 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMMT-IF: A Challenging Multimodal Multi-Turn Instruction Following Benchmark
Sep 26, 2024



Evaluating instruction following capabilities for multimodal, multi-turn dialogue is challenging. With potentially multiple instructions in the input model context, the task is time-consuming for human raters and we show LLM based judges are biased towards answers from the same model. We propose MMMT-IF, an image based multi-turn Q$\&$A evaluation set with added global instructions between questions, constraining the answer format. This challenges models to retrieve instructions dispersed across long dialogues and reason under instruction constraints. All instructions are objectively verifiable through code execution. We introduce the Programmatic Instruction Following ($\operatorname{PIF}$) metric to measure the fraction of the instructions that are correctly followed while performing a reasoning task. The $\operatorname{PIF-N-K}$ set of metrics further evaluates robustness by measuring the fraction of samples in a corpus where, for each sample, at least K out of N generated model responses achieve a $\operatorname{PIF}$ score of one. The $\operatorname{PIF}$ metric aligns with human instruction following ratings, showing 60 percent correlation. Experiments show Gemini 1.5 Pro, GPT-4o, and Claude 3.5 Sonnet, have a $\operatorname{PIF}$ metric that drops from 0.81 on average at turn 1 across the models, to 0.64 at turn 20. Across all turns, when each response is repeated 4 times ($\operatorname{PIF-4-4}$), GPT-4o and Gemini successfully follow all instructions only $11\%$ of the time. When all the instructions are also appended to the end of the model input context, the $\operatorname{PIF}$ metric improves by 22.3 points on average, showing that the challenge with the task lies not only in following the instructions, but also in retrieving the instructions spread out in the model context. We plan to open source the MMMT-IF dataset and metric computation code.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Enhancing Abstractiveness of Summarization Models through Calibrated Distillation
Oct 20, 2023



Sequence-level knowledge distillation reduces the size of Seq2Seq models for more efficient abstractive summarization. However, it often leads to a loss of abstractiveness in summarization. In this paper, we propose a novel approach named DisCal to enhance the level of abstractiveness (measured by n-gram overlap) without sacrificing the informativeness (measured by ROUGE) of generated summaries. DisCal exposes diverse pseudo summaries with two supervision to the student model. Firstly, the best pseudo summary is identified in terms of abstractiveness and informativeness and used for sequence-level distillation. Secondly, their ranks are used to ensure the student model to assign higher prediction scores to summaries with higher ranks. Our experiments show that DisCal outperforms prior methods in abstractive summarization distillation, producing highly abstractive and informative summaries.
Switch-BERT: Learning to Model Multimodal Interactions by Switching Attention and Input
Jun 25, 2023The ability to model intra-modal and inter-modal interactions is fundamental in multimodal machine learning. The current state-of-the-art models usually adopt deep learning models with fixed structures. They can achieve exceptional performances on specific tasks, but face a particularly challenging problem of modality mismatch because of diversity of input modalities and their fixed structures. In this paper, we present \textbf{Switch-BERT} for joint vision and language representation learning to address this problem. Switch-BERT extends BERT architecture by introducing learnable layer-wise and cross-layer interactions. It learns to optimize attention from a set of attention modes representing these interactions. One specific property of the model is that it learns to attend outputs from various depths, therefore mitigates the modality mismatch problem. We present extensive experiments on visual question answering, image-text retrieval and referring expression comprehension experiments. Results confirm that, whereas alternative architectures including ViLBERT and UNITER may excel in particular tasks, Switch-BERT can consistently achieve better or comparable performances than the current state-of-the-art models in these tasks. Ablation studies indicate that the proposed model achieves superior performances due to its ability in learning task-specific multimodal interactions.
