 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Empowered Cooperative Content Caching in Vehicular Fog Caching-Assisted Platoon Networks
Feb 04, 2026This letter proposes a novel three-tier content caching architecture for Vehicular Fog Caching (VFC)-assisted platoon, where the VFC is formed by the vehicles driving near the platoon. The system strategically coordinates storage across local platoon vehicles, dynamic VFC clusters, and cloud server (CS) to minimize content retrieval latency. To efficiently manage distributed storage, we integrate large language models (LLMs) for real-time and intelligent caching decisions. The proposed approach leverages LLMs' ability to process heterogeneous information, including user profiles, historical data, content characteristics, and dynamic system states. Through a designed prompting framework encoding task objectives and caching constraints, the LLMs formulate caching as a decision-making task, and our hierarchical deterministic caching mapping strategy enables adaptive requests prediction and precise content placement across three tiers without frequent retraining. Simulation results demonstrate the advantages of our proposed caching scheme.
Federated Distillation Assisted Vehicle Edge Caching Scheme Based on Lightweight DDPM
Dec 10, 2025



Vehicle edge caching is a promising technology that can significantly reduce the latency for vehicle users (VUs) to access content by pre-caching user-interested content at edge nodes. It is crucial to accurately predict the content that VUs are interested in without exposing their privacy. Traditional federated learning (FL) can protect user privacy by sharing models rather than raw data. However, the training of FL requires frequent model transmission, which can result in significant communication overhead. Additionally, vehicles may leave the road side unit (RSU) coverage area before training is completed, leading to training failures. To address these issues, in this letter, we propose a federated distillation-assisted vehicle edge caching scheme based on lightweight denoising diffusion probabilistic model (LDPM). The simulation results demonstrate that the proposed vehicle edge caching scheme has good robustness to variations in vehicle speed, significantly reducing communication overhead and improving cache hit percentage.
Semantic-Aware Cooperative Communication and Computation Framework in Vehicular Networks
Dec 10, 2025Semantic Communication (SC) combined with Vehicular edge computing (VEC) provides an efficient edge task processing paradigm for Internet of Vehicles (IoV). Focusing on highway scenarios, this paper proposes a Tripartite Cooperative Semantic Communication (TCSC) framework, which enables Vehicle Users (VUs) to perform semantic task offloading via Vehicle-to-Infrastructure (V2I) and Vehicle-to-Vehicle (V2V) communications. Considering task latency and the number of semantic symbols, the framework constructs a Mixed-Integer Nonlinear Programming (MINLP) problem, which is transformed into two subproblems. First, we innovatively propose a multi-agent proximal policy optimization task offloading optimization method based on parametric distribution noise (MAPPO-PDN) to solve the optimization problem of the number of semantic symbols; second, linear programming (LP) is used to solve offloading ratio. Simulations show that performance of this scheme is superior to that of other algorithms.
Exploring Self-Supervised Audio Models for Generalized Anomalous Sound Detection
Aug 17, 2025
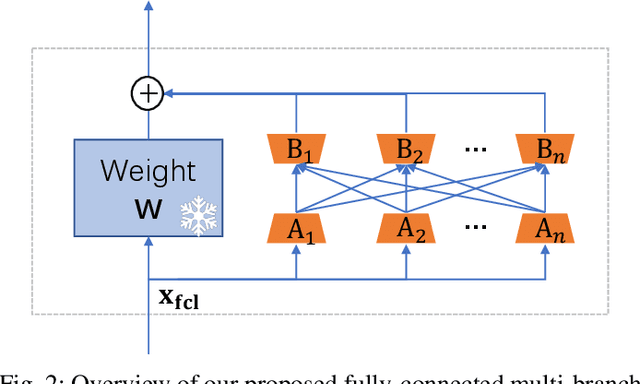
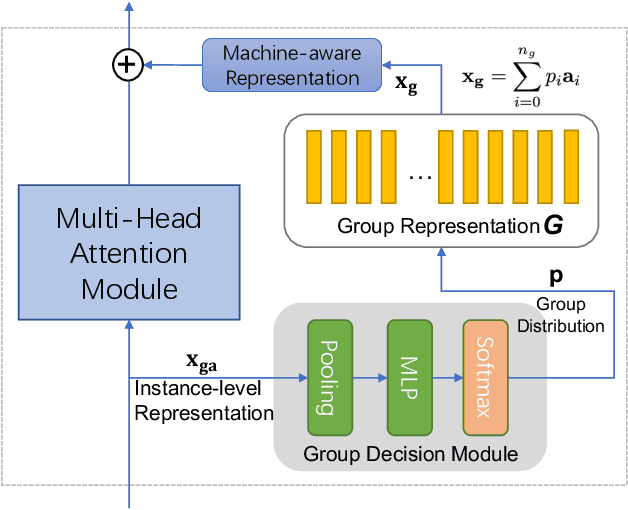
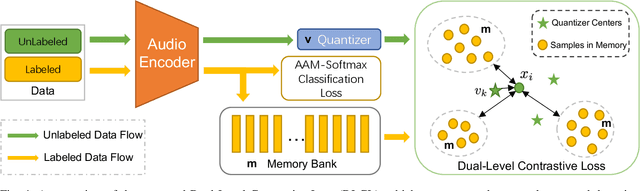
