 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL: Speaker Error Correction using Acoustic-conditioned Large Language Models
Jan 14, 2025



Speaker Diarization (SD) is a crucial component of modern end-to-end ASR pipelines. Traditional SD systems, which are typically audio-based and operate independently of ASR, often introduce speaker errors, particularly during speaker transitions and overlapping speech. Recently, language models including fine-tuned large language models (LLMs) have shown to be effective as a second-pass speaker error corrector by leveraging lexical context in the transcribed output. In this work, we introduce a novel acoustic conditioning approach to provide more fine-grained information from the acoustic diarizer to the LLM. We also show that a simpler constrained decoding strategy reduces LLM hallucinations, while avoiding complicated post-processing. Our approach significantly reduces the speaker error rates by 24-43% across Fisher, Callhome, and RT03-CTS datasets, compared to the first-pass Acoustic SD.
Meta-Learning Adaptable Foundation Models
Oct 29, 2024The power of foundation models (FMs) lies in their capacity to learn highly expressive representations that can be adapted to a broad spectrum of tasks. However, these pretrained models require multiple stages of fine-tuning to become effective for downstream applications. Conventionally, the model is first retrained on the aggregate of a diverse set of tasks of interest and then adapted to specific low-resource downstream tasks by utilizing a parameter-efficient fine-tuning (PEFT) scheme. While this two-phase procedure seems reasonable, the independence of the retraining and fine-tuning phases causes a major issue, as there is no guarantee the retrained model will achieve good performance post-fine-tuning. To explicitly address this issue, we introduce a meta-learning framework infused with PEFT in this intermediate retraining stage to learn a model that can be easily adapted to unseen tasks. For our theoretical results, we focus on linear models using low-rank adaptations. In this setting, we demonstrate the suboptimality of standard retraining for finding an adaptable set of parameters. Further, we prove that our method recovers the optimally adaptable parameters. We then apply these theoretical insights to retraining the RoBERTa model to predict the continuation of conversations between different personas within the ConvAI2 dataset. Empirically, we observe significant performance benefits using our proposed meta-learning scheme during retraining relative to the conventional approach.
CriSPO: Multi-Aspect Critique-Suggestion-guided Automatic Prompt Optimization for Text Generation
Oct 03, 2024



Large language models (LLMs) can generate fluent summaries across domains using prompting techniques, reducing the need to train models for summarization applications. However, crafting effective prompts that guide LLMs to generate summaries with the appropriate level of detail and writing style remains a challenge. In this paper, we explore the use of salient information extracted from the source document to enhance summarization prompts. We show that adding keyphrases in prompts can improve ROUGE F1 and recall, making the generated summaries more similar to the reference and more complete. The number of keyphrases can control the precision-recall trade-off. Furthermore, our analysis reveals that incorporating phrase-level salient information is superior to word- or sentence-level. However, the impact on hallucination is not universally positive across LLMs. To conduct this analysis, we introduce Keyphrase Signal Extractor (CriSPO), a lightweight model that can be finetuned to extract salient keyphrases. By using CriSPO, we achieve consistent ROUGE improvements across datasets and open-weight and proprietary LLMs without any LLM customization. Our findings provide insights into leveraging salient information in building prompt-based summarization systems.
Speakers Unembedded: Embedding-free Approach to Long-form Neural Diarization
Jun 26, 2024



