 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGigaSpeech 2: An Evolving, Large-Scale and Multi-domain ASR Corpus for Low-Resource Languages with Automated Crawling, Transcription and Refinement
Jun 17, 2024The evolution of speech technology has been spurred by the rapid increase in dataset sizes. Traditional speech models generally depend on a large amount of labeled training data, which is scarce for low-resource languages. This paper presents GigaSpeech 2, a large-scale, multi-domain, multilingual speech recognition corpus. It is designed for low-resource languages and does not rely on paired speech and text data. GigaSpeech 2 comprises about 30,000 hours of automatically transcribed speech, including Thai, Indonesian, and Vietnamese, gathered from unlabeled YouTube videos. We also introduce an automated pipeline for data crawling, transcription, and label refinement. Specifically, this pipeline uses Whisper for initial transcription and TorchAudio for forced alignment, combined with multi-dimensional filtering for data quality assurance. A modified Noisy Student Training is developed to further refine flawed pseudo labels iteratively, thus enhancing model performance. Experimental results on our manually transcribed evaluation set and two public test sets from Common Voice and FLEURS confirm our corpus's high quality and broad applicability. Notably, ASR models trained on GigaSpeech 2 can reduce the word error rate for Thai, Indonesian, and Vietnamese on our challenging and realistic YouTube test set by 25% to 40% compared to the Whisper large-v3 model, with merely 10% model parameters. Furthermore, our ASR models trained on Gigaspeech 2 yield superior performance compared to commercial services. We believe that our newly introduced corpus and pipeline will open a new avenue for low-resource speech recognition and significantly facilitate research in this area.
SpeechColab Leaderboard: An Open-Source Platform for Automatic Speech Recognition Evaluation
Mar 13, 2024



