 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Conversational Theme Detection Track at DSTC 12
Aug 26, 2025Conversational analytics has been on the forefront of transformation driven by the advances in Speech and Natural Language Processing techniques. Rapid adoption of Large Language Models (LLMs) in the analytics field has taken the problems that can be automated to a new level of complexity and scale. In this paper, we introduce Theme Detection as a critical task in conversational analytics, aimed at automatically identifying and categorizing topics within conversations. This process can significantly reduce the manual effort involved in analyzing expansive dialogs, particularly in domains like customer support or sales. Unlike traditional dialog intent detection, which often relies on a fixed set of intents for downstream system logic, themes are intended as a direct, user-facing summary of the conversation's core inquiry. This distinction allows for greater flexibility in theme surface forms and user-specific customizations. We pose Controllable Conversational Theme Detection problem as a public competition track at Dialog System Technology Challenge (DSTC) 12 -- it is framed as joint clustering and theme labeling of dialog utterances, with the distinctive aspect being controllability of the resulting theme clusters' granularity achieved via the provided user preference data. We give an overview of the problem, the associated dataset and the evaluation metrics, both automatic and human. Finally, we discuss the participant teams' submissions and provide insights from those. The track materials (data and code) are openly available in the GitHub repository.
GLEAN: Generalized Category Discovery with Diverse and Quality-Enhanced LLM Feedback
Feb 25, 2025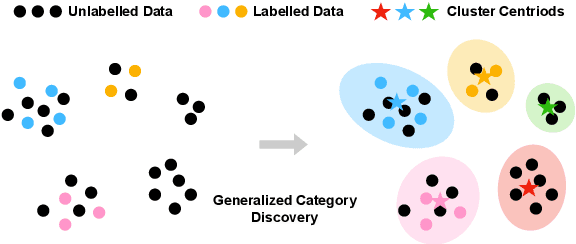
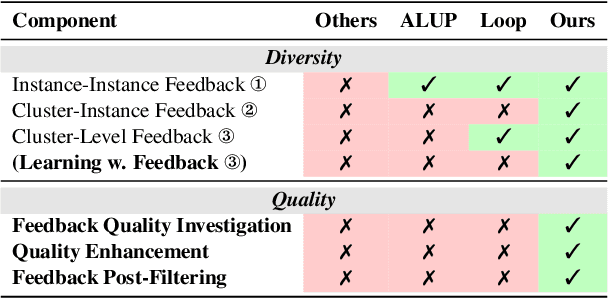
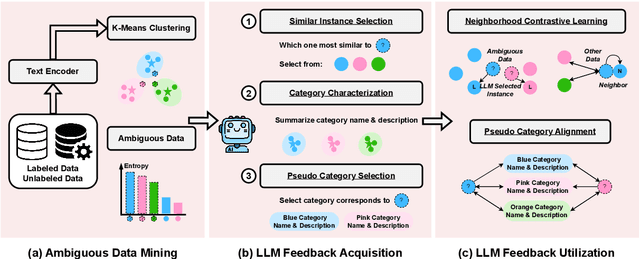
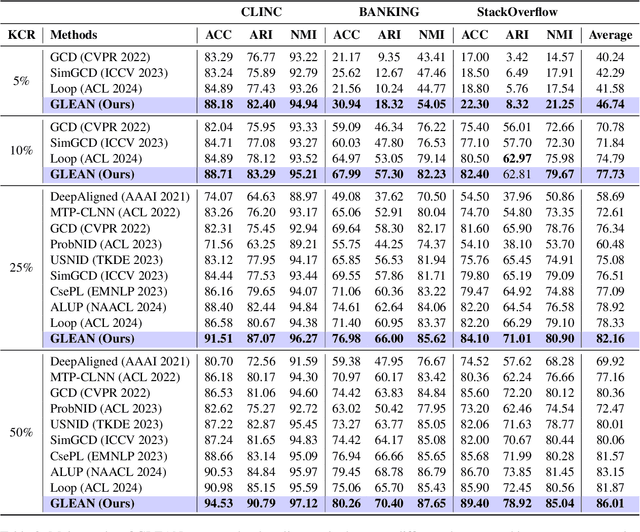
Generalized Category Discovery (GCD) is a practical and challenging open-world task that aims to recognize both known and novel categories in unlabeled data using limited labeled data from known categories. Due to the lack of supervision, previous GCD methods face significant challenges, such as difficulty in rectifying errors for confusing instances, and inability to effectively uncover and leverage the semantic meanings of discovered clusters. Therefore, additional annotations are usually required for real-world applicability. However, human annotation is extremely costly and inefficient. To address these issues, we propose GLEAN, a unified framework for generalized category discovery that actively learns from diverse and quality-enhanced LLM feedback. Our approach leverages three different types of LLM feedback to: (1) improve instance-level contrastive features, (2) generate category descriptions, and (3) align uncertain instances with LLM-selected category descriptions. Extensive experiments demonstrate the superior performance of \MethodName over state-of-the-art models across diverse datasets, metrics, and supervision settings. Our code is available at https://github.com/amazon-science/Glean.
Can Your Model Tell a Negation from an Implicature? Unravelling Challenges With Intent Encoders
Mar 07, 2024