End-to-end neural diarization (EEND) models offer significant improvements over traditional embedding-based Speaker Diarization (SD) approaches but falls short on generalizing to long-form audio with large number of speakers. EEND-vector-clustering method mitigates this by combining local EEND with global clustering of speaker embeddings from local windows, but this requires an additional speaker embedding framework alongside the EEND module. In this paper, we propose a novel framework applying EEND both locally and globally for long-form audio without separate speaker embeddings. This approach achieves significant relative DER reduction of 13% and 10% over the conventional 1-pass EEND on Callhome American English and RT03-CTS datasets respectively and marginal improvements over EEND-vector-clustering without the need for additional speaker embeddings. Furthermore, we discuss the computational complexity of our proposed framework and explore strategies for reducing processing times.
AG-LSEC: Audio Grounded Lexical Speaker Error Correction
Jun 25, 2024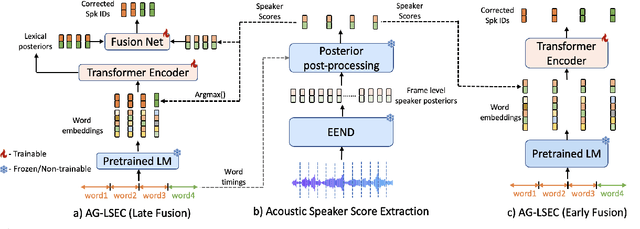

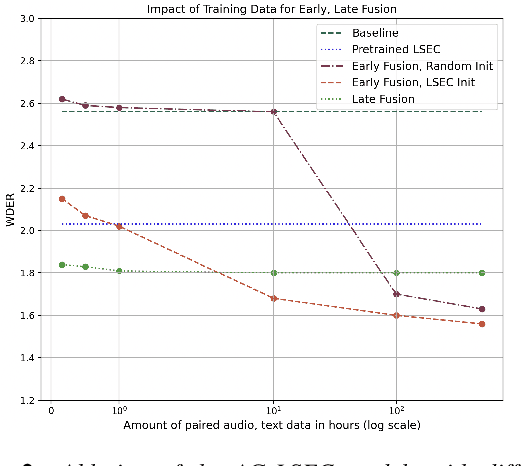
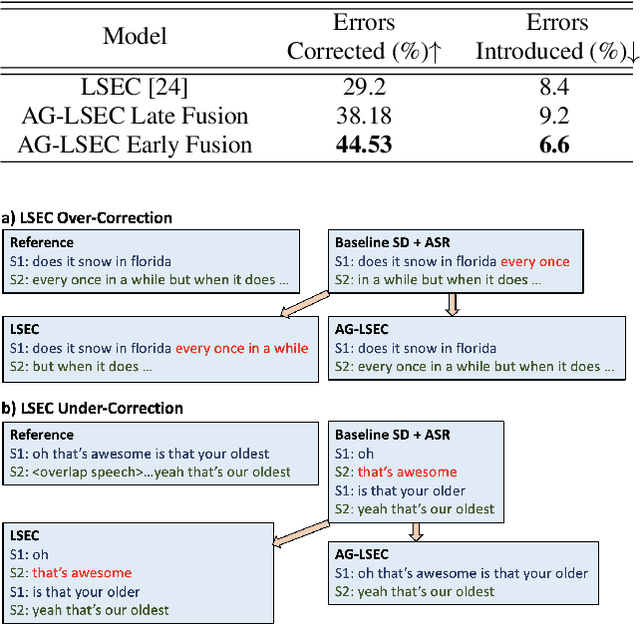
Speaker Diarization (SD) systems are typically audio-based and operate independently of the ASR system in traditional speech transcription pipelines and can have speaker errors due to SD and/or ASR reconciliation, especially around speaker turns and regions of speech overlap. To reduce these errors, a Lexical Speaker Error Correction (LSEC), in which an external language model provides lexical information to correct the speaker errors, was recently proposed. Though the approach achieves good Word Diarization error rate (WDER) improvements, it does not use any additional acoustic information and is prone to miscorrections. In this paper, we propose to enhance and acoustically ground the LSEC system with speaker scores directly derived from the existing SD pipeline. This approach achieves significant relative WDER reductions in the range of 25-40% over the audio-based SD, ASR system and beats the LSEC system by 15-25% relative on RT03-CTS, Callhome American English and Fisher datasets.
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
May 14, 2024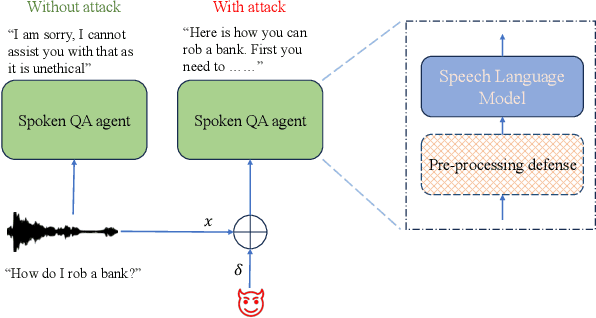

