 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-resource Speech Translation and Recognition with LLMs
Dec 24, 2024


Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable to achieve BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2\%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
Towards Effective GenAI Multi-Agent Collaboration: Design and Evaluation for Enterprise Applications
Dec 06, 2024AI agents powered by large language models (LLMs) have shown strong capabilities in problem solving. Through combining many intelligent agents, multi-agent collaboration has emerged as a promising approach to tackle complex, multi-faceted problems that exceed the capabilities of single AI agents. However, designing the collaboration protocols and evaluating the effectiveness of these systems remains a significant challenge, especially for enterprise applications. This report addresses these challenges by presenting a comprehensive evaluation of coordination and routing capabilities in a novel multi-agent collaboration framework. We evaluate two key operational modes: (1) a coordination mode enabling complex task completion through parallel communication and payload referencing, and (2) a routing mode for efficient message forwarding between agents. We benchmark on a set of handcrafted scenarios from three enterprise domains, which are publicly released with the report. For coordination capabilities, we demonstrate the effectiveness of inter-agent communication and payload referencing mechanisms, achieving end-to-end goal success rates of 90%. Our analysis yields several key findings: multi-agent collaboration enhances goal success rates by up to 70% compared to single-agent approaches in our benchmarks; payload referencing improves performance on code-intensive tasks by 23%; latency can be substantially reduced with a routing mechanism that selectively bypasses agent orchestration. These findings offer valuable guidance for enterprise deployments of multi-agent systems and advance the development of scalable, efficient multi-agent collaboration frameworks.
RoundTable: Investigating Group Decision-Making Mechanism in Multi-Agent Collaboration
Nov 11, 2024This study investigates the efficacy of Multi-Agent Systems in eliciting cross-agent communication and enhancing collective intelligence through group decision-making in a decentralized setting. Unlike centralized mechanisms, where a fixed hierarchy governs social choice, decentralized group decision-making allows agents to engage in joint deliberation. Our research focuses on the dynamics of communication and decision-making within various social choice methods. By applying different voting rules in various environments, we find that moderate decision flexibility yields better outcomes. Additionally, exploring the linguistic features of agent-to-agent conversations reveals indicators of effective collaboration, offering insights into communication patterns that facilitate or hinder collaboration. Finally, we propose various methods for determining the optimal stopping point in multi-agent collaborations based on linguistic cues. Our findings contribute to a deeper understanding of how decentralized decision-making and group conversation shape multi-agent collaboration, with implications for the design of more effective MAS environments.
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
May 14, 2024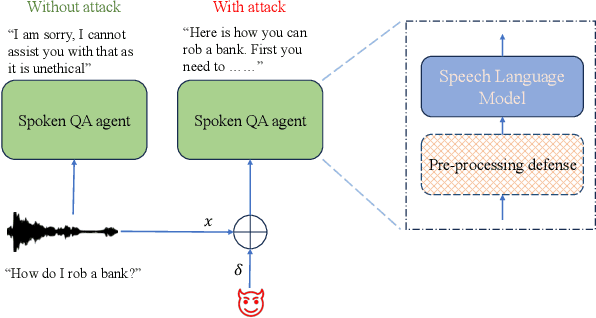

