 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskWAM: Unifying Mask Prompting and Prediction for World-Action Models
Jun 11, 2026World Action Models (WAMs) present a promising paradigm for robotic control via video prediction. However, current WAMs suffer from fundamental spatial bottlenecks: standard text inputs introduce referential ambiguity in cluttered scenes, while unstructured RGB predictions lack semantic grounding and remain biased by task-irrelevant backgrounds. To overcome these limitations, we introduce MaskWAM, an object-centric world-action model. By jointly integrating masks as both explicit inputs and predictions via a unified Mixture of Transformers (MoT), MaskWAM unlocks robust policy generalization. This design provides two key benefits: (1) predicting future masks yields object-centric semantic supervision that suppresses visual noise, significantly enhancing even standard text-conditioned WAMs; and (2) coupling this predictive supervision with first-frame visual prompts, such as target object masks, establishes a precise spatial anchor that substantially reduces language ambiguity. Crucially, as WAMs are inherently vision-driven architectures, direct mask conditioning yields substantially stronger guidance than text alone, establishing a precise and robust paradigm for manipulating unseen objects. Evaluations on LIBERO, RoboTwin, and real-world tasks demonstrate that MaskWAM significantly outperforms baselines in both language-clear and language-ambiguous tasks.
PPO-Based Hybrid Optimization for RIS-Assisted Semantic Vehicular Edge Computing
Mar 10, 2026To support latency-sensitive Internet of Vehicles (IoV) applications amidst dynamic environments and intermittent links, this paper proposes a Reconfigurable Intelligent Surface (RIS)-aided semantic-aware Vehicle Edge Computing (VEC) framework. This approach integrates RIS to optimize wireless connectivity and semantic communication to minimize latency by transmitting semantic features. We formulate a comprehensive joint optimization problem by optimizing offloading ratios, the number of semantic symbols, and RIS phase shifts. Considering the problem's high dimensionality and non-convexity, we propose a two-tier hybrid scheme that employs Proximal Policy Optimization (PPO) for discrete decision-making and Linear Programming (LP) for offloading optimization. {The simulation results have validated the proposed framework's superiority over existing methods. Specifically, the proposed PPO-based hybrid optimization scheme reduces the average end-to-end latency by approximately 40% to 50% compared to Genetic Algorithm (GA) and Quantum-behaved Particle Swarm Optimization (QPSO). Moreover, the system demonstrates strong scalability by maintaining low latency even in congested scenarios with up to 30 vehicles.
Semantic-Aware Cooperative Communication and Computation Framework in Vehicular Networks
Dec 10, 2025Semantic Communication (SC) combined with Vehicular edge computing (VEC) provides an efficient edge task processing paradigm for Internet of Vehicles (IoV). Focusing on highway scenarios, this paper proposes a Tripartite Cooperative Semantic Communication (TCSC) framework, which enables Vehicle Users (VUs) to perform semantic task offloading via Vehicle-to-Infrastructure (V2I) and Vehicle-to-Vehicle (V2V) communications. Considering task latency and the number of semantic symbols, the framework constructs a Mixed-Integer Nonlinear Programming (MINLP) problem, which is transformed into two subproblems. First, we innovatively propose a multi-agent proximal policy optimization task offloading optimization method based on parametric distribution noise (MAPPO-PDN) to solve the optimization problem of the number of semantic symbols; second, linear programming (LP) is used to solve offloading ratio. Simulations show that performance of this scheme is superior to that of other algorithms.