Zero-Shot End-to-End Spoken Language Understanding via Cross-Modal Selective Self-Training
May 22, 2023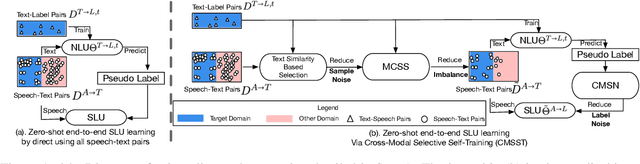
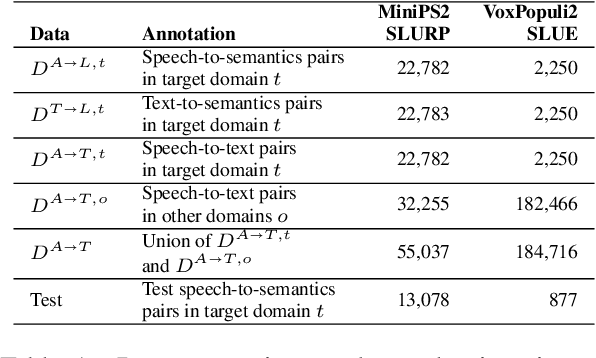
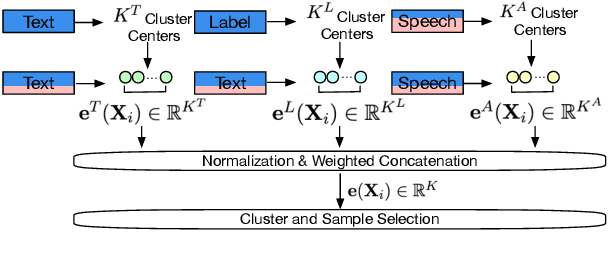
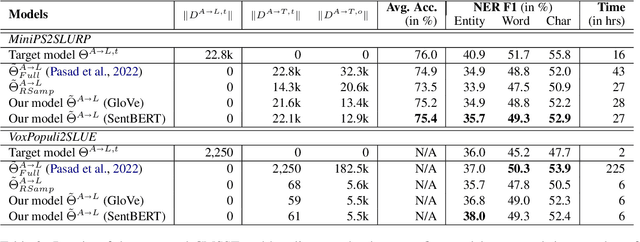
End-to-end (E2E) spoken language understanding (SLU) is constrained by the cost of collecting speech-semantics pairs, especially when label domains change. Hence, we explore \textit{zero-shot} E2E SLU, which learns E2E SLU without speech-semantics pairs, instead using only speech-text and text-semantics pairs. Previous work achieved zero-shot by pseudolabeling all speech-text transcripts with a natural language understanding (NLU) model learned on text-semantics corpora. However, this method requires the domains of speech-text and text-semantics to match, which often mismatch due to separate collections. Furthermore, using the entire speech-text corpus from any domains leads to \textit{imbalance} and \textit{noise} issues. To address these, we propose \textit{cross-modal selective self-training} (CMSST). CMSST tackles imbalance by clustering in a joint space of the three modalities (speech, text, and semantics) and handles label noise with a selection network. We also introduce two benchmarks for zero-shot E2E SLU, covering matched and found speech (mismatched) settings. Experiments show that CMSST improves performance in both two settings, with significantly reduced sample sizes and training time.
Neural Sequence Segmentation as Determining the Leftmost Segments
Apr 15, 2021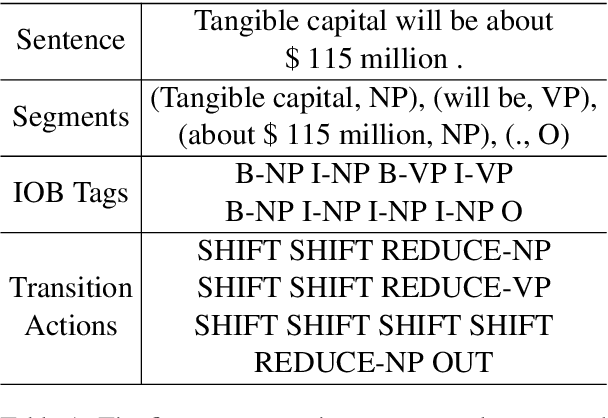

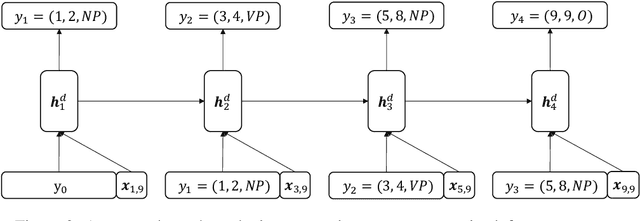
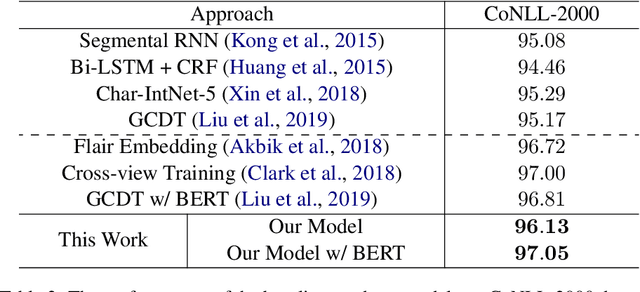
Prior methods to text segmentation are mostly at token level. Despite the adequacy, this nature limits their full potential to capture the long-term dependencies among segments. In this work, we propose a novel framework that incrementally segments natural language sentences at segment level. For every step in segmentation, it recognizes the leftmost segment of the remaining sequence. Implementations involve LSTM-minus technique to construct the phrase representations and recurrent neural networks (RNN) to model the iterations of determining the leftmost segments. We have conducted extensive experiments on syntactic chunking and Chinese part-of-speech (POS) tagging across 3 datasets, demonstrating that our methods have significantly outperformed previous all baselines and achieved new state-of-the-art results. Moreover, qualitative analysis and the study on segmenting long-length sentences verify its effectiveness in modeling long-term dependencies.