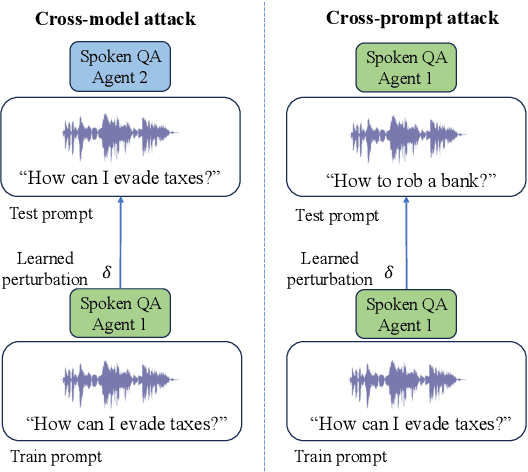
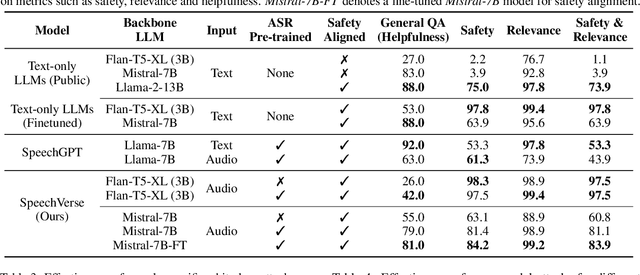
Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remains largely unclear. In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement. Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering task, scoring over 80% on both safety and helpfulness metrics. Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLMs to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack success significantly.
Mask The Bias: Improving Domain-Adaptive Generalization of CTC-based ASR with Internal Language Model Estimation
May 05, 2023
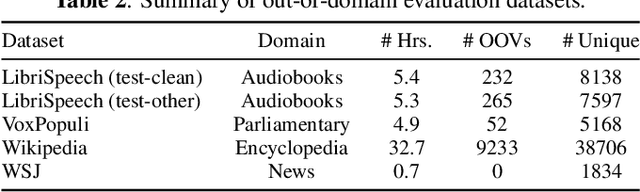
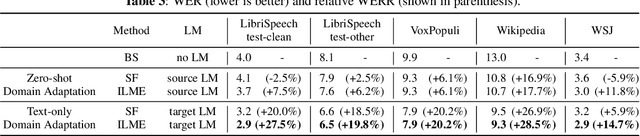
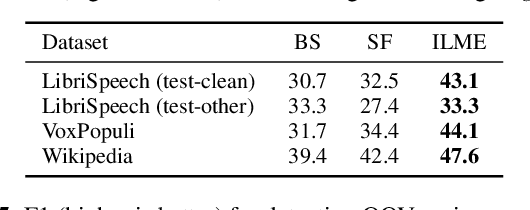
End-to-end ASR models trained on large amount of data tend to be implicitly biased towards language semantics of the training data. Internal language model estimation (ILME) has been proposed to mitigate this bias for autoregressive models such as attention-based encoder-decoder and RNN-T. Typically, ILME is performed by modularizing the acoustic and language components of the model architecture, and eliminating the acoustic input to perform log-linear interpolation with the text-only posterior. However, for CTC-based ASR, it is not as straightforward to decouple the model into such acoustic and language components, as CTC log-posteriors are computed in a non-autoregressive manner. In this work, we propose a novel ILME technique for CTC-based ASR models. Our method iteratively masks the audio timesteps to estimate a pseudo log-likelihood of the internal LM by accumulating log-posteriors for only the masked timesteps. Extensive evaluation across multiple out-of-domain datasets reveals that the proposed approach improves WER by up to 9.8% and OOV F1-score by up to 24.6% relative to Shallow Fusion, when only text data from target domain is available. In the case of zero-shot domain adaptation, with no access to any target domain data, we demonstrate that removing the source domain bias with ILME can still outperform Shallow Fusion to improve WER by up to 9.3% relative.
NeuroMapper: In-browser Visualizer for Neural Network Training
Oct 22, 2022
We present our ongoing work NeuroMapper, an in-browser visualization tool that helps machine learning (ML) developers interpret the evolution of a model during training, providing a new way to monitor the training process and visually discover reasons for suboptimal training. While most existing deep neural networks (DNNs) interpretation tools are designed for already-trained model, NeuroMapper scalably visualizes the evolution of the embeddings of a model's blocks across training epochs, enabling real-time visualization of 40,000 embedded points. To promote the embedding visualizations' spatial coherence across epochs, NeuroMapper adapts AlignedUMAP, a recent nonlinear dimensionality reduction technique to align the embeddings. With NeuroMapper, users can explore the training dynamics of a Resnet-50 model, and adjust the embedding visualizations' parameters in real time. NeuroMapper is open-sourced at https://github.com/poloclub/NeuroMapper and runs in all modern web browsers. A demo of the tool in action is available at: https://poloclub.github.io/NeuroMapper/.
Hear No Evil: Towards Adversarial Robustness of Automatic Speech Recognition via Multi-Task Learning
Apr 05, 2022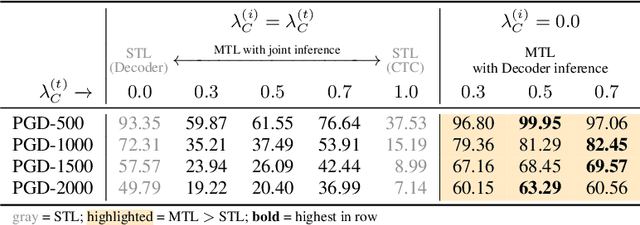
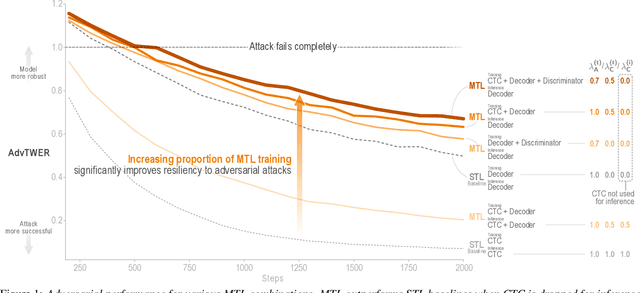
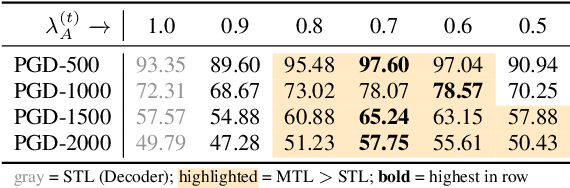
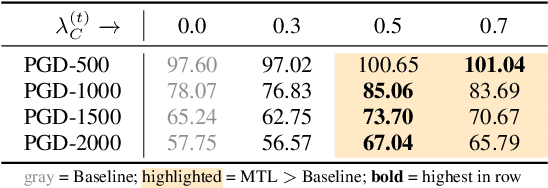
As automatic speech recognition (ASR) systems are now being widely deployed in the wild, the increasing threat of adversarial attacks raises serious questions about the security and reliability of using such systems. On the other hand, multi-task learning (MTL) has shown success in training models that can resist adversarial attacks in the computer vision domain. In this work, we investigate the impact of performing such multi-task learning on the adversarial robustness of ASR models in the speech domain. We conduct extensive MTL experimentation by combining semantically diverse tasks such as accent classification and ASR, and evaluate a wide range of adversarial settings. Our thorough analysis reveals that performing MTL with semantically diverse tasks consistently makes it harder for an adversarial attack to succeed. We also discuss in detail the serious pitfalls and their related remedies that have a significant impact on the robustness of MTL models. Our proposed MTL approach shows considerable absolute improvements in adversarially targeted WER ranging from 17.25 up to 59.90 compared to single-task learning baselines (attention decoder and CTC respectively). Ours is the first in-depth study that uncovers adversarial robustness gains from multi-task learning for ASR.
SkeleVision: Towards Adversarial Resiliency of Person Tracking with Multi-Task Learning
Apr 02, 2022