A Comprehensive Survey on Joint Resource Allocation Strategies in Federated Edge Learning
Oct 10, 2024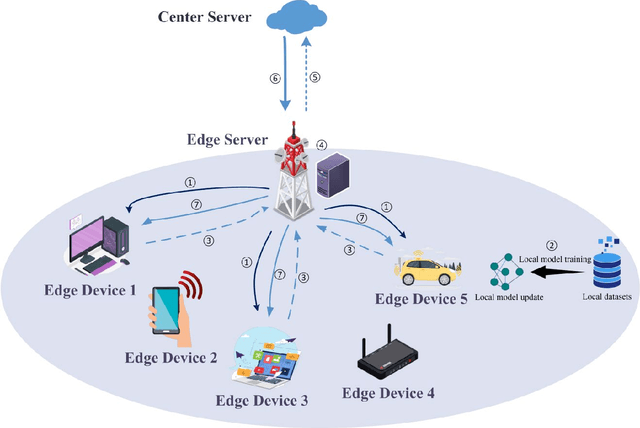
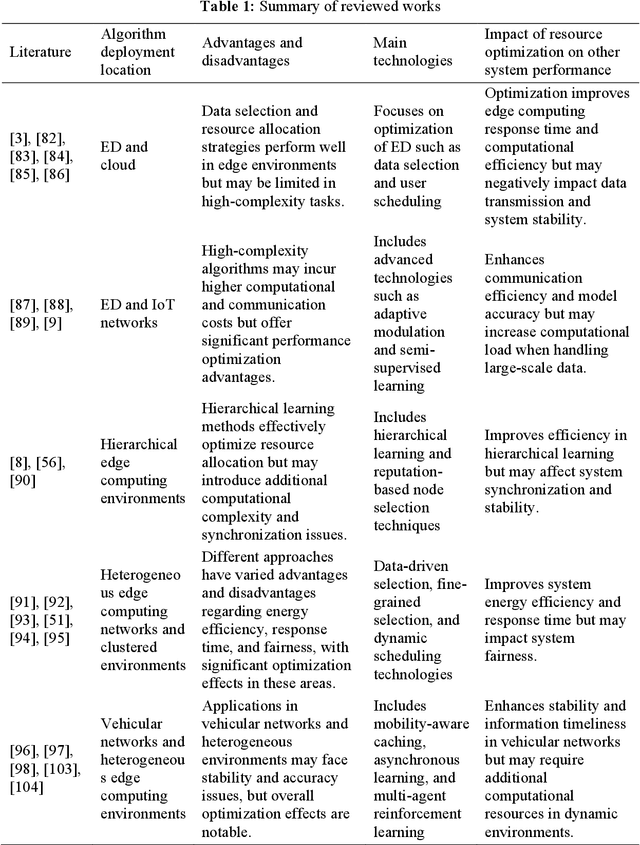
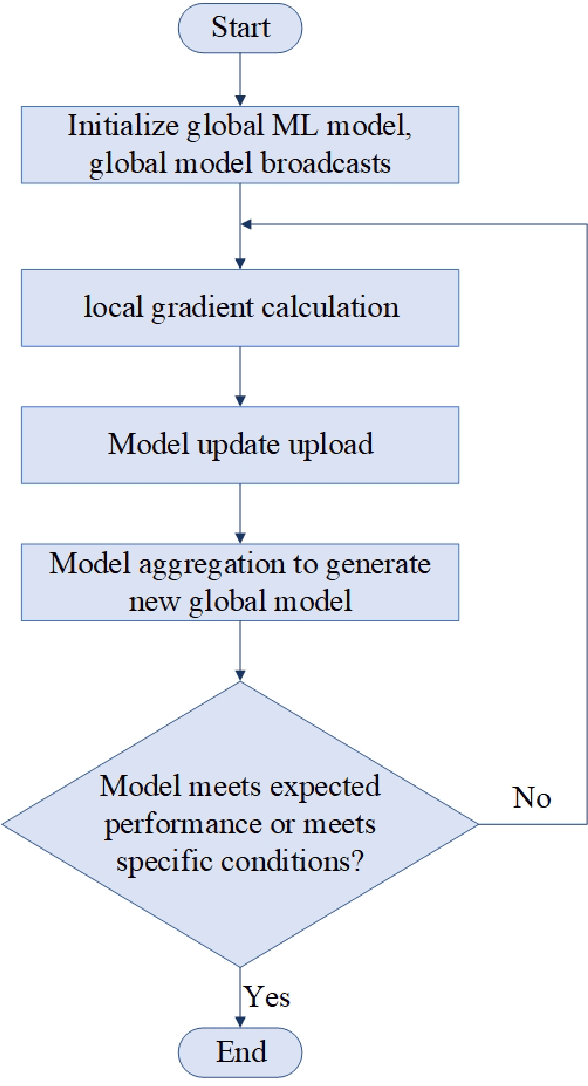
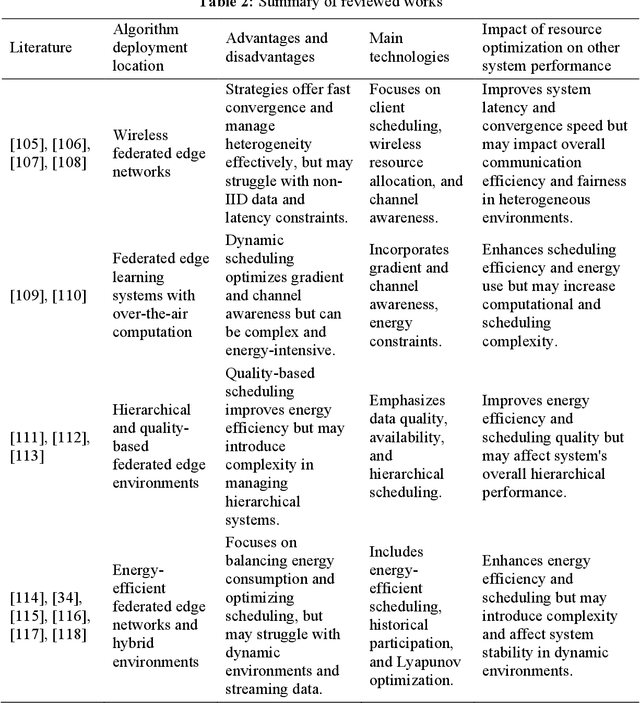
Federated Edge Learning (FEL), an emerging distributed Machine Learning (ML) paradigm, enables model training in a distributed environment while ensuring user privacy by using physical separation for each user data. However, with the development of complex application scenarios such as the Internet of Things (IoT) and Smart Earth, the conventional resource allocation schemes can no longer effectively support these growing computational and communication demands. Therefore, joint resource optimization may be the key solution to the scaling problem. This paper simultaneously addresses the multifaceted challenges of computation and communication, with the growing multiple resource demands. We systematically review the joint allocation strategies for different resources (computation, data, communication, and network topology) in FEL, and summarize the advantages in improving system efficiency, reducing latency, enhancing resource utilization and enhancing robustness. In addition, we present the potential ability of joint optimization to enhance privacy preservation by reducing communication requirements, indirectly. This work not only provides theoretical support for resource management in federated learning (FL) systems, but also provides ideas for potential optimal