 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-Mem: A Dual-Process Memory System for LLM Agents
Mar 19, 2026Driven by the development of persistent, self-adapting autonomous agents, equipping these systems with high-fidelity memory access for long-horizon reasoning has emerged as a critical requirement. However, prevalent retrieval-based memory frameworks often follow an incremental processing paradigm that continuously extracts and updates conversational memories into vector databases, relying on semantic retrieval when queried. While this approach is fast, it inherently relies on lossy abstraction, frequently missing contextually critical information and struggling to resolve queries that rely on fine-grained contextual understanding. To address this, we introduce D-Mem, a dual-process memory system. It retains lightweight vector retrieval for routine queries while establishing an exhaustive Full Deliberation module as a high-fidelity fallback. To achieve cognitive economy without sacrificing accuracy, D-Mem employs a Multi-dimensional Quality Gating policy to dynamically bridge these two processes. Experiments on the LoCoMo and RealTalk benchmarks using GPT-4o-mini and Qwen3-235B-Instruct demonstrate the efficacy of our approach. Notably, our Multi-dimensional Quality Gating policy achieves an F1 score of 53.5 on LoCoMo with GPT-4o-mini. This outperforms our static retrieval baseline, Mem0$^\ast$ (51.2), and recovers 96.7\% of the Full Deliberation's performance (55.3), while incurring significantly lower computational costs.
Controllable Conversational Theme Detection Track at DSTC 12
Aug 26, 2025Conversational analytics has been on the forefront of transformation driven by the advances in Speech and Natural Language Processing techniques. Rapid adoption of Large Language Models (LLMs) in the analytics field has taken the problems that can be automated to a new level of complexity and scale. In this paper, we introduce Theme Detection as a critical task in conversational analytics, aimed at automatically identifying and categorizing topics within conversations. This process can significantly reduce the manual effort involved in analyzing expansive dialogs, particularly in domains like customer support or sales. Unlike traditional dialog intent detection, which often relies on a fixed set of intents for downstream system logic, themes are intended as a direct, user-facing summary of the conversation's core inquiry. This distinction allows for greater flexibility in theme surface forms and user-specific customizations. We pose Controllable Conversational Theme Detection problem as a public competition track at Dialog System Technology Challenge (DSTC) 12 -- it is framed as joint clustering and theme labeling of dialog utterances, with the distinctive aspect being controllability of the resulting theme clusters' granularity achieved via the provided user preference data. We give an overview of the problem, the associated dataset and the evaluation metrics, both automatic and human. Finally, we discuss the participant teams' submissions and provide insights from those. The track materials (data and code) are openly available in the GitHub repository.