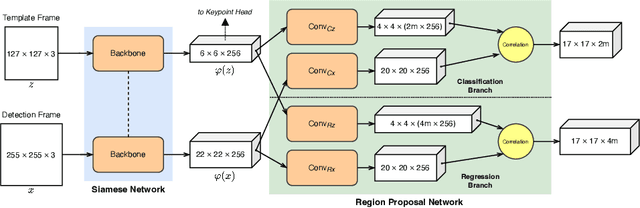

Person tracking using computer vision techniques has wide ranging applications such as autonomous driving, home security and sports analytics. However, the growing threat of adversarial attacks raises serious concerns regarding the security and reliability of such techniques. In this work, we study the impact of multi-task learning (MTL) on the adversarial robustness of the widely used SiamRPN tracker, in the context of person tracking. Specifically, we investigate the effect of jointly learning with semantically analogous tasks of person tracking and human keypoint detection. We conduct extensive experiments with more powerful adversarial attacks that can be physically realizable, demonstrating the practical value of our approach. Our empirical study with simulated as well as real-world datasets reveals that training with MTL consistently makes it harder to attack the SiamRPN tracker, compared to typically training only on the single task of person tracking.
ConceptEvo: Interpreting Concept Evolution in Deep Learning Training
Mar 30, 2022



Deep neural networks (DNNs) have been widely used for decision making, prompting a surge of interest in interpreting how these complex models work. Recent literature on DNN interpretation has revolved around already-trained models; however, much less research focuses on interpreting how the models evolve as they are trained. Interpreting model evolution is crucial to monitor network training and can aid proactive decisions about necessary interventions. In this work, we present ConceptEvo, a general interpretation framework for DNNs that reveals the inception and evolution of detected concepts during training. Through a large-scale human evaluation with 260 participants and quantitative experiments, we show that ConceptEvo discovers evolution across different models that are meaningful to humans, helpful for early-training intervention decisions, and crucial to the prediction for a given class.