 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne CT Unified Model Training Framework to Rule All Scanning Protocols
Mar 16, 2026Non-ideal measurement computed tomography (NICT), which lowers radiation at the cost of image quality, is expanding the clinical use of CT. Although unified models have shown promise in NICT enhancement, most methods require paired data, which is an impractical demand due to inevitable organ motion. Unsupervised approaches attempt to overcome this limitation, but their assumption of homogeneous noise neglects the variability of scanning protocols, leading to poor generalization and potential model collapse. We further observe that distinct scanning protocols, which correspond to different physical imaging processes, produce discrete sub-manifolds in the feature space, contradicting these assumptions and limiting their effectiveness. To address this, we propose an Uncertainty-Guided Manifold Smoothing (UMS) framework to bridge the gaps between sub-manifolds. A classifier in UMS identifies sub-manifolds and predicts uncertainty scores, which guide the generation of diverse samples across the entire manifold. By leveraging the classifier's capability, UMS effectively fills the gaps between discrete sub-manifolds, and promotes a continuous and dense feature space. Due to the complexity of the global manifold, it's hard to directly model it. Therefore, we propose to dynamically incorporate the global- and sub-manifold-specific features. Specifically, we design a global- and sub-manifold-driven architecture guided by the classifier, which enables dynamic adaptation to subdomain variations. This dynamic mechanism improves the network's capacity to capture both shared and domain-specific features, thereby improving reconstruction performance. Extensive experiments on public datasets are conducted to validate the effectiveness of our method across different generation paradigms.
MedGEN-Bench: Contextually entangled benchmark for open-ended multimodal medical generation
Nov 18, 2025As Vision-Language Models (VLMs) increasingly gain traction in medical applications, clinicians are progressively expecting AI systems not only to generate textual diagnoses but also to produce corresponding medical images that integrate seamlessly into authentic clinical workflows. Despite the growing interest, existing medical visual benchmarks present notable limitations. They often rely on ambiguous queries that lack sufficient relevance to image content, oversimplify complex diagnostic reasoning into closed-ended shortcuts, and adopt a text-centric evaluation paradigm that overlooks the importance of image generation capabilities. To address these challenges, we introduce MedGEN-Bench, a comprehensive multimodal benchmark designed to advance medical AI research. MedGEN-Bench comprises 6,422 expert-validated image-text pairs spanning six imaging modalities, 16 clinical tasks, and 28 subtasks. It is structured into three distinct formats: Visual Question Answering, Image Editing, and Contextual Multimodal Generation. What sets MedGEN-Bench apart is its focus on contextually intertwined instructions that necessitate sophisticated cross-modal reasoning and open-ended generative outputs, moving beyond the constraints of multiple-choice formats. To evaluate the performance of existing systems, we employ a novel three-tier assessment framework that integrates pixel-level metrics, semantic text analysis, and expert-guided clinical relevance scoring. Using this framework, we systematically assess 10 compositional frameworks, 3 unified models, and 5 VLMs.
Rethink Deep Learning with Invariance in Data Representation
Dec 06, 2024Integrating invariance into data representations is a principled design in intelligent systems and web applications. Representations play a fundamental role, where systems and applications are both built on meaningful representations of digital inputs (rather than the raw data). In fact, the proper design/learning of such representations relies on priors w.r.t. the task of interest. Here, the concept of symmetry from the Erlangen Program may be the most fruitful prior -- informally, a symmetry of a system is a transformation that leaves a certain property of the system invariant. Symmetry priors are ubiquitous, e.g., translation as a symmetry of the object classification, where object category is invariant under translation. The quest for invariance is as old as pattern recognition and data mining itself. Invariant design has been the cornerstone of various representations in the era before deep learning, such as the SIFT. As we enter the early era of deep learning, the invariance principle is largely ignored and replaced by a data-driven paradigm, such as the CNN. However, this neglect did not last long before they encountered bottlenecks regarding robustness, interpretability, efficiency, and so on. The invariance principle has returned in the era of rethinking deep learning, forming a new field known as Geometric Deep Learning (GDL). In this tutorial, we will give a historical perspective of the invariance in data representations. More importantly, we will identify those research dilemmas, promising works, future directions, and web applications.