Conversational systems often rely on embedding models for intent classification and intent clustering tasks. The advent of Large Language Models (LLMs), which enable instructional embeddings allowing one to adjust semantics over the embedding space using prompts, are being viewed as a panacea for these downstream conversational tasks. However, traditional evaluation benchmarks rely solely on task metrics that don't particularly measure gaps related to semantic understanding. Thus, we propose an intent semantic toolkit that gives a more holistic view of intent embedding models by considering three tasks -- (1) intent classification, (2) intent clustering, and (3) a novel triplet task. The triplet task gauges the model's understanding of two semantic concepts paramount in real-world conversational systems -- negation and implicature. We observe that current embedding models fare poorly in semantic understanding of these concepts. To address this, we propose a pre-training approach to improve the embedding model by leveraging augmentation with data generated by an auto-regressive model and a contrastive loss term. Our approach improves the semantic understanding of the intent embedding model on the aforementioned linguistic dimensions while slightly effecting their performance on downstream task metrics.
MAGID: An Automated Pipeline for Generating Synthetic Multi-modal Datasets
Mar 05, 2024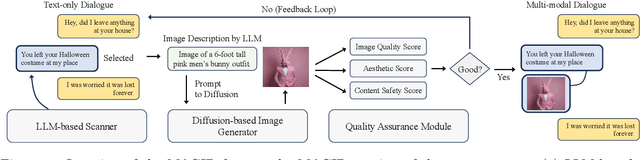



Development of multimodal interactive systems is hindered by the lack of rich, multimodal (text, images) conversational data, which is needed in large quantities for LLMs. Previous approaches augment textual dialogues with retrieved images, posing privacy, diversity, and quality constraints. In this work, we introduce \textbf{M}ultimodal \textbf{A}ugmented \textbf{G}enerative \textbf{I}mages \textbf{D}ialogues (MAGID), a framework to augment text-only dialogues with diverse and high-quality images. Subsequently, a diffusion model is applied to craft corresponding images, ensuring alignment with the identified text. Finally, MAGID incorporates an innovative feedback loop between an image description generation module (textual LLM) and image quality modules (addressing aesthetics, image-text matching, and safety), that work in tandem to generate high-quality and multi-modal dialogues. We compare MAGID to other SOTA baselines on three dialogue datasets, using automated and human evaluation. Our results show that MAGID is comparable to or better than baselines, with significant improvements in human evaluation, especially against retrieval baselines where the image database is small.
TofuEval: Evaluating Hallucinations of LLMs on Topic-Focused Dialogue Summarization
Feb 20, 2024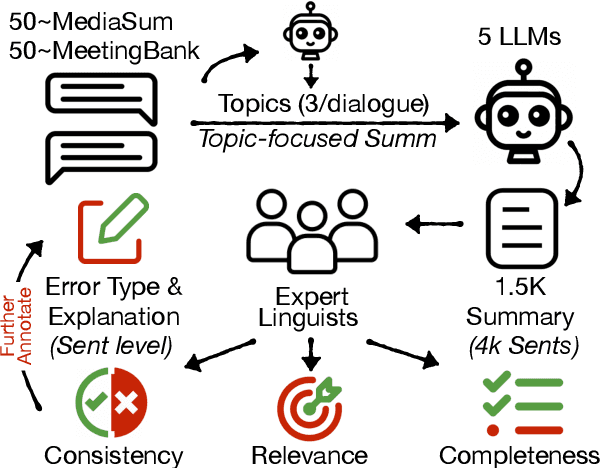


