 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multilingual LLM-based ASR with Mixture of Experts and Dynamic Downsampling
Jun 09, 2026The rapid progress of large language models (LLMs) has opened up a new frontier for automatic speech recognition (ASR), making their effective integration a critical and challenging research direction. To this end, this work proposes a projector-based LLM-ASR framework targeting the key challenges of multilingual generalization and modality alignment. Our approach incorporates a Mixture of Experts (MoE) architecture to improve cross-lingual adaptability, and a Continuous Integrate-and-Fire (CIF) mechanism for dynamic downsampling and modality alignment. Experimental results show that the combination of these components yields substantial performance improvements, surpassing strong baseline models. The proposed method represents a step toward building more accurate, robust, and generalizable LLM-based ASR systems.
* Accepted by ICASSP 2026
SARNet: A Spike-Aware consecutive validation Framework for Accurate Remaining Useful Life Prediction
Oct 27, 2025Accurate prediction of remaining useful life (RUL) is essential to enhance system reliability and reduce maintenance risk. Yet many strong contemporary models are fragile around fault onset and opaque to engineers: short, high-energy spikes are smoothed away or misread, fixed thresholds blunt sensitivity, and physics-based explanations are scarce. To remedy this, we introduce SARNet (Spike-Aware Consecutive Validation Framework), which builds on a Modern Temporal Convolutional Network (ModernTCN) and adds spike-aware detection to provide physics-informed interpretability. ModernTCN forecasts degradation-sensitive indicators; an adaptive consecutive threshold validates true spikes while suppressing noise. Failure-prone segments then receive targeted feature engineering (spectral slopes, statistical derivatives, energy ratios), and the final RUL is produced by a stacked RF--LGBM regressor. Across benchmark-ported datasets under an event-triggered protocol, SARNet consistently lowers error compared to recent baselines (RMSE 0.0365, MAE 0.0204) while remaining lightweight, robust, and easy to deploy.
Exploring Self-Supervised Audio Models for Generalized Anomalous Sound Detection
Aug 17, 2025
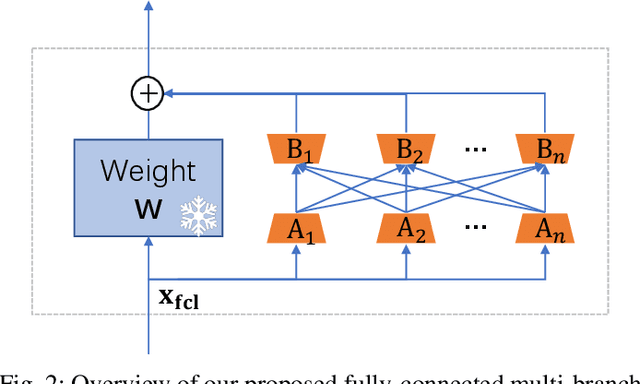
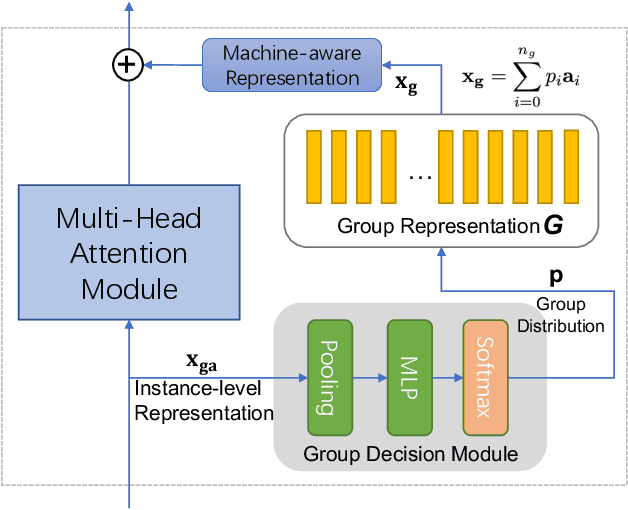
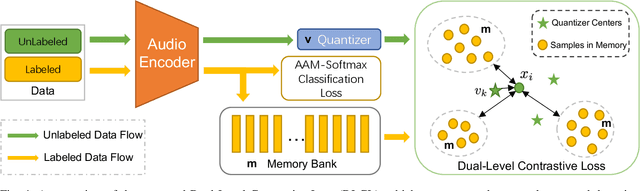
Machine anomalous sound detection (ASD) is a valuable technique across various applications. However, its generalization performance is often limited due to challenges in data collection and the complexity of acoustic environments. Inspired by the success of large pre-trained models in numerous fields, this paper introduces a robust ASD model that leverages self-supervised pre-trained models trained on large-scale speech and audio datasets. Although there are inconsistencies between the pre-training datasets and the ASD task, our findings indicate that pre-training still provides substantial benefits for ASD. To mitigate overfitting and retain learned knowledge when fine-tuning with limited data, we explore Fully-Connected Low-Rank Adaptation (LoRA) as an alternative to full fine-tuning. Additionally, we propose a Machine-aware Group Adapter module, which enables the model to capture differences between various machines within a unified framework, thereby enhancing the generalization performance of ASD systems. To address the challenge of missing attribute labels, we design a novel objective function that dynamically clusters unattributed data using vector quantization and optimizes through a dual-level contrastive learning loss. The proposed methods are evaluated on all benchmark datasets, including the DCASE 2020-2024 five ASD challenges, and the experimental results show significant improvements of our new approach and demonstrate the effectiveness of our proposed strategies.