deployment in multiple real-world scenarios. By thoroughly discussing the current challenges and future research directions, it also provides some important insights into multi-resource optimization in complex application environments.
Generative Object Insertion in Gaussian Splatting with a Multi-View Diffusion Model
Sep 25, 2024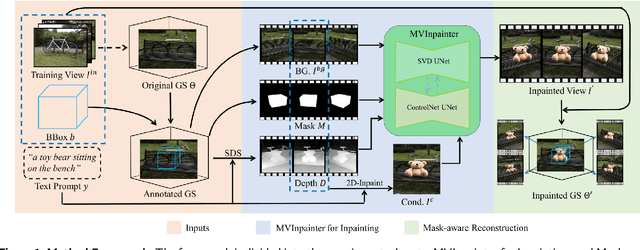
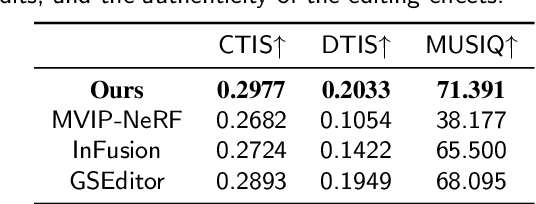


Generating and inserting new objects into 3D content is a compelling approach for achieving versatile scene recreation. Existing methods, which rely on SDS optimization or single-view inpainting, often struggle to produce high-quality results. To address this, we propose a novel method for object insertion in 3D content represented by Gaussian Splatting. Our approach introduces a multi-view diffusion model, dubbed MVInpainter, which is built upon a pre-trained stable video diffusion model to facilitate view-consistent object inpainting. Within MVInpainter, we incorporate a ControlNet-based conditional injection module to enable controlled and more predictable multi-view generation. After generating the multi-view inpainted results, we further propose a mask-aware 3D reconstruction technique to refine Gaussian Splatting reconstruction from these sparse inpainted views. By leveraging these fabricate techniques, our approach yields diverse results, ensures view-consistent and harmonious insertions, and produces better object quality. Extensive experiments demonstrate that our approach outperforms existing methods.