MemInsight: Autonomous Memory Augmentation for LLM Agents
Mar 27, 2025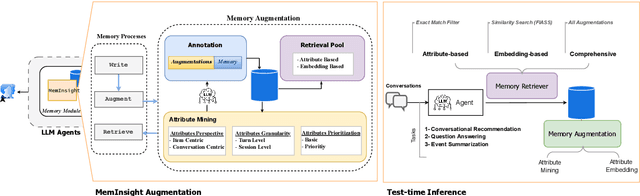
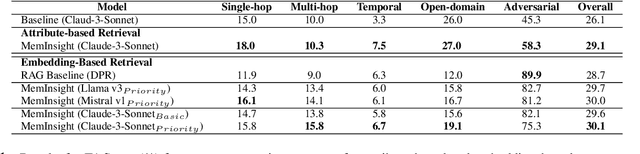
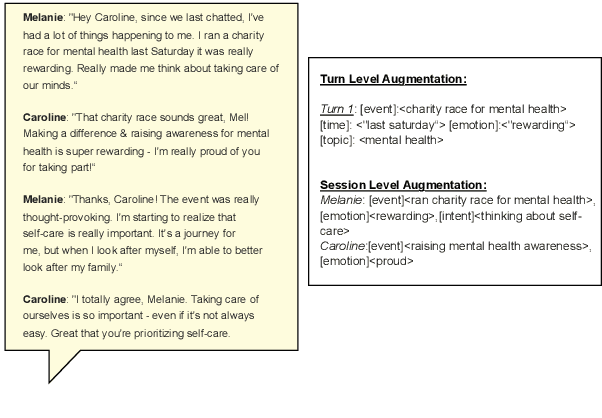

Large language model (LLM) agents have evolved to intelligently process information, make decisions, and interact with users or tools. A key capability is the integration of long-term memory capabilities, enabling these agents to draw upon historical interactions and knowledge. However, the growing memory size and need for semantic structuring pose significant challenges. In this work, we propose an autonomous memory augmentation approach, MemInsight, to enhance semantic data representation and retrieval mechanisms. By leveraging autonomous augmentation to historical interactions, LLM agents are shown to deliver more accurate and contextualized responses. We empirically validate the efficacy of our proposed approach in three task scenarios; conversational recommendation, question answering and event summarization. On the LLM-REDIAL dataset, MemInsight boosts persuasiveness of recommendations by up to 14%. Moreover, it outperforms a RAG baseline by 34% in recall for LoCoMo retrieval. Our empirical results show the potential of MemInsight to enhance the contextual performance of LLM agents across multiple tasks.
ReFeed: Multi-dimensional Summarization Refinement with Reflective Reasoning on Feedback
Mar 27, 2025Summarization refinement faces challenges when extending to multi-dimension. In this paper, we introduce ReFeed, a powerful summarization refinement pipeline that enhances multiple dimensions through reflective reasoning on feedback. To achieve this, we release SumFeed-CoT, a large-scale Long-CoT-based dataset optimized for training a lightweight model with reflective reasoning. Our experiments reveal how the number of dimensions, feedback exposure, and reasoning policy influence refinement performance, highlighting reflective reasoning and simultaneously addressing multiple feedback is crucial to mitigate trade-off between dimensions. Furthermore, ReFeed is robust to noisy feedback and feedback order. Lastly, our finding emphasizes that creating data with a proper goal and guideline constitutes a fundamental pillar of effective reasoning. The dataset and model will be released.
GLEAN: Generalized Category Discovery with Diverse and Quality-Enhanced LLM Feedback