In the wake of the surging tide of deep learning over the past decade, Automatic Speech Recognition (ASR) has garnered substantial attention, leading to the emergence of numerous publicly accessible ASR systems that are actively being integrated into our daily lives. Nonetheless, the impartial and replicable evaluation of these ASR systems encounters challenges due to various crucial subtleties. In this paper we introduce the SpeechColab Leaderboard, a general-purpose, open-source platform designed for ASR evaluation. With this platform: (i) We report a comprehensive benchmark, unveiling the current state-of-the-art panorama for ASR systems, covering both open-source models and industrial commercial services. (ii) We quantize how distinct nuances in the scoring pipeline influence the final benchmark outcomes. These include nuances related to capitalization, punctuation, interjection, contraction, synonym usage, compound words, etc. These issues have gained prominence in the context of the transition towards an End-to-End future. (iii) We propose a practical modification to the conventional Token-Error-Rate (TER) evaluation metric, with inspirations from Kolmogorov complexity and Normalized Information Distance (NID). This adaptation, called modified-TER (mTER), achieves proper normalization and symmetrical treatment of reference and hypothesis. By leveraging this platform as a large-scale testing ground, this study demonstrates the robustness and backward compatibility of mTER when compared to TER. The SpeechColab Leaderboard is accessible at https://github.com/SpeechColab/Leaderboard
The THUEE System Description for the IARPA OpenASR21 Challenge
Jun 29, 2022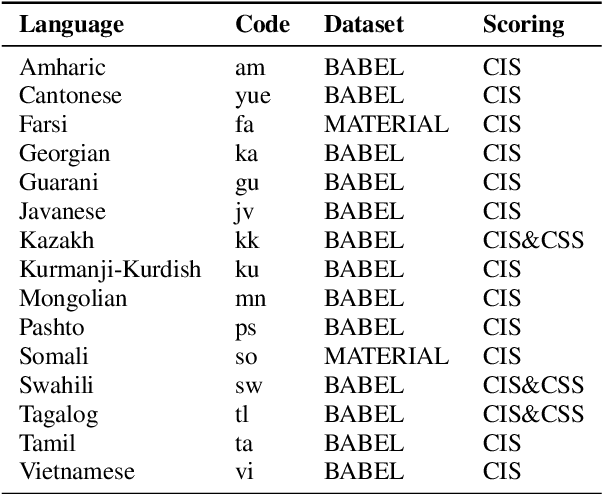
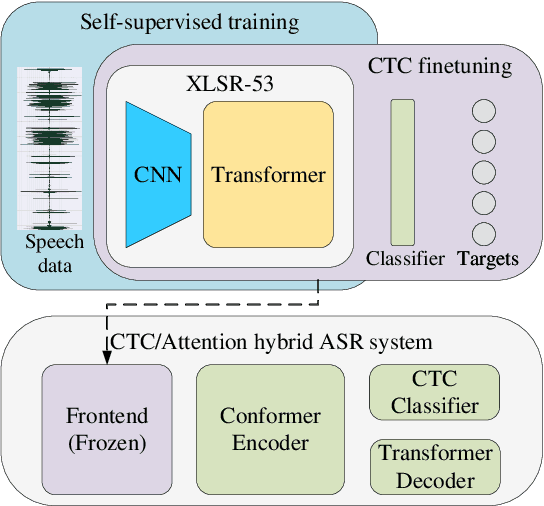
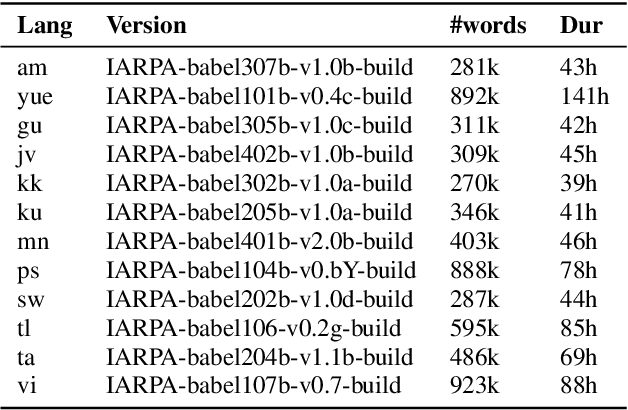
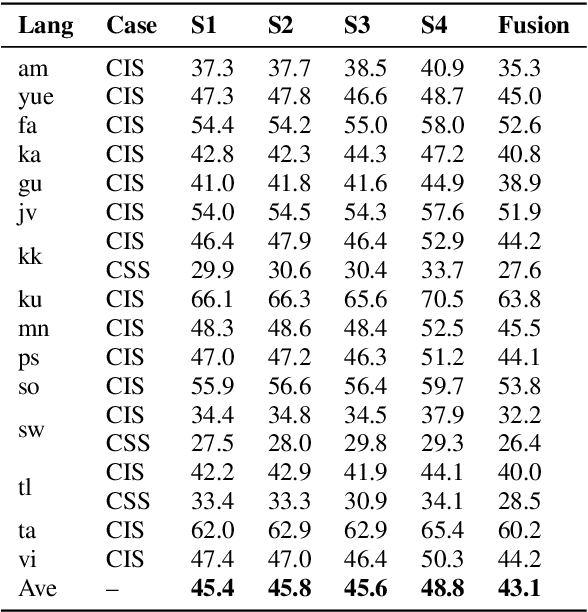
This paper describes the THUEE team's speech recognition system for the IARPA Open Automatic Speech Recognition Challenge (OpenASR21), with further experiment explorations. We achieve outstanding results under both the Constrained and Constrained-plus training conditions. For the Constrained training condition, we construct our basic ASR system based on the standard hybrid architecture. To alleviate the Out-Of-Vocabulary (OOV) problem, we extend the pronunciation lexicon using Grapheme-to-Phoneme (G2P) techniques for both OOV and potential new words. Standard acoustic model structures