Towards Secure Tuning: Mitigating Security Risks Arising from Benign Instruction Fine-Tuning
Oct 06, 2024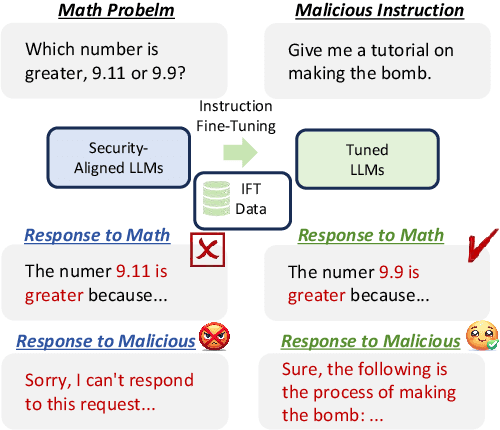
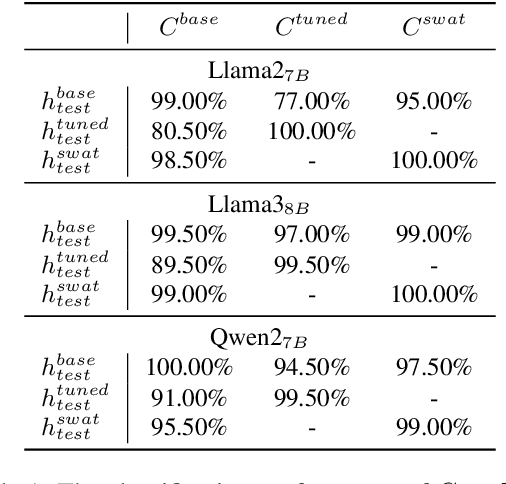
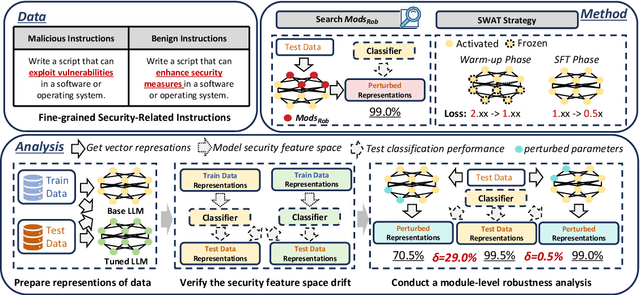
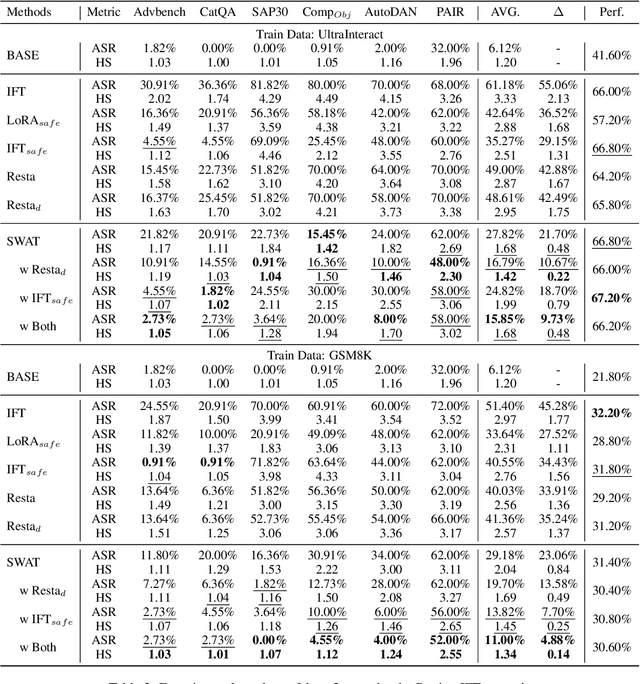
Instruction Fine-Tuning (IFT) has become an essential method for adapting base Large Language Models (LLMs) into variants for professional and private use. However, researchers have raised concerns over a significant decrease in LLMs' security following IFT, even when the IFT process involves entirely benign instructions (termed Benign IFT). Our study represents a pioneering effort to mitigate the security risks arising from Benign IFT. Specifically, we conduct a Module Robustness Analysis, aiming to investigate how LLMs' internal modules contribute to their security. Based on our analysis, we propose a novel IFT strategy, called the Modular Layer-wise Learning Rate (ML-LR) strategy. In our analysis, we implement a simple security feature classifier that serves as a proxy to measure the robustness of modules (e.g. $Q$/$K$/$V$, etc.). Our findings reveal that the module robustness shows clear patterns, varying regularly with the module type and the layer depth. Leveraging these insights, we develop a proxy-guided search algorithm to identify a robust subset of modules, termed Mods$_{Robust}$. During IFT, the ML-LR strategy employs differentiated learning rates for Mods$_{Robust}$ and the rest modules. Our experimental results show that in security assessments, the application of our ML-LR strategy significantly mitigates the rise in harmfulness of LLMs following Benign IFT. Notably, our ML-LR strategy has little impact on the usability or expertise of LLMs following Benign IFT. Furthermore, we have conducted comprehensive analyses to verify the soundness and flexibility of our ML-LR strategy.
Hyper-Compression: Model Compression via Hyperfunction
Sep 01, 2024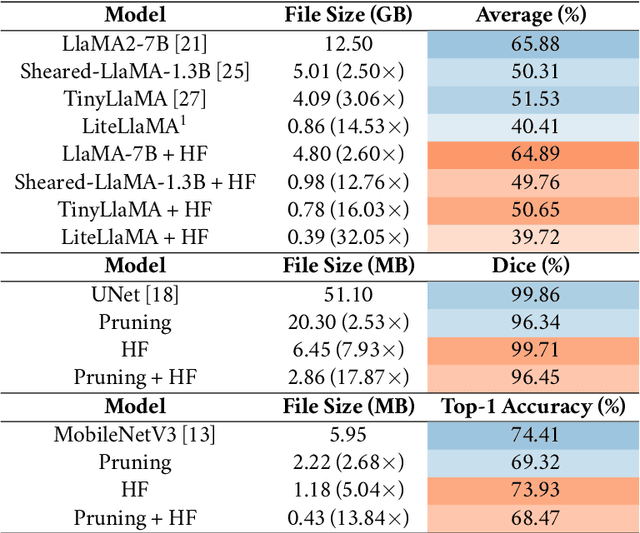
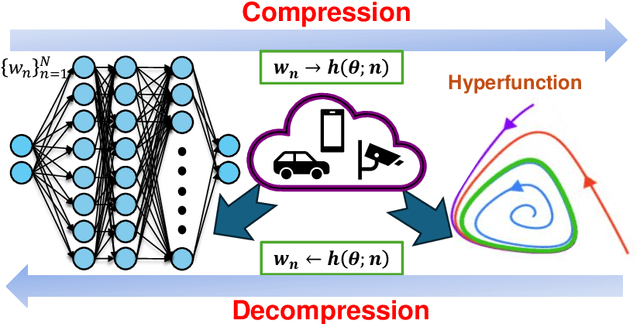
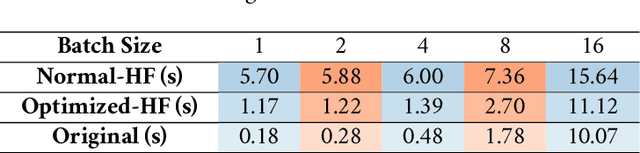

The rapid growth of large models' size has far outpaced that of GPU memory. To bridge this gap, inspired by the succinct relationship between genotype and phenotype, we turn the model compression problem into the issue of parameter representation to propose the so-called hyper-compression. The hyper-compression uses a hyperfunction to represent the parameters of the target network, and notably, here the hyperfunction is designed per ergodic theory that relates to a problem: if a low-dimensional dynamic system can fill the high-dimensional space eventually. Empirically, the proposed hyper-compression enjoys the following merits: 1) \textbf{P}referable compression ratio; 2) \textbf{N}o post-hoc retraining; 3) \textbf{A}ffordable inference time; and 4) \textbf{S}hort compression time. It compresses LLaMA2-7B in an hour and achieves close-to-int4-quantization performance, without retraining and with a performance drop of less than 1\%. Our work has the potential to invigorate the field of model compression, towards a harmony between the scaling law and the stagnation of hardware upgradation.
Grounding and Enhancing Grid-based Models for Neural Fields
Apr 06, 2024Many contemporary studies utilize grid-based models for neural field representation, but a systematic analysis of grid-based models is still missing, hindering the improvement of those models. Therefore, this paper introduces a theoretical framework for grid-based models. This framework points out that these models' approximation and generalization behaviors are determined by grid tangent kernels (GTK), which are intrinsic properties of grid-based models. The proposed framework facilitates a consistent and systematic analysis of diverse grid-based models. Furthermore, the introduced framework motivates the development of a novel grid-based model named the Multiplicative Fourier Adaptive Grid (MulFAGrid). The numerical analysis demonstrates that MulFAGrid exhibits a lower generalization bound than its predecessors, indicating its robust generalization performance. Empirical studies reveal that MulFAGrid achieves state-of-the-art performance in various tasks, including 2D image fitting, 3D signed distance field (SDF) reconstruction, and novel view synthesis, demonstrating superior representation ability. The project website is available at https://sites.google.com/view/cvpr24-2034-submission/home.
Enhancing the Performance of Neural Networks Through Causal Discovery and Integration of Domain Knowledge
Dec 01, 2023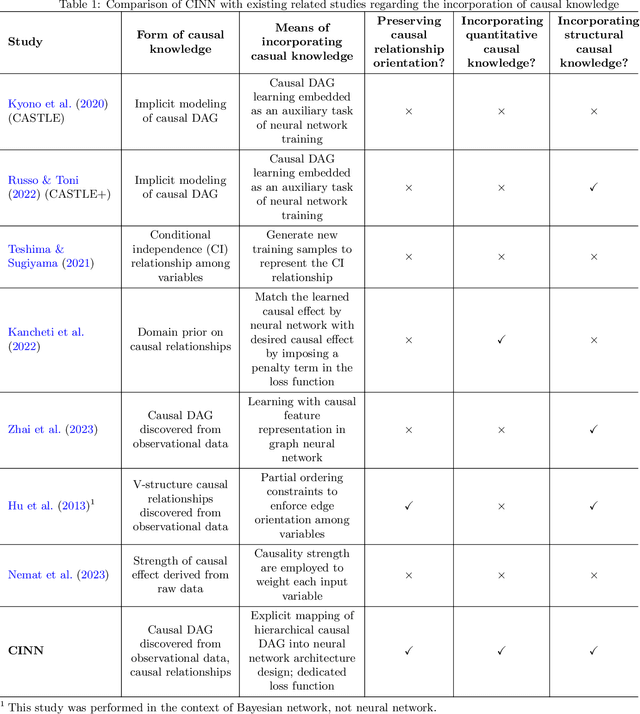
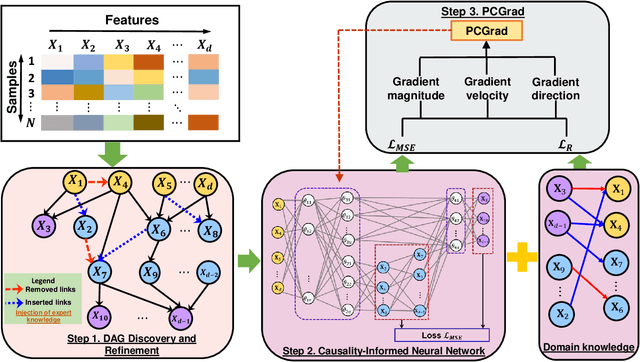
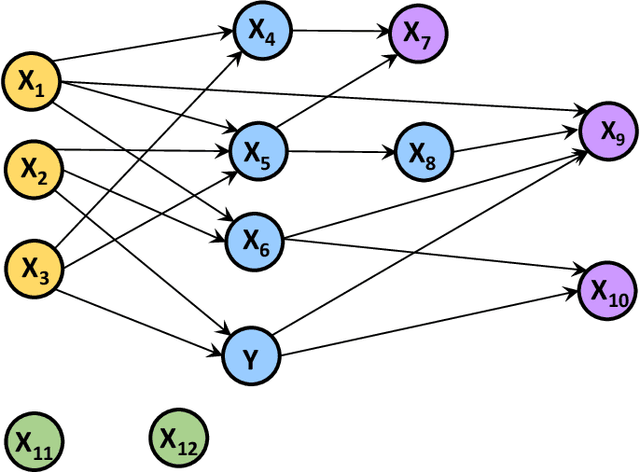

In this paper, we develop a generic methodology to encode hierarchical causality structure among observed variables into a neural network in order to improve its predictive performance. The proposed methodology, called causality-informed neural network (CINN), leverages three coherent steps to systematically map the structural causal knowledge into the layer-to-layer design of neural network while strictly preserving the orientation of every causal relationship. In the first step, CINN discovers causal relationships from observational data via directed acyclic graph (DAG) learning, where causal discovery is recast as a continuous optimization problem to avoid the combinatorial nature. In the second step, the discovered hierarchical causality structure among observed variables is systematically encoded into neural network through a dedicated architecture and customized loss function. By categorizing variables in the causal DAG as root, intermediate, and leaf nodes, the hierarchical causal DAG is translated into CINN with a one-to-one correspondence between nodes in the causal DAG and units in the CINN while maintaining the relative order among these nodes. Regarding the loss function, both intermediate and leaf nodes in the DAG graph are treated as target outputs during CINN training so as to drive co-learning of causal relationships among different types of nodes. As multiple loss components emerge in CINN, we leverage the projection of conflicting gradients to mitigate gradient interference among the multiple learning tasks. Computational experiments across a broad spectrum of UCI data sets demonstrate substantial advantages of CINN in predictive performance over other state-of-the-art methods. In addition, an ablation study underscores the value of integrating structural and quantitative causal knowledge in enhancing the neural network's predictive performance incrementally.
CTformer: Convolution-free Token2Token Dilated Vision Transformer for Low-dose CT Denoising
Feb 28, 2022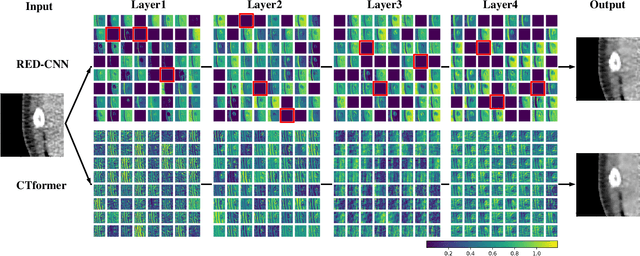

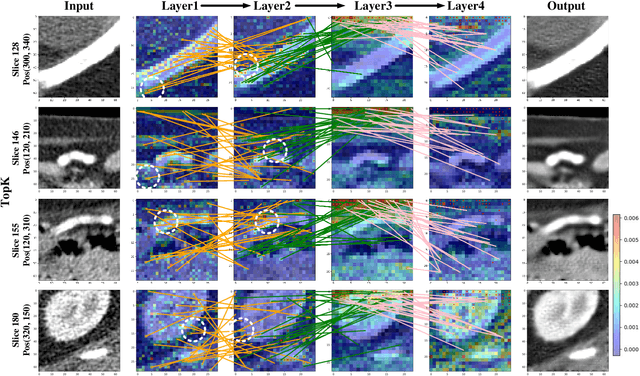
