 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe THUEE System Description for the IARPA OpenASR21 Challenge
Jun 29, 2022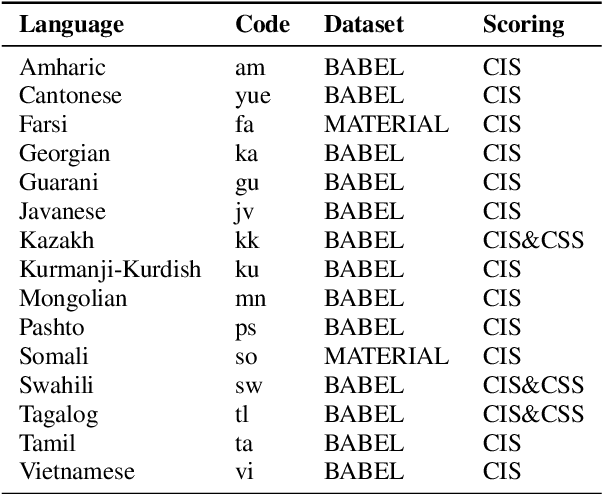
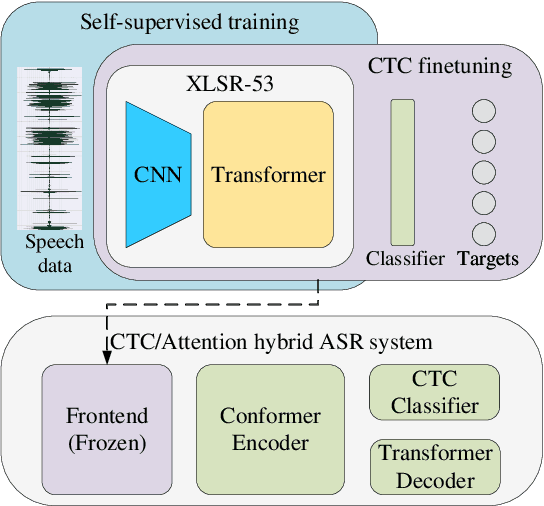
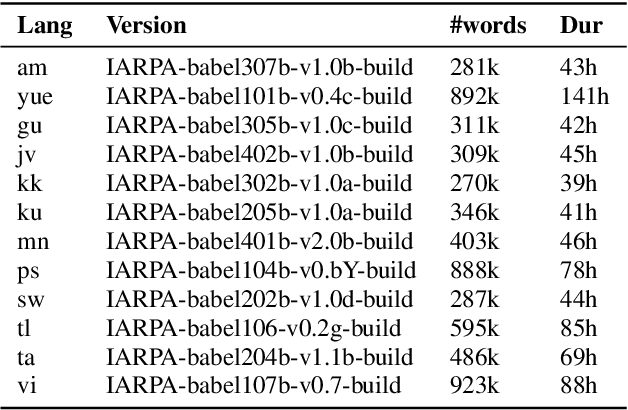
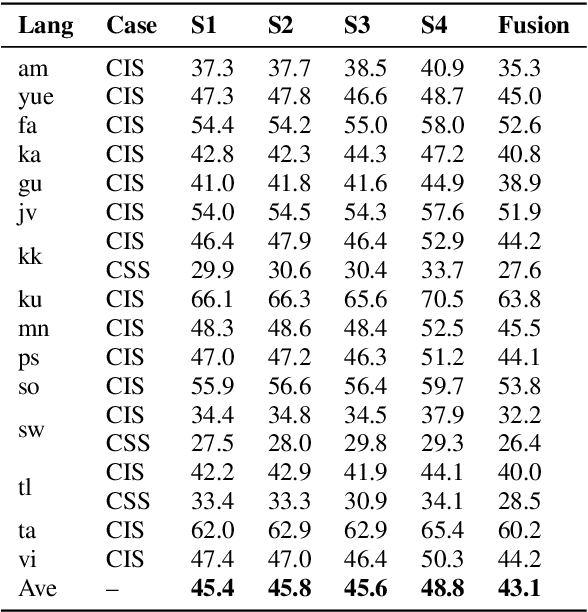
This paper describes the THUEE team's speech recognition system for the IARPA Open Automatic Speech Recognition Challenge (OpenASR21), with further experiment explorations. We achieve outstanding results under both the Constrained and Constrained-plus training conditions. For the Constrained training condition, we construct our basic ASR system based on the standard hybrid architecture. To alleviate the Out-Of-Vocabulary (OOV) problem, we extend the pronunciation lexicon using Grapheme-to-Phoneme (G2P) techniques for both OOV and potential new words. Standard acoustic model structures such as CNN-TDNN-F and CNN-TDNN-F-A are