Machine anomalous sound detection (ASD) is a valuable technique across various applications. However, its generalization performance is often limited due to challenges in data collection and the complexity of acoustic environments. Inspired by the success of large pre-trained models in numerous fields, this paper introduces a robust ASD model that leverages self-supervised pre-trained models trained on large-scale speech and audio datasets. Although there are inconsistencies between the pre-training datasets and the ASD task, our findings indicate that pre-training still provides substantial benefits for ASD. To mitigate overfitting and retain learned knowledge when fine-tuning with limited data, we explore Fully-Connected Low-Rank Adaptation (LoRA) as an alternative to full fine-tuning. Additionally, we propose a Machine-aware Group Adapter module, which enables the model to capture differences between various machines within a unified framework, thereby enhancing the generalization performance of ASD systems. To address the challenge of missing attribute labels, we design a novel objective function that dynamically clusters unattributed data using vector quantization and optimizes through a dual-level contrastive learning loss. The proposed methods are evaluated on all benchmark datasets, including the DCASE 2020-2024 five ASD challenges, and the experimental results show significant improvements of our new approach and demonstrate the effectiveness of our proposed strategies.
FISHER: A Foundation Model for Multi-Modal Industrial Signal Comprehensive Representation
Jul 22, 2025With the rapid deployment of SCADA systems, how to effectively analyze industrial signals and detect abnormal states is an urgent need for the industry. Due to the significant heterogeneity of these signals, which we summarize as the M5 problem, previous works only focus on small sub-problems and employ specialized models, failing to utilize the synergies between modalities and the powerful scaling law. However, we argue that the M5 signals can be modeled in a unified manner due to the intrinsic similarity. As a result, we propose FISHER, a Foundation model for multi-modal Industrial Signal compreHEnsive Representation. To support arbitrary sampling rates, FISHER considers the increment of sampling rate as the concatenation of sub-band information. Specifically, FISHER takes the STFT sub-band as the modeling unit and adopts a teacher student SSL framework for pre-training. We also develop the RMIS benchmark, which evaluates the representations of M5 industrial signals on multiple health management tasks. Compared with top SSL models, FISHER showcases versatile and outstanding capabilities with a general performance gain up to 5.03%, along with much more efficient scaling curves. We also investigate the scaling law on downstream tasks and derive potential avenues for future works. FISHER is now open-sourced on https://github.com/jianganbai/FISHER
Enhanced SPS Velocity-adaptive Scheme: Access Fairness in 5G NR V2I Networks
Jan 16, 2025



Vehicle-to-Infrastructure (V2I) technology enables information exchange between vehicles and road infrastructure. Specifically, when a vehicle approaches a roadside unit (RSU), it can exchange information with the RSU to obtain accurate data that assists in driving. With the release of the 3rd Generation Partnership Project (3GPP) Release 16, which includes the 5G New Radio (NR) Vehicle-to-Everything (V2X) standards, vehicles typically adopt mode-2 communication using sensing-based semi-persistent scheduling (SPS) for resource allocation. In this approach, vehicles identify candidate resources within a selection window and exclude ineligible resources based on information from a sensing window. However, vehicles often drive at different speeds, resulting in varying amounts of data transmission with RSUs as they pass by, which leads to unfair access. Therefore, it is essential to design an access scheme that accounts for different vehicle speeds to achieve fair access across the network. This paper formulates an optimization problem for vehicular networks and proposes a multi-objective optimization scheme to address it by adjusting the selection window in the SPS mechanism of 5G NR V2I mode-2. Simulation results demonstrate the effectiveness of the proposed scheme