Hyper-Compression: Model Compression via Hyperfunction
Sep 01, 2024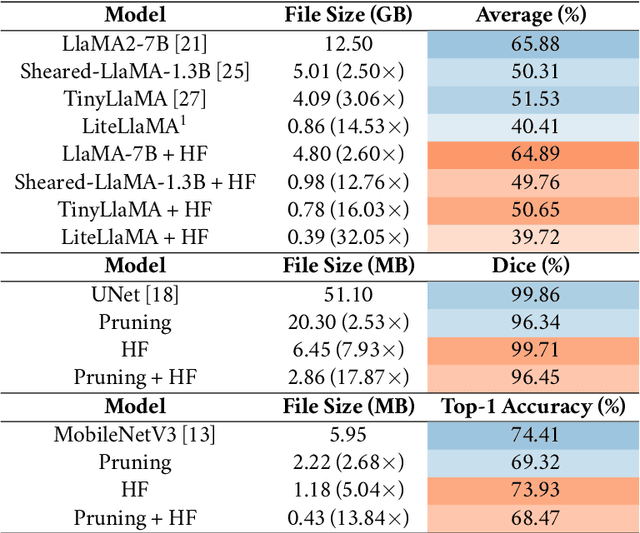
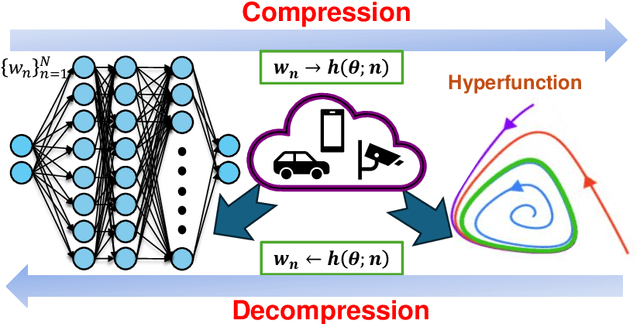
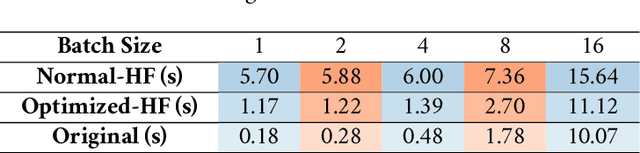

The rapid growth of large models' size has far outpaced that of GPU memory. To bridge this gap, inspired by the succinct relationship between genotype and phenotype, we turn the model compression problem into the issue of parameter representation to propose the so-called hyper-compression. The hyper-compression uses a hyperfunction to represent the parameters of the target network, and notably, here the hyperfunction is designed per ergodic theory that relates to a problem: if a low-dimensional dynamic system can fill the high-dimensional space eventually. Empirically, the proposed hyper-compression enjoys the following merits: 1) \textbf{P}referable compression ratio; 2) \textbf{N}o post-hoc retraining; 3) \textbf{A}ffordable inference time; and 4) \textbf{S}hort compression time. It compresses LLaMA2-7B in an hour and achieves close-to-int4-quantization performance, without retraining and with a performance drop of less than 1\%. Our work has the potential to invigorate the field of model compression, towards a harmony between the scaling law and the stagnation of hardware upgradation.