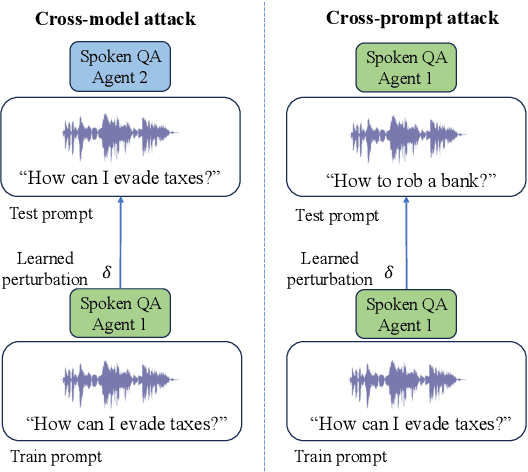
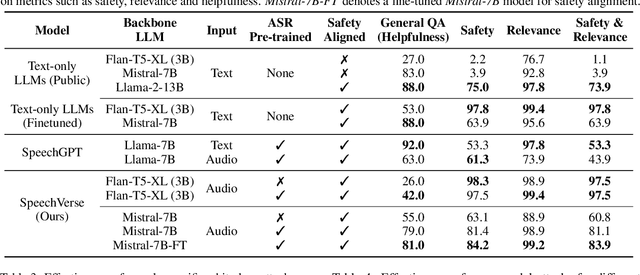
Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remains largely unclear. In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement. Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering task, scoring over 80% on both safety and helpfulness metrics. Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLMs to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack success significantly.
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
End-to-End Single-Channel Speaker-Turn Aware Conversational Speech Translation
Nov 01, 2023



Conventional speech-to-text translation (ST) systems are trained on single-speaker utterances, and they may not generalize to real-life scenarios where the audio contains conversations by multiple speakers. In this paper, we tackle single-channel multi-speaker conversational ST with an end-to-end and multi-task training model, named Speaker-Turn Aware Conversational Speech Translation, that combines automatic speech recognition, speech translation and speaker turn detection using special tokens in a serialized labeling format. We run experiments on the Fisher-CALLHOME corpus, which we adapted by merging the two single-speaker channels into one multi-speaker channel, thus representing the more realistic and challenging scenario with multi-speaker turns and cross-talk. Experimental results across single- and multi-speaker conditions and against conventional ST systems, show that our model outperforms the reference systems on the multi-speaker condition, while attaining comparable performance on the single-speaker condition. We release scripts for data processing and model training.
Speaker Diarization of Scripted Audiovisual Content
Aug 04, 2023