DRL-Based Optimization for AoI and Energy Consumption in C-V2X Enabled IoV
Nov 20, 2024
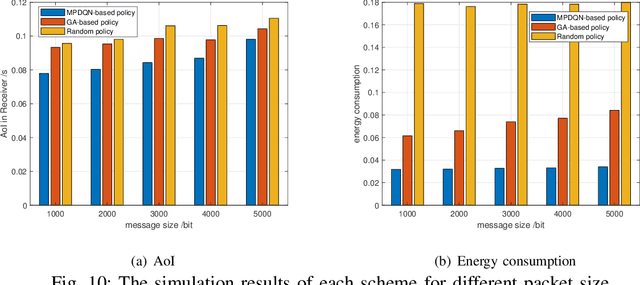


To address communication latency issues, the Third Generation Partnership Project (3GPP) has defined Cellular-Vehicle to Everything (C-V2X) technology, which includes Vehicle-to-Vehicle (V2V) communication for direct vehicle-to-vehicle communication. However, this method requires vehicles to autonomously select communication resources based on the Semi-Persistent Scheduling (SPS) protocol, which may lead to collisions due to different vehicles sharing the same communication resources, thereby affecting communication effectiveness. Non-Orthogonal Multiple Access (NOMA) is considered a potential solution for handling large-scale vehicle communication, as it can enhance the Signal-to-Interference-plus-Noise Ratio (SINR) by employing Successive Interference Cancellation (SIC), thereby reducing the negative impact of communication collisions. When evaluating vehicle communication performance, traditional metrics such as reliability and transmission delay present certain contradictions. Introducing the new metric Age of Information (AoI) provides a more comprehensive evaluation of communication system. Additionally, to ensure service quality, user terminals need to possess high computational capabilities, which may lead to increased energy consumption, necessitating a trade-off between communication energy consumption and effectiveness. Given the complexity and dynamics of communication systems, Deep Reinforcement Learning (DRL) serves as an intelligent learning method capable of learning optimal strategies in dynamic environments. Therefore, this paper analyzes the effects of multi-priority queues and NOMA on AoI in the C-V2X vehicular communication system and proposes an energy consumption and AoI optimization method based on DRL. Finally, through comparative simulations with baseline methods, the proposed approach demonstrates its advances in terms of energy consumption and AoI.
Semantic-Aware Resource Management for C-V2X Platooning via Multi-Agent Reinforcement Learning
Nov 07, 2024



This paper presents a semantic-aware multi-modal resource allocation (SAMRA) for multi-task using multi-agent reinforcement learning (MARL), termed SAMRAMARL, utilizing in platoon systems where cellular vehicle-to-everything (C-V2X) communication is employed. The proposed approach leverages the semantic information to optimize the allocation of communication resources. By integrating a distributed multi-agent reinforcement learning (MARL) algorithm, SAMRAMARL enables autonomous decision-making for each vehicle, channel assignment optimization, power allocation, and semantic symbol length based on the contextual importance of the transmitted information. This semantic-awareness ensures that both vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) communications prioritize data that is critical for maintaining safe and efficient platoon operations. The framework also introduces a tailored quality of experience (QoE) metric for semantic communication, aiming to maximize QoE in V2V links while improving the success rate of semantic information transmission (SRS). Extensive simulations has demonstrated that SAMRAMARL outperforms existing methods, achieving significant gains in QoE and communication efficiency in C-V2X platooning scenarios.