FISHER: A Foundation Model for Multi-Modal Industrial Signal Comprehensive Representation
Jul 22, 2025With the rapid deployment of SCADA systems, how to effectively analyze industrial signals and detect abnormal states is an urgent need for the industry. Due to the significant heterogeneity of these signals, which we summarize as the M5 problem, previous works only focus on small sub-problems and employ specialized models, failing to utilize the synergies between modalities and the powerful scaling law. However, we argue that the M5 signals can be modeled in a unified manner due to the intrinsic similarity. As a result, we propose FISHER, a Foundation model for multi-modal Industrial Signal compreHEnsive Representation. To support arbitrary sampling rates, FISHER considers the increment of sampling rate as the concatenation of sub-band information. Specifically, FISHER takes the STFT sub-band as the modeling unit and adopts a teacher student SSL framework for pre-training. We also develop the RMIS benchmark, which evaluates the representations of M5 industrial signals on multiple health management tasks. Compared with top SSL models, FISHER showcases versatile and outstanding capabilities with a general performance gain up to 5.03%, along with much more efficient scaling curves. We also investigate the scaling law on downstream tasks and derive potential avenues for future works. FISHER is now open-sourced on https://github.com/jianganbai/FISHER
Dolphin: A Large-Scale Automatic Speech Recognition Model for Eastern Languages
Mar 26, 2025This report introduces Dolphin, a large-scale multilingual automatic speech recognition (ASR) model that extends the Whisper architecture to support a wider range of languages. Our approach integrates in-house proprietary and open-source datasets to refine and optimize Dolphin's performance. The model is specifically designed to achieve notable recognition