Feb 25, 2025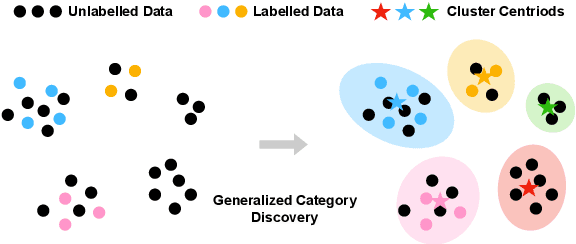
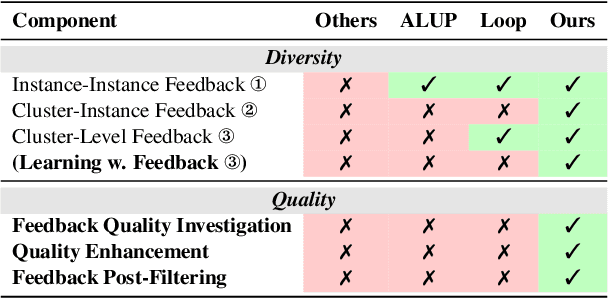
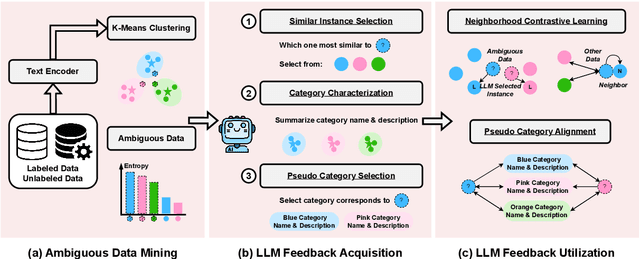
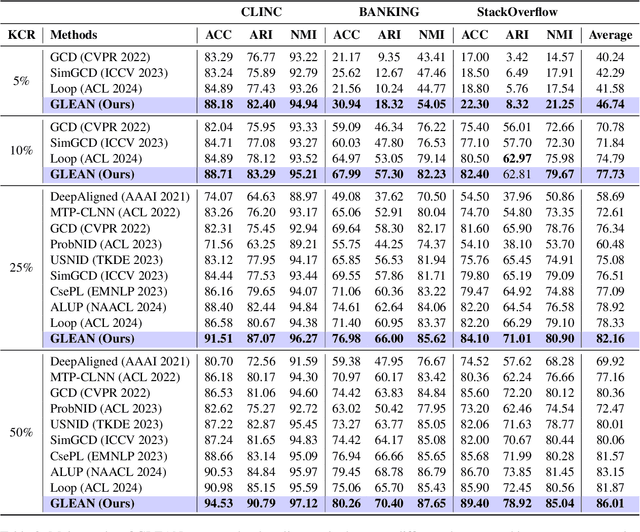
Generalized Category Discovery (GCD) is a practical and challenging open-world task that aims to recognize both known and novel categories in unlabeled data using limited labeled data from known categories. Due to the lack of supervision, previous GCD methods face significant challenges, such as difficulty in rectifying errors for confusing instances, and inability to effectively uncover and leverage the semantic meanings of discovered clusters. Therefore, additional annotations are usually required for real-world applicability. However, human annotation is extremely costly and inefficient. To address these issues, we propose GLEAN, a unified framework for generalized category discovery that actively learns from diverse and quality-enhanced LLM feedback. Our approach leverages three different types of LLM feedback to: (1) improve instance-level contrastive features, (2) generate category descriptions, and (3) align uncertain instances with LLM-selected category descriptions. Extensive experiments demonstrate the superior performance of \MethodName over state-of-the-art models across diverse datasets, metrics, and supervision settings. Our code is available at https://github.com/amazon-science/Glean.
TReMu: Towards Neuro-Symbolic Temporal Reasoning for LLM-Agents with Memory in Multi-Session Dialogues
Feb 03, 2025

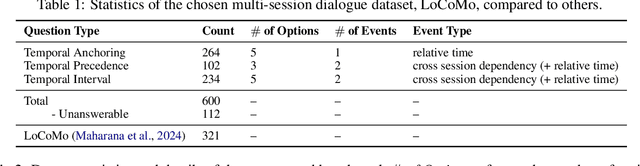
Temporal reasoning in multi-session dialogues presents a significant challenge which has been under-studied in previous temporal reasoning benchmarks. To bridge this gap, we propose a new evaluation task for temporal reasoning in multi-session dialogues and introduce an approach to construct a new benchmark by augmenting dialogues from LoCoMo and creating multi-choice QAs. Furthermore, we present TReMu, a new framework aimed at enhancing the temporal reasoning capabilities of LLM-agents in this context. Specifically, the framework employs \textit{time-aware memorization} through timeline summarization, generating retrievable memory by summarizing events in each dialogue session with their inferred dates. Additionally, we integrate \textit{neuro-symbolic temporal reasoning}, where LLMs generate Python code to perform temporal calculations and select answers. Experimental evaluations on popular LLMs demonstrate that our benchmark is challenging, and the proposed framework significantly improves temporal reasoning performance compared to baseline methods, raising from 29.83 on GPT-4o via standard prompting to 77.67 via our approach and highlighting its effectiveness in addressing temporal reasoning in multi-session dialogues.