V2X-Assisted Distributed Computing and Control Framework for Connected and Automated Vehicles under Ramp Merging Scenario
Oct 30, 2024This paper investigates distributed computing and cooperative control of connected and automated vehicles (CAVs) in ramp merging scenario under transportation cyber-physical system. Firstly, a centralized cooperative trajectory planning problem is formulated subject to the safely constraints and traffic performance in ramp merging scenario, where the trajectories of all vehicles are jointly optimized. To get rid of the reliance on a central controller and reduce computation time, a distributed solution to this problem implemented among CAVs through Vehicles-to-Everything (V2X) communication is proposed. Unlike existing method, our method can distribute the computational task among CAVs and carry out parallel solving through V2X communication. Then, a multi-vehicles model predictive control (MPC) problem aimed at maximizing system stability and minimizing control input is formulated based on the solution of the first problem subject to strict safety constants and input limits. Due to these complex constraints, this problem becomes high-dimensional, centralized, and non-convex. To solve it in a short time, a decomposition and convex reformulation method, namely distributed cooperative iterative model predictive control (DCIMPC), is proposed. This method leverages the communication capability of CAVs to decompose the problem, making full use of the computational resources on vehicles to achieve fast solutions and distributed control. The two above problems with their corresponding solving methods form the systemic framework of the V2X assisted distributed computing and control. Simulations have been conducted to evaluate the framework's convergence, safety, and solving speed. Additionally, extra experiments are conducted to validate the performance of DCIMPC. The results show that our method can greatly improve computation speed without sacrificing system performance.
