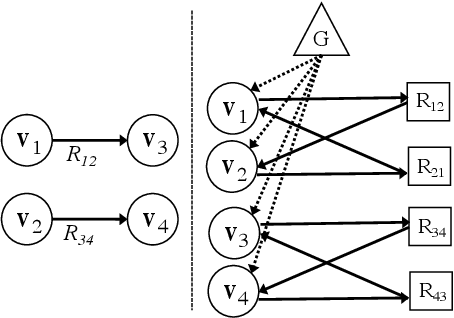

Generating texts which express complex ideas spanning multiple sentences requires a structured representation of their content (document plan), but these representations are prohibitively expensive to manually produce. In this work, we address the problem of generating coherent multi-sentence texts from the output of an information extraction system, and in particular a knowledge graph. Graphical knowledge representations are ubiquitous in computing, but pose a significant challenge for text generation techniques due to their non-hierarchical nature, collapsing of long-distance dependencies, and structural variety. We introduce a novel graph transforming encoder which can leverage the relational structure of such knowledge graphs without imposing linearization or hierarchical constraints. Incorporated into an encoder-decoder setup, we provide an end-to-end trainable system for graph-to-text generation that we apply to the domain of scientific text. Automatic and human evaluations show that our technique produces more informative texts which exhibit better document structure than competitive encoder-decoder methods.