RoundTable: Investigating Group Decision-Making Mechanism in Multi-Agent Collaboration
Nov 11, 2024This study investigates the efficacy of Multi-Agent Systems in eliciting cross-agent communication and enhancing collective intelligence through group decision-making in a decentralized setting. Unlike centralized mechanisms, where a fixed hierarchy governs social choice, decentralized group decision-making allows agents to engage in joint deliberation. Our research focuses on the dynamics of communication and decision-making within various social choice methods. By applying different voting rules in various environments, we find that moderate decision flexibility yields better outcomes. Additionally, exploring the linguistic features of agent-to-agent conversations reveals indicators of effective collaboration, offering insights into communication patterns that facilitate or hinder collaboration. Finally, we propose various methods for determining the optimal stopping point in multi-agent collaborations based on linguistic cues. Our findings contribute to a deeper understanding of how decentralized decision-making and group conversation shape multi-agent collaboration, with implications for the design of more effective MAS environments.
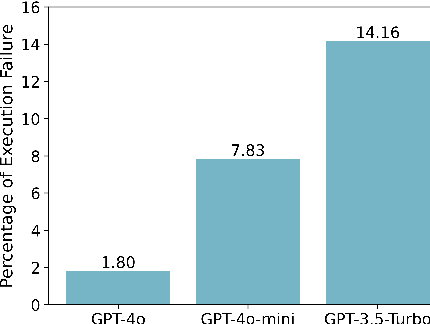
Learning to Summarize from LLM-generated Feedback
Oct 17, 2024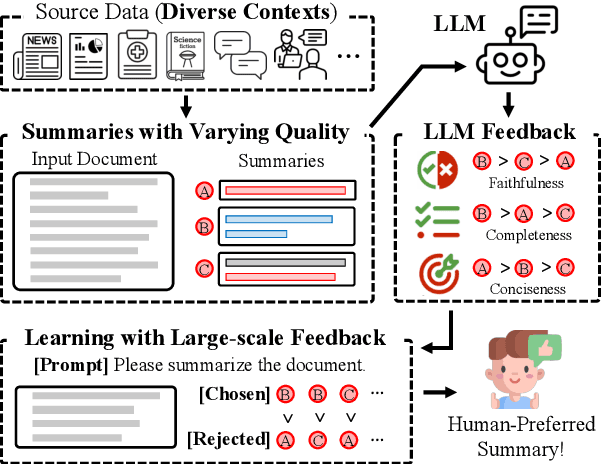


Developing effective text summarizers remains a challenge due to issues like hallucinations, key information omissions, and verbosity in LLM-generated summaries. This work explores using LLM-generated feedback to improve summary quality by aligning the summaries with human preferences for faithfulness, completeness, and conciseness. We introduce FeedSum, a large-scale dataset containing multi-dimensional LLM feedback on summaries of varying quality across diverse domains. Our experiments show how feedback quality, dimensionality, and granularity influence preference learning, revealing that high-quality, multi-dimensional, fine-grained feedback significantly improves summary generation. We also compare two methods for using this feedback: supervised fine-tuning and direct preference optimization. Finally, we introduce SummLlama3-8b, a model that outperforms the nearly 10x larger Llama3-70b-instruct in generating human-preferred summaries, demonstrating that smaller models can achieve superior performance with appropriate training. The full dataset will be released soon. The SummLlama3-8B model is now available at https://huggingface.co/DISLab/SummLlama3-8B.