A Comprehensive Survey on Joint Resource Allocation Strategies in Federated Edge Learning
Oct 10, 2024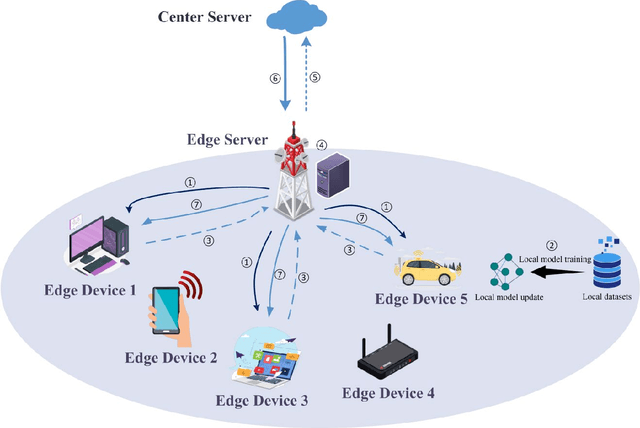
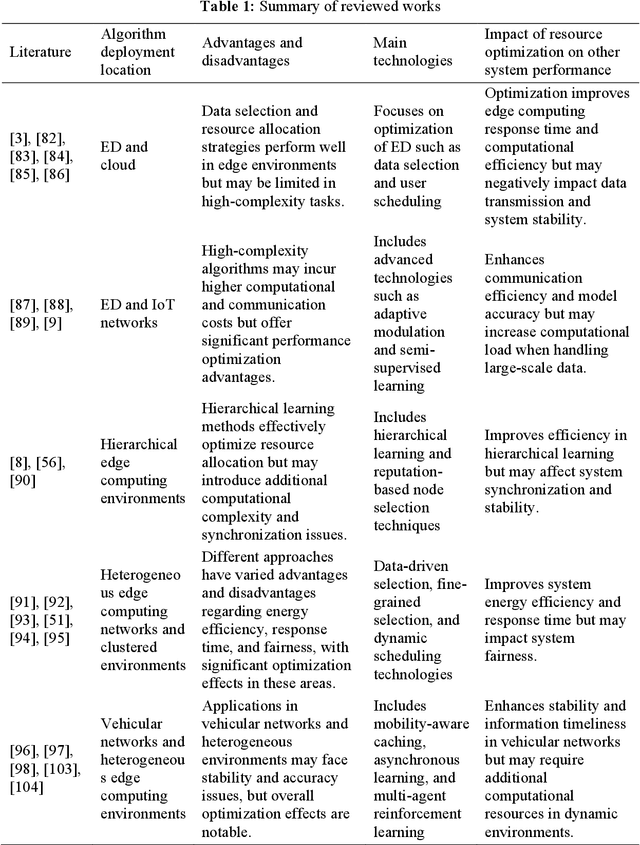
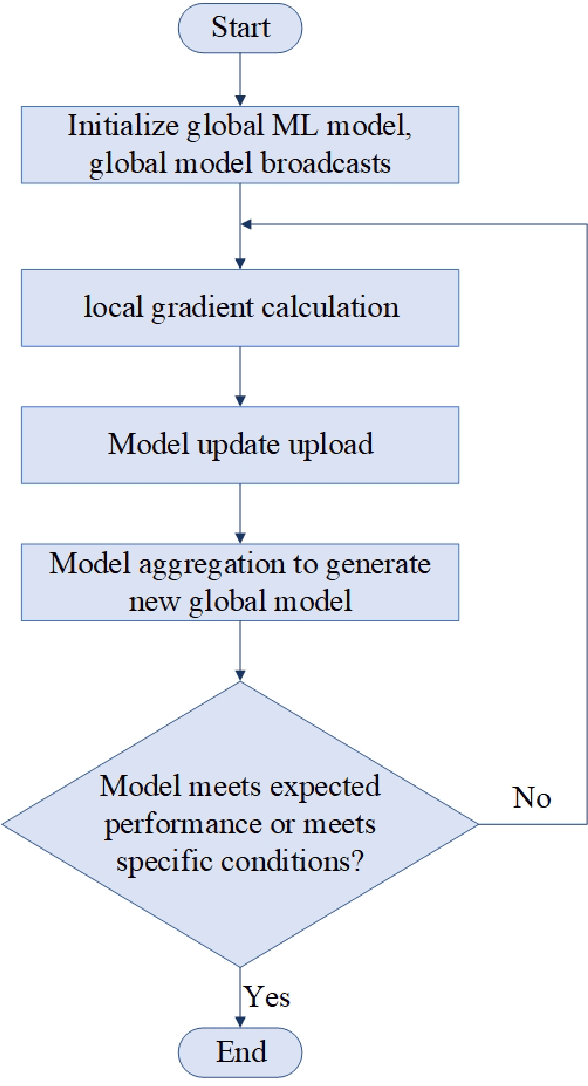
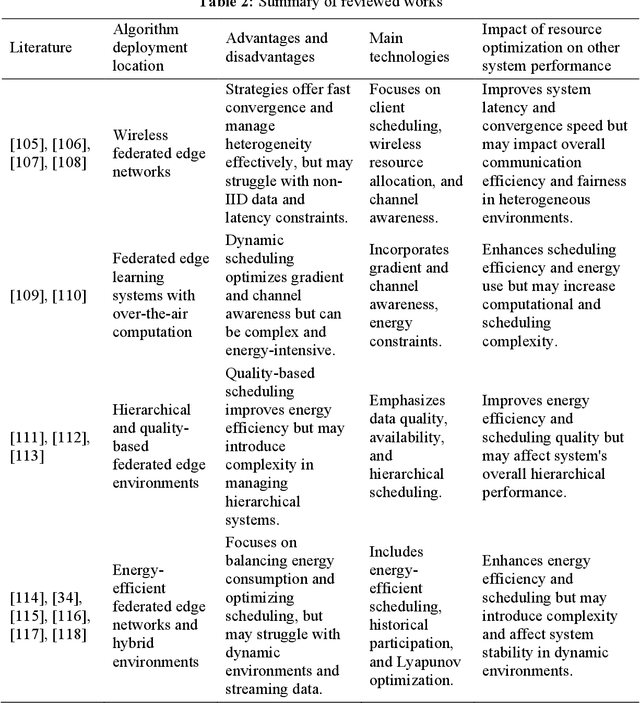
Federated Edge Learning (FEL), an emerging distributed Machine Learning (ML) paradigm, enables model training in a distributed environment while ensuring user privacy by using physical separation for each user data. However, with the development of complex application scenarios such as the Internet of Things (IoT) and Smart Earth, the conventional resource allocation schemes can no longer effectively support these growing computational and communication demands. Therefore, joint resource optimization may be the key solution to the scaling problem. This paper simultaneously addresses the multifaceted challenges of computation and communication, with the growing multiple resource demands. We systematically review the joint allocation strategies for different resources (computation, data, communication, and network topology) in FEL, and summarize the advantages in improving system efficiency, reducing latency, enhancing resource utilization and enhancing robustness. In addition, we present the potential ability of joint optimization to enhance privacy preservation by reducing communication requirements, indirectly. This work not only provides theoretical support for resource management in federated learning (FL) systems, but also provides ideas for potential optimal deployment in multiple real-world scenarios. By thoroughly discussing the current challenges and future research directions, it also provides some important insights into multi-resource optimization in complex application environments.