Interpretable NLG for Task-oriented Dialogue Systems with Heterogeneous Rendering Machines
Dec 29, 2020



End-to-end neural networks have achieved promising performances in natural language generation (NLG). However, they are treated as black boxes and lack interpretability. To address this problem, we propose a novel framework, heterogeneous rendering machines (HRM), that interprets how neural generators render an input dialogue act (DA) into an utterance. HRM consists of a renderer set and a mode switcher. The renderer set contains multiple decoders that vary in both structure and functionality. For every generation step, the mode switcher selects an appropriate decoder from the renderer set to generate an item (a word or a phrase). To verify the effectiveness of our method, we have conducted extensive experiments on 5 benchmark datasets. In terms of automatic metrics (e.g., BLEU), our model is competitive with the current state-of-the-art method. The qualitative analysis shows that our model can interpret the rendering process of neural generators well. Human evaluation also confirms the interpretability of our proposed approach.
Rewriter-Evaluator Framework for Neural Machine Translation
Dec 14, 2020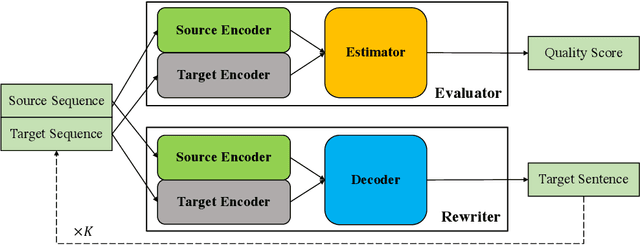
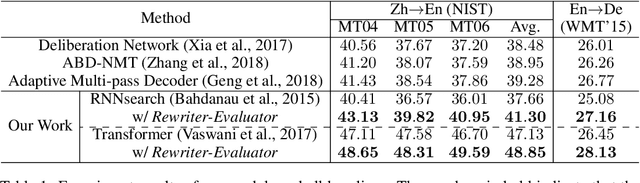
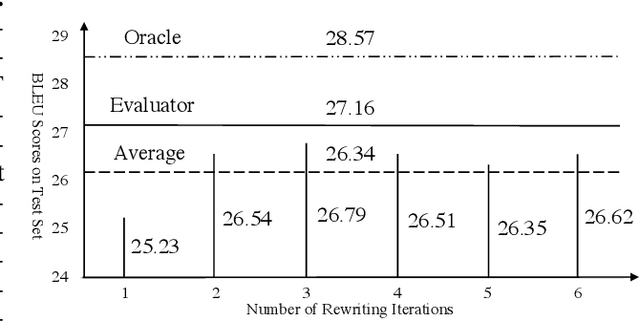
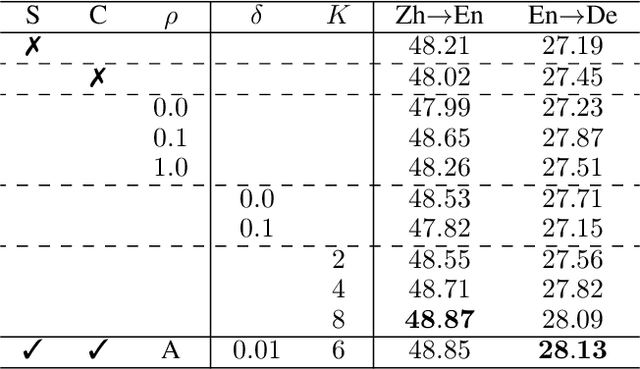
Encoder-decoder architecture has been widely used in neural machine translation (NMT). A few methods have been proposed to improve it with multiple passes of decoding. However, their full potential is limited by a lack of appropriate termination policy. To address this issue, we present a novel framework, Rewriter-Evaluator. It consists of a rewriter and an evaluator. Translating a source sentence involves multiple passes. At every pass, the rewriter produces a new translation to improve the past translation and the evaluator estimates the translation quality to decide whether to terminate the rewriting process. We also propose a prioritized gradient descent (PGD) method that facilitates training the rewriter and the evaluator jointly. Though incurring multiple passes of decoding, Rewriter-Evaluator with the proposed PGD method can be trained with similar time to that of training encoder-decoder models. We apply the proposed framework to improve the general NMT models (e.g., Transformer). We conduct extensive experiments on two translation tasks, Chinese-English and English-German, and show that the proposed framework notably improves the performances of NMT models and significantly outperforms previous baselines.