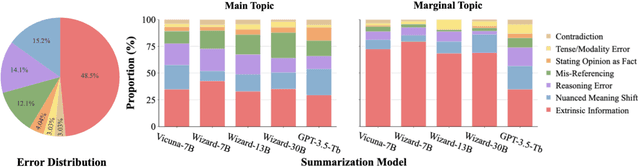
Single document news summarization has seen substantial progress on faithfulness in recent years, driven by research on the evaluation of factual consistency, or hallucinations. We ask whether these advances carry over to other text summarization domains. We propose a new evaluation benchmark on topic-focused dialogue summarization, generated by LLMs of varying sizes. We provide binary sentence-level human annotations of the factual consistency of these summaries along with detailed explanations of factually inconsistent sentences. Our analysis shows that existing LLMs hallucinate significant amounts of factual errors in the dialogue domain, regardless of the model's size. On the other hand, when LLMs, including GPT-4, serve as binary factual evaluators, they perform poorly and can be outperformed by prevailing state-of-the-art specialized factuality evaluation metrics. Finally, we conducted an analysis of hallucination types with a curated error taxonomy. We find that there are diverse errors and error distributions in model-generated summaries and that non-LLM based metrics can capture all error types better than LLM-based evaluators.
Enhancing Abstractiveness of Summarization Models through Calibrated Distillation
Oct 20, 2023



Sequence-level knowledge distillation reduces the size of Seq2Seq models for more efficient abstractive summarization. However, it often leads to a loss of abstractiveness in summarization. In this paper, we propose a novel approach named DisCal to enhance the level of abstractiveness (measured by n-gram overlap) without sacrificing the informativeness (measured by ROUGE) of generated summaries. DisCal exposes diverse pseudo summaries with two supervision to the student model. Firstly, the best pseudo summary is identified in terms of abstractiveness and informativeness and used for sequence-level distillation. Secondly, their ranks are used to ensure the student model to assign higher prediction scores to summaries with higher ranks. Our experiments show that DisCal outperforms prior methods in abstractive summarization distillation, producing highly abstractive and informative summaries.
SWING: Balancing Coverage and Faithfulness for Dialogue Summarization
Jan 25, 2023Missing information is a common issue of dialogue summarization where some information in the reference summaries is not covered in the generated summaries. To address this issue, we propose to utilize natural language inference (NLI) models to improve coverage while avoiding introducing factual inconsistencies. Specifically, we use NLI to compute fine-grained training signals to encourage the model to generate content in the reference summaries that have not been covered, as well as to distinguish between factually consistent and inconsistent generated sentences. Experiments on the DialogSum and SAMSum datasets confirm the effectiveness of the proposed approach in balancing coverage and faithfulness, validated with automatic metrics and human evaluations. Additionally, we compute the correlation between commonly used automatic metrics with human judgments in terms of three different dimensions regarding coverage and factual consistency to provide insight into the most suitable metric for evaluating dialogue summaries.
Relation Extraction from Tables using Artificially Generated Metadata
Sep 06, 2021
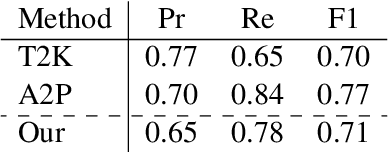
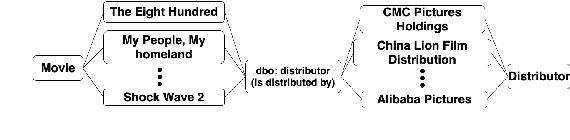

Relation Extraction (RE) from tables is the task of identifying relations between pairs of columns of a table. Generally, RE models for this task require labelled tables for training. These labelled tables can also be generated artificially from a Knowledge Graph (KG), which makes the cost to acquire them much lower in comparison to manual annotations. However, unlike real tables, these synthetic tables lack associated metadata, such as, column-headers, captions, etc; this is because synthetic tables are created out of KGs that do not store such metadata. Meanwhile, previous works have shown that metadata is important for accurate RE from tables. To address this issue, we propose methods to artificially create some of this metadata for synthetic tables. Afterward, we experiment with a BERT-based model, in line with recently published works, that takes as input a combination of proposed artificial metadata and table content. Our empirical results show that this leads to an improvement of 9\%-45\% in F1 score, in absolute terms, over 2 tabular datasets.