accuracy for 40 Eastern languages across East Asia, South Asia, Southeast Asia, and the Middle East, while also supporting 22 Chinese dialects. Experimental evaluations show that Dolphin significantly outperforms current state-of-the-art open-source models across various languages. To promote reproducibility and community-driven innovation, we are making our trained models and inference source code publicly available.
Integrating Pause Information with Word Embeddings in Language Models for Alzheimer's Disease Detection from Spontaneous Speech
Jan 12, 2025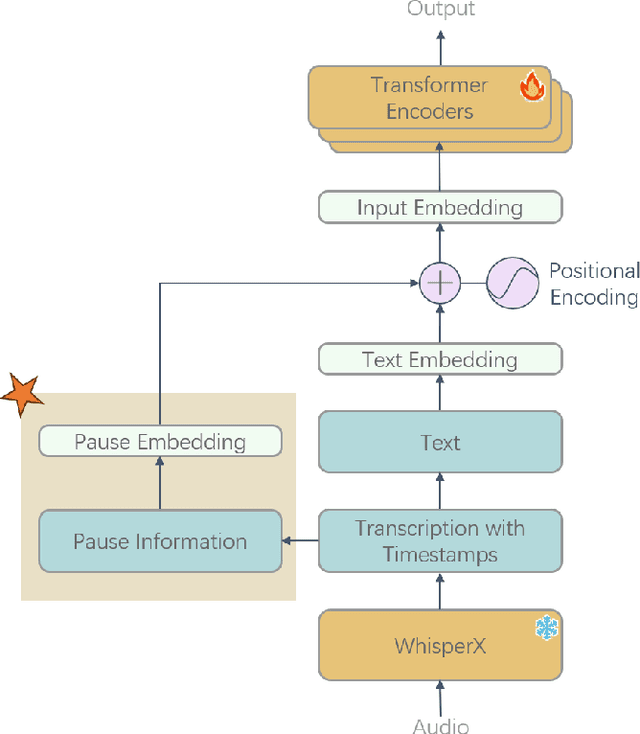
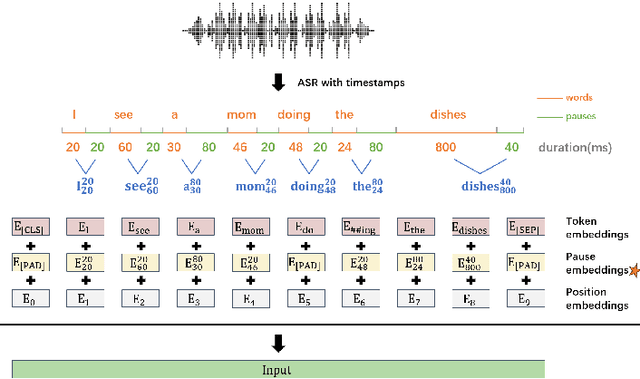
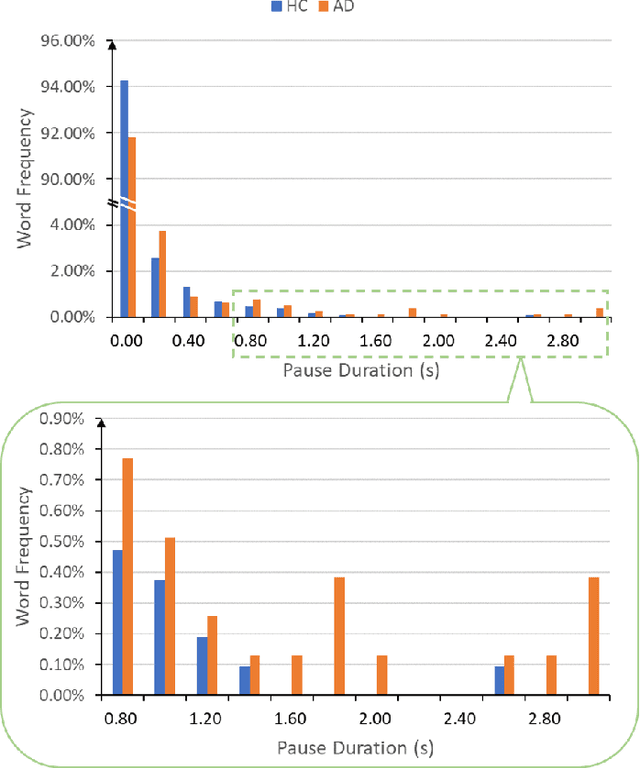
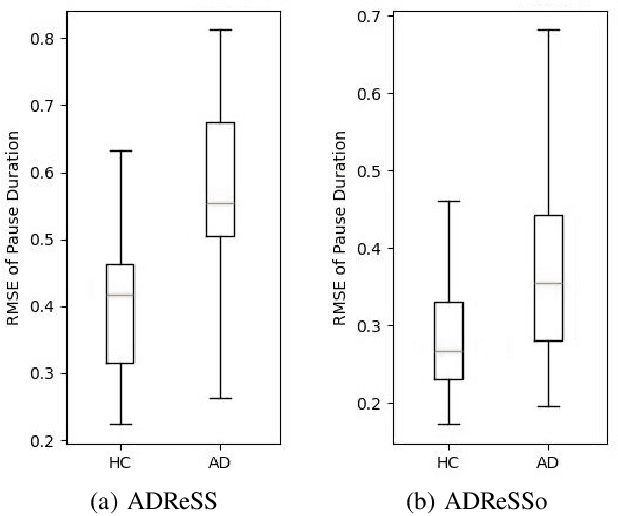
Alzheimer's disease (AD) is a progressive neurodegenerative disorder characterized by cognitive decline and memory loss. Early detection of AD is crucial for effective intervention and treatment. In this paper, we propose a novel approach to AD detection from spontaneous speech, which incorporates pause information into language models. Our method involves encoding pause information into embeddings and integrating them into the typical transformer-based language model, enabling it to capture both semantic and temporal features of speech data. We conduct experiments on the Alzheimer's Dementia Recognition through Spontaneous Speech (ADReSS) dataset and its extension, the ADReSSo dataset, comparing our method with existing approaches. Our method achieves an accuracy of 83.1% in the ADReSSo test set. The results demonstrate the effectiveness of our approach in discriminating between AD patients and healthy individuals, highlighting the potential of pauses as a valuable indicator for AD detection. By leveraging speech analysis as a non-invasive and cost-effective tool for AD detection, our research contributes to early diagnosis and improved management of this debilitating disease.