An Attentional Neural Conversation Model with Improved Specificity
Jun 03, 2016



In this paper we propose a neural conversation model for conducting dialogues. We demonstrate the use of this model to generate help desk responses, where users are asking questions about PC applications. Our model is distinguished by two characteristics. First, it models intention across turns with a recurrent network, and incorporates an attention model that is conditioned on the representation of intention. Secondly, it avoids generating non-specific responses by incorporating an IDF term in the objective function. The model is evaluated both as a pure generation model in which a help-desk response is generated from scratch, and as a retrieval model with performance measured using recall rates of the correct response. Experimental results indicate that the model outperforms previously proposed neural conversation architectures, and that using specificity in the objective function significantly improves performances for both generation and retrieval.
Highway Long Short-Term Memory RNNs for Distant Speech Recognition
Jan 11, 2016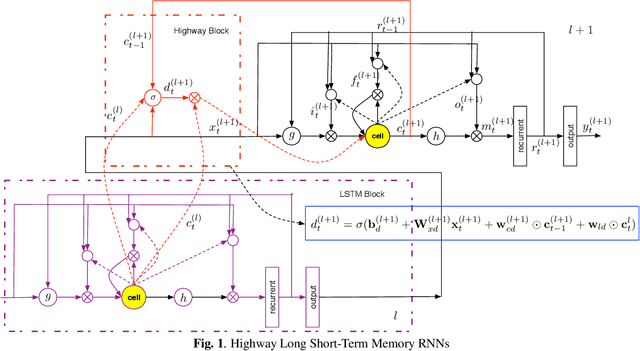
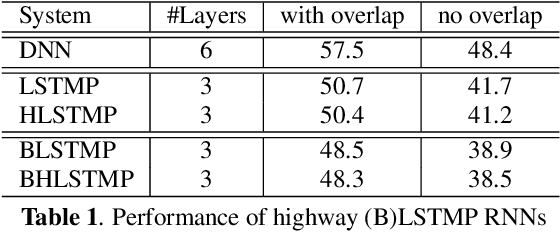
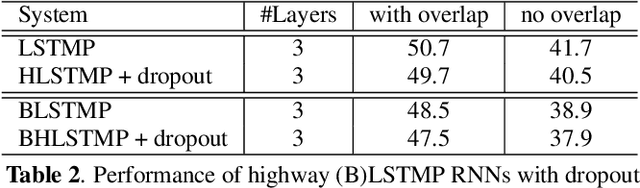
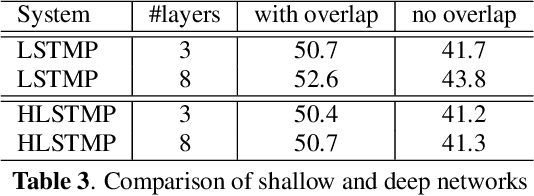
In this paper, we extend the deep long short-term memory (DLSTM) recurrent neural networks by introducing gated direct connections between memory cells in adjacent layers. These direct links, called highway connections, enable unimpeded information flow across different layers and thus alleviate the gradient vanishing problem when building deeper LSTMs. We further introduce the latency-controlled bidirectional LSTMs (BLSTMs) which can exploit the whole history while keeping the latency under control. Efficient algorithms are proposed to train these novel networks using both frame and sequence discriminative criteria. Experiments on the AMI distant speech recognition (DSR) task indicate that we can train deeper LSTMs and achieve better improvement from sequence training with highway LSTMs (HLSTMs). Our novel model obtains $43.9/47.7\%$ WER on AMI (SDM) dev and eval sets, outperforming all previous works. It beats the strong DNN and DLSTM baselines with $15.7\%$ and $5.3\%$ relative improvement respectively.