adopted. In addition, multiple data augmentation techniques are applied. For the Constrained-plus training condition, we use the self-supervised learning framework wav2vec2.0. We experiment with various fine-tuning techniques with the Connectionist Temporal Classification (CTC) criterion on top of the publicly available pre-trained model XLSR-53. We find that the frontend feature extractor plays an important role when applying the wav2vec2.0 pre-trained model to the encoder-decoder based CTC/Attention ASR architecture. Extra improvements can be achieved by using the CTC model finetuned in the target language as the frontend feature extractor.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021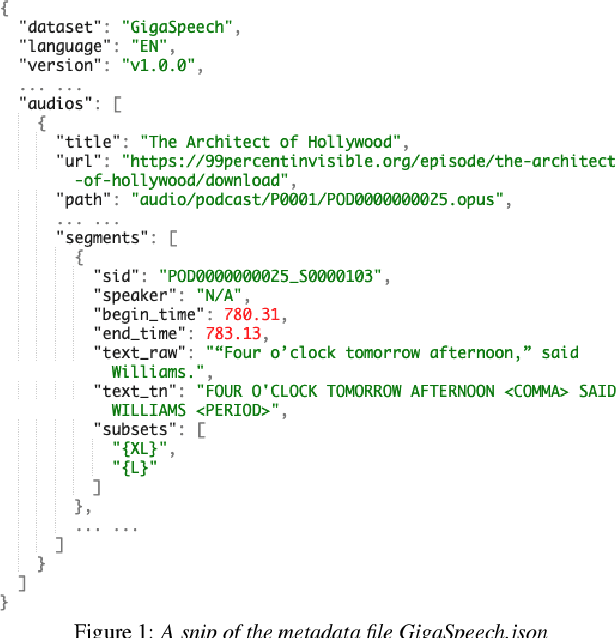
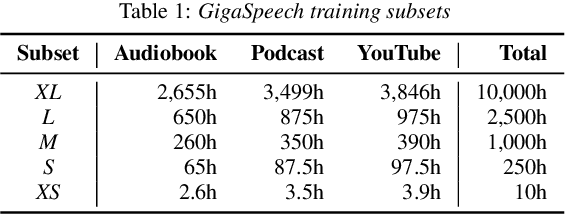
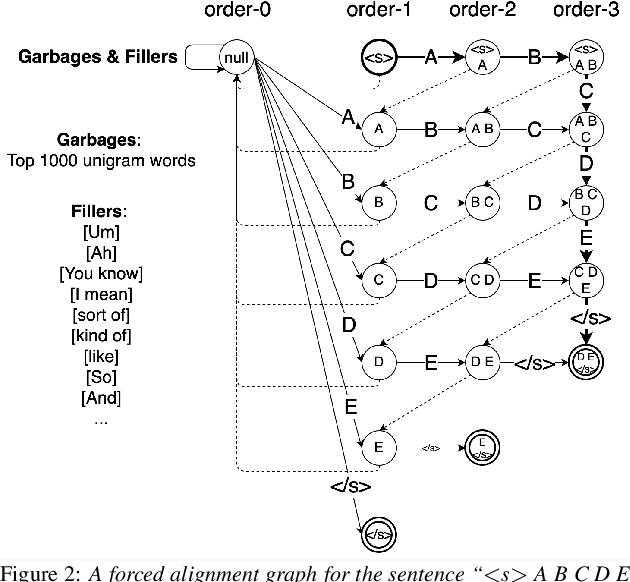
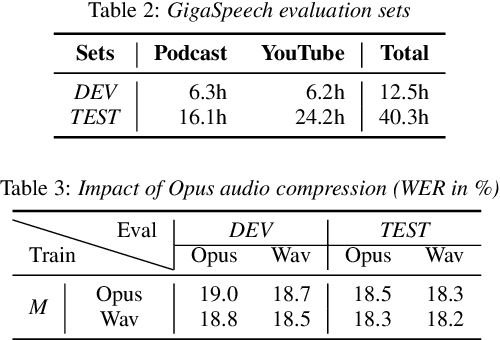
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.