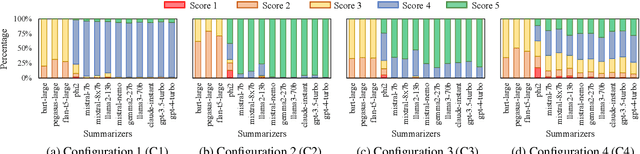
UniSumEval: Towards Unified, Fine-Grained, Multi-Dimensional Summarization Evaluation for LLMs
Sep 30, 2024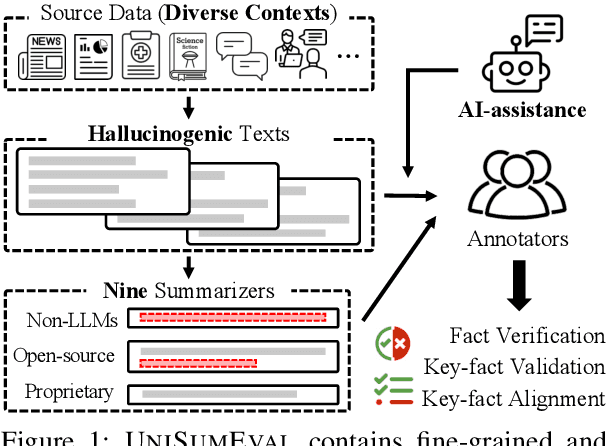
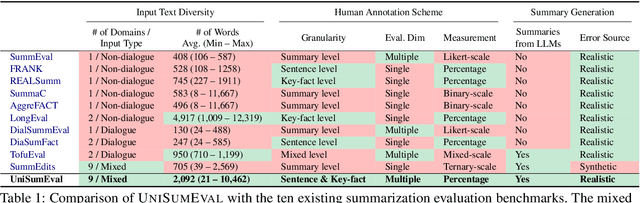
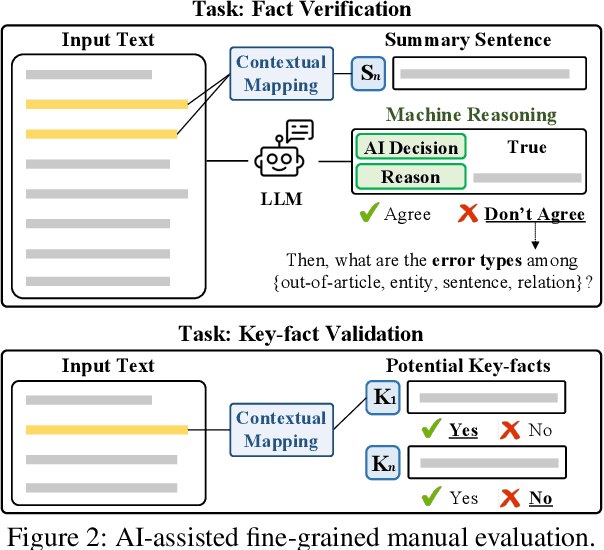

Existing benchmarks for summarization quality evaluation often lack diverse input scenarios, focus on narrowly defined dimensions (e.g., faithfulness), and struggle with subjective and coarse-grained annotation schemes. To address these shortcomings, we create UniSumEval benchmark, which extends the range of input context (e.g., domain, length) and provides fine-grained, multi-dimensional annotations. We use AI assistance in data creation, identifying potentially hallucinogenic input texts, and also helping human annotators reduce the difficulty of fine-grained annotation tasks. With UniSumEval, we benchmark nine latest language models as summarizers, offering insights into their performance across varying input contexts and evaluation dimensions. Furthermore, we conduct a thorough comparison of SOTA automated summary evaluators. Our benchmark data will be available at https://github.com/DISL-Lab/UniSumEval-v1.0.
Fine-grained, Multi-dimensional Summarization Evaluation with LLMs
Jul 09, 2024



Automated evaluation is crucial for streamlining text summarization benchmarking and model development, given the costly and time-consuming nature of human evaluation. Traditional methods like ROUGE do not correlate well with human judgment, while recently proposed LLM-based metrics provide only summary-level assessment using Likert-scale scores. This limits deeper model analysis, e.g., we can only assign one hallucination score at the summary level, while at the sentence level, we can count sentences containing hallucinations. To remedy those limitations, we propose FineSurE, a fine-grained evaluator specifically tailored for the summarization task using large language models (LLMs). It also employs completeness and conciseness criteria, in addition to faithfulness, enabling multi-dimensional assessment. We compare various open-source and proprietary LLMs as backbones for FineSurE. In addition, we conduct extensive benchmarking of FineSurE against SOTA methods including NLI-, QA-, and LLM-based methods, showing improved performance especially on the completeness and conciseness dimensions. The code is available at https://github.com/DISL-Lab/FineSurE-ACL24.