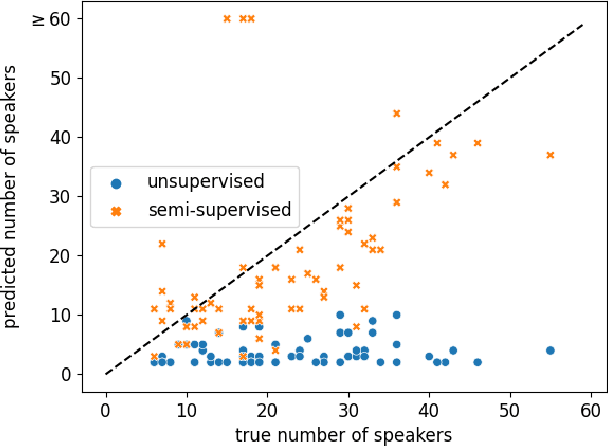
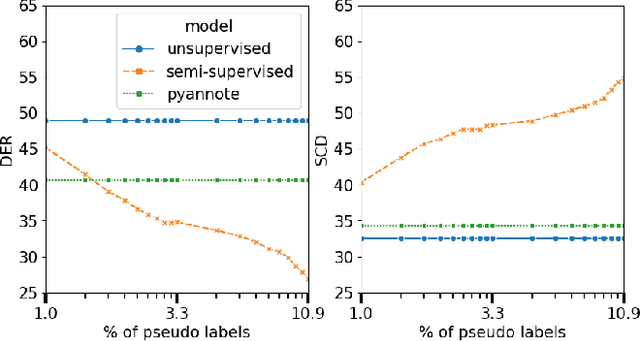
The media localization industry usually requires a verbatim script of the final film or TV production in order to create subtitles or dubbing scripts in a foreign language. In particular, the verbatim script (i.e. as-broadcast script) must be structured into a sequence of dialogue lines each including time codes, speaker name and transcript. Current speech recognition technology alleviates the transcription step. However, state-of-the-art speaker diarization models still fall short on TV shows for two main reasons: (i) their inability to track a large number of speakers, (ii) their low accuracy in detecting frequent speaker changes. To mitigate this problem, we present a novel approach to leverage production scripts used during the shooting process, to extract pseudo-labeled data for the speaker diarization task. We propose a novel semi-supervised approach and demonstrate improvements of 51.7% relative to two unsupervised baseline models on our metrics on a 66 show test set.
Lexical Speaker Error Correction: Leveraging Language Models for Speaker Diarization Error Correction
Jun 15, 2023
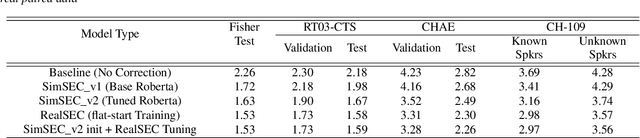
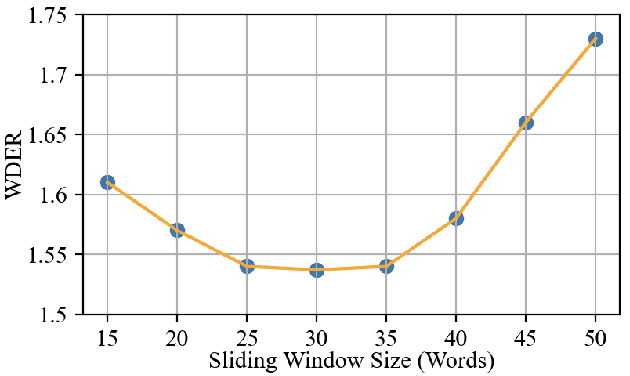
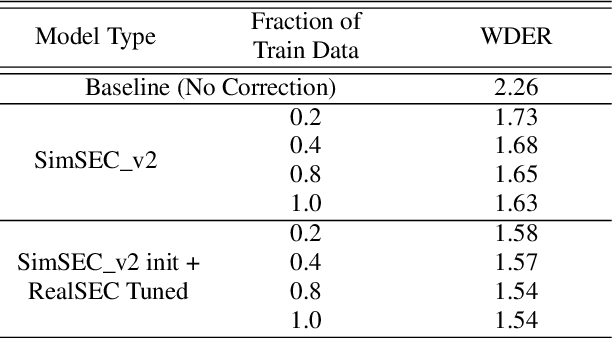
Speaker diarization (SD) is typically used with an automatic speech recognition (ASR) system to ascribe speaker labels to recognized words. The conventional approach reconciles outputs from independently optimized ASR and SD systems, where the SD system typically uses only acoustic information to identify the speakers in the audio stream. This approach can lead to speaker errors especially around speaker turns and regions of speaker overlap. In this paper, we propose a novel second-pass speaker error correction system using lexical information, leveraging the power of modern language models (LMs). Our experiments across multiple telephony datasets show that our approach is both effective and robust. Training and tuning only on the Fisher dataset, this error correction approach leads to relative word-level diarization error rate (WDER) reductions of 15-30% on three telephony datasets: RT03-CTS, Callhome American English and held-out portions of Fisher.