Advances in 3D Generation: A Survey
Jan 31, 2024
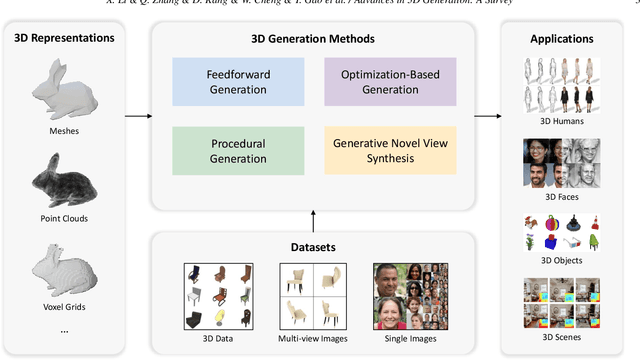
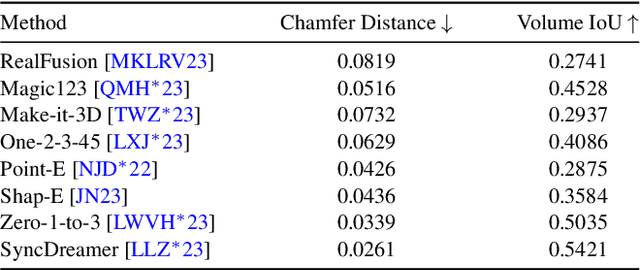
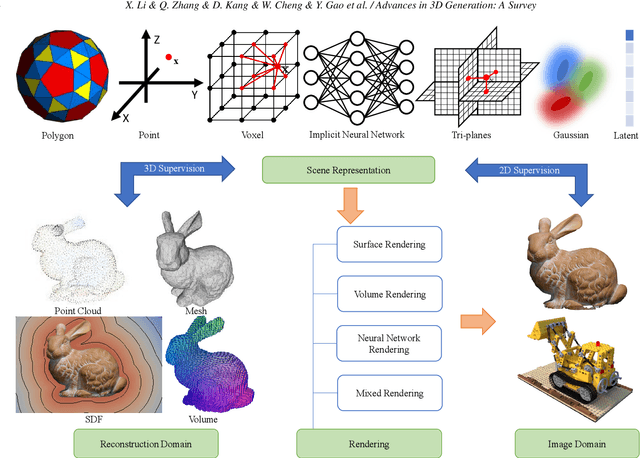
Generating 3D models lies at the core of computer graphics and has been the focus of decades of research. With the emergence of advanced neural representations and generative models, the field of 3D content generation is developing rapidly, enabling the creation of increasingly high-quality and diverse 3D models. The rapid growth of this field makes it difficult to stay abreast of all recent developments. In this survey, we aim to introduce the fundamental methodologies of 3D generation methods and establish a structured roadmap, encompassing 3D representation, generation methods, datasets, and corresponding applications. Specifically, we introduce the 3D representations that serve as the backbone for 3D generation. Furthermore, we provide a comprehensive overview of the rapidly growing literature on generation methods, categorized by the type of algorithmic paradigms, including feedforward generation, optimization-based generation, procedural generation, and generative novel view synthesis. Lastly, we discuss available datasets, applications, and open challenges. We hope this survey will help readers explore this exciting topic and foster further advancements in the field of 3D content generation.