such as CNN-TDNN-F and CNN-TDNN-F-A are adopted. In addition, multiple data augmentation techniques are applied. For the Constrained-plus training condition, we use the self-supervised learning framework wav2vec2.0. We experiment with various fine-tuning techniques with the Connectionist Temporal Classification (CTC) criterion on top of the publicly available pre-trained model XLSR-53. We find that the frontend feature extractor plays an important role when applying the wav2vec2.0 pre-trained model to the encoder-decoder based CTC/Attention ASR architecture. Extra improvements can be achieved by using the CTC model finetuned in the target language as the frontend feature extractor.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021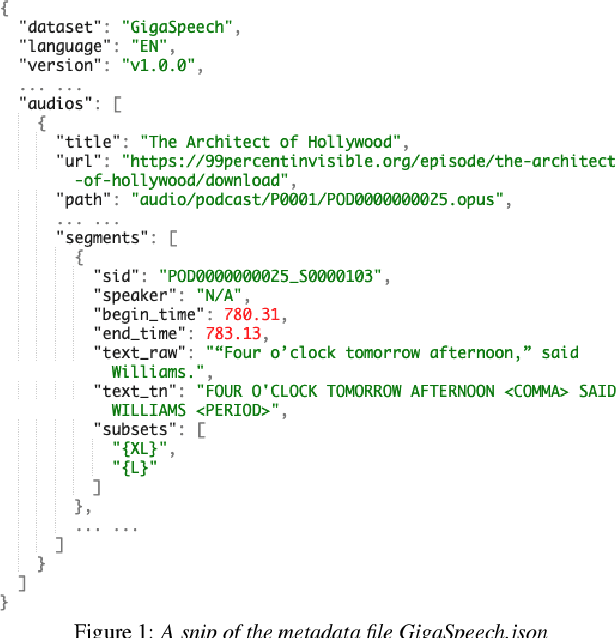
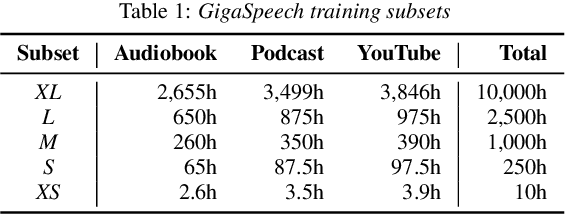
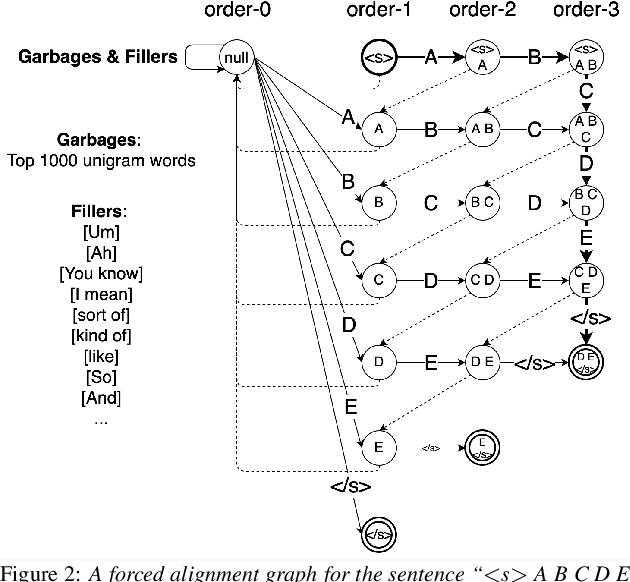
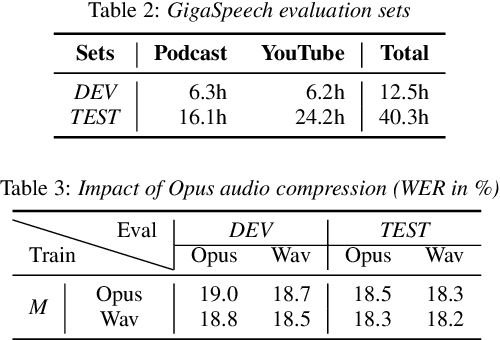
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.
Highway Long Short-Term Memory RNNs for Distant Speech Recognition
Jan 11, 2016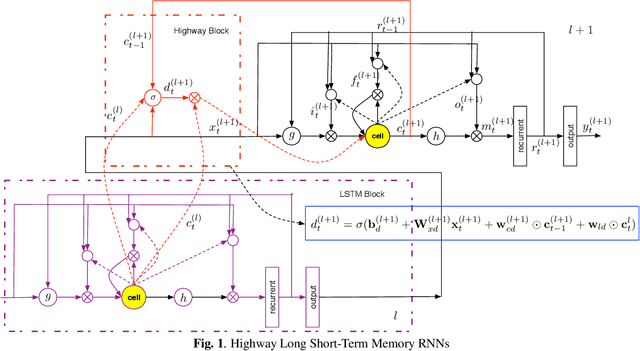
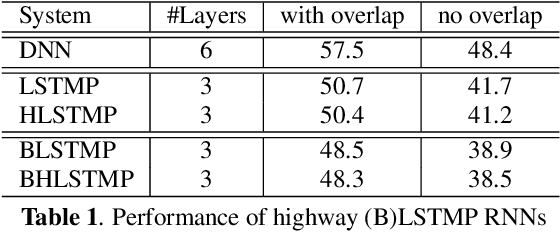
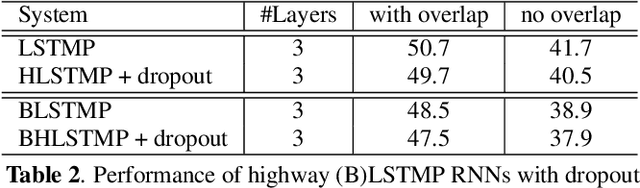
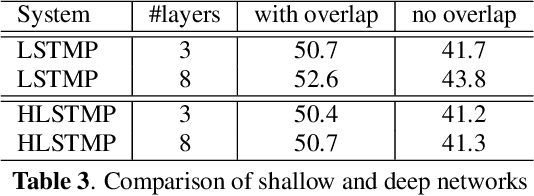
In this paper, we extend the deep long short-term memory (DLSTM) recurrent neural networks by introducing gated direct connections between memory cells in adjacent layers. These direct links, called highway connections, enable unimpeded information flow across different layers and thus alleviate the gradient vanishing problem when building deeper LSTMs. We further introduce the latency-controlled bidirectional LSTMs (BLSTMs) which can exploit the whole history while keeping the latency under control. Efficient algorithms are proposed to train these novel networks using both frame and sequence discriminative criteria. Experiments on the AMI distant speech recognition (DSR) task indicate that we can train deeper LSTMs and achieve better improvement from sequence training with highway LSTMs (HLSTMs). Our novel model obtains $43.9/47.7\%$ WER on AMI (SDM) dev and eval sets, outperforming all previous works. It beats the strong DNN and DLSTM baselines with $15.7\%$ and $5.3\%$ relative improvement respectively.