Metadata-Enhanced Speech Emotion Recognition: Augmented Residual Integration and Co-Attention in Two-Stage Fine-Tuning
Dec 30, 2024



Speech Emotion Recognition (SER) involves analyzing vocal expressions to determine the emotional state of speakers, where the comprehensive and thorough utilization of audio information is paramount. Therefore, we propose a novel approach on self-supervised learning (SSL) models that employs all available auxiliary information -- specifically metadata -- to enhance performance. Through a two-stage fine-tuning method in multi-task learning, we introduce the Augmented Residual Integration (ARI) module, which enhances transformer layers in encoder of SSL models. The module efficiently preserves acoustic features across all different levels, thereby significantly improving the performance of metadata-related auxiliary tasks that require various levels of features. Moreover, the Co-attention module is incorporated due to its complementary nature with ARI, enabling the model to effectively utilize multidimensional information and contextual relationships from metadata-related auxiliary tasks. Under pre-trained base models and speaker-independent setup, our approach consistently surpasses state-of-the-art (SOTA) models on multiple SSL encoders for the IEMOCAP dataset.
Improving Acoustic Scene Classification in Low-Resource Conditions
Dec 30, 2024



Acoustic Scene Classification (ASC) identifies an environment based on an audio signal. This paper explores ASC in low-resource conditions and proposes a novel model, DS-FlexiNet, which combines depthwise separable convolutions from MobileNetV2 with ResNet-inspired residual connections for a balance of efficiency and accuracy. To address hardware limitations and device heterogeneity, DS-FlexiNet employs Quantization Aware Training (QAT) for model compression and data augmentation methods like Auto Device Impulse Response (ADIR) and Freq-MixStyle (FMS) to improve cross-device generalization. Knowledge Distillation (KD) from twelve teacher models further enhances performance on unseen devices. The architecture includes a custom Residual Normalization layer to handle domain differences across devices, and depthwise separable convolutions reduce computational overhead without sacrificing feature representation. Experimental results show that DS-FlexiNet excels in both adaptability and performance under resource-constrained conditions.
Improving Anomalous Sound Detection via Low-Rank Adaptation Fine-Tuning of Pre-Trained Audio Models
Sep 11, 2024



Anomalous Sound Detection (ASD) has gained significant interest through the application of various Artificial Intelligence (AI) technologies in industrial settings. Though possessing great potential, ASD systems can hardly be readily deployed in real production sites due to the generalization problem, which is primarily caused by the difficulty of data collection and the complexity of environmental factors. This paper introduces a robust ASD model that leverages audio pre-trained models. Specifically, we fine-tune these models using machine operation data, employing SpecAug as a data augmentation strategy. Additionally, we investigate the impact of utilizing Low-Rank Adaptation (LoRA) tuning instead of full fine-tuning to address the problem of limited data for fine-tuning. Our experiments on the DCASE2023 Task 2 dataset establish a new benchmark of 77.75% on the evaluation set, with a significant improvement of 6.48% compared with previous state-of-the-art (SOTA) models, including top-tier traditional convolutional networks and speech pre-trained models, which demonstrates the effectiveness of audio pre-trained models with LoRA tuning. Ablation studies are also conducted to showcase the efficacy of the proposed scheme.
CoopASD: Cooperative Machine Anomalous Sound Detection with Privacy Concerns
Aug 27, 2024



Machine anomalous sound detection (ASD) has emerged as one of the most promising applications in the Industrial Internet of Things (IIoT) due to its unprecedented efficacy in mitigating risks of malfunctions and promoting production efficiency. Previous works mainly investigated the machine ASD task under centralized settings. However, developing the ASD system under decentralized settings is crucial in practice, since the machine data are dispersed in various factories and the data should not be explicitly shared due to privacy concerns. To enable these factories to cooperatively develop a scalable ASD model while preserving their privacy, we propose a novel framework named CoopASD, where each factory trains an ASD model on its local dataset, and a central server aggregates these local models periodically. We employ a pre-trained model as the backbone of the ASD model to improve its robustness and develop specialized techniques to stabilize the model under a completely non-iid and domain shift setting. Compared with previous state-of-the-art (SOTA) models trained in centralized settings, CoopASD showcases competitive results with negligible degradation of 0.08%. We also conduct extensive ablation studies to demonstrate the effectiveness of CoopASD.