HumanRef: Single Image to 3D Human Generation via Reference-Guided Diffusion
Nov 28, 2023

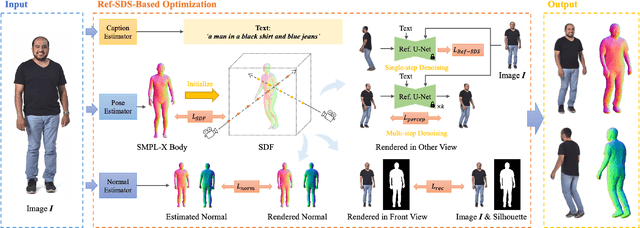
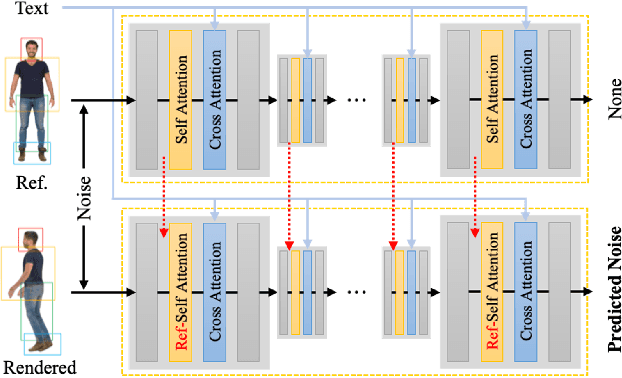
Generating a 3D human model from a single reference image is challenging because it requires inferring textures and geometries in invisible views while maintaining consistency with the reference image. Previous methods utilizing 3D generative models are limited by the availability of 3D training data. Optimization-based methods that lift text-to-image diffusion models to 3D generation often fail to preserve the texture details of the reference image, resulting in inconsistent appearances in different views. In this paper, we propose HumanRef, a 3D human generation framework from a single-view input. To ensure the generated 3D model is photorealistic and consistent with the input image, HumanRef introduces a novel method called reference-guided score distillation sampling (Ref-SDS), which effectively incorporates image guidance into the generation process. Furthermore, we introduce region-aware attention to Ref-SDS, ensuring accurate correspondence between different body regions. Experimental results demonstrate that HumanRef outperforms state-of-the-art methods in generating 3D clothed humans with fine geometry, photorealistic textures, and view-consistent appearances.
VQ-NeRF: Neural Reflectance Decomposition and Editing with Vector Quantization
Nov 05, 2023



We propose VQ-NeRF, a two-branch neural network model that incorporates Vector Quantization (VQ) to decompose and edit reflectance fields in 3D scenes. Conventional neural reflectance fields use only continuous representations to model 3D scenes, despite the fact that objects are typically composed of discrete materials in reality. This lack of discretization can result in noisy material decomposition and complicated material editing. To address these limitations, our model consists of a continuous branch and a discrete branch. The continuous branch follows the conventional pipeline to predict decomposed materials, while the discrete branch uses the VQ mechanism to quantize continuous materials into individual ones. By discretizing the materials, our model can reduce noise in the decomposition process and generate a segmentation map of discrete materials. Specific materials can be easily selected for further editing by clicking on the corresponding area of the segmentation outcomes. Additionally, we propose a dropout-based VQ codeword ranking strategy to predict the number of materials in a scene, which reduces redundancy in the material segmentation process. To improve usability, we also develop an interactive interface to further assist material editing. We evaluate our model on both computer-generated and real-world scenes, demonstrating its superior performance. To the best of our knowledge, our model is the first to enable discrete material editing in 3D scenes.
Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields
May 19, 2023



Text-driven 3D scene generation is widely applicable to video gaming, film industry, and metaverse applications that have a large demand for 3D scenes. However, existing text-to-3D generation methods are limited to producing 3D objects with simple geometries and dreamlike styles that lack realism. In this work, we present Text2NeRF, which is able to generate a wide range of 3D scenes with complicated geometric structures and high-fidelity textures purely from a text prompt. To this end, we adopt NeRF as the 3D representation and leverage a pre-trained text-to-image diffusion model to constrain the 3D reconstruction of the NeRF to reflect the scene description. Specifically, we employ the diffusion model to infer the text-related image as the content prior and use a monocular depth estimation method to offer the geometric prior. Both content and geometric priors are utilized to update the NeRF model. To guarantee textured and geometric consistency between different views, we introduce a progressive scene inpainting and updating strategy for novel view synthesis of the scene. Our method requires no additional training data but only a natural language description of the scene as the input. Extensive experiments demonstrate that our Text2NeRF outperforms existing methods in producing photo-realistic, multi-view consistent, and diverse 3D scenes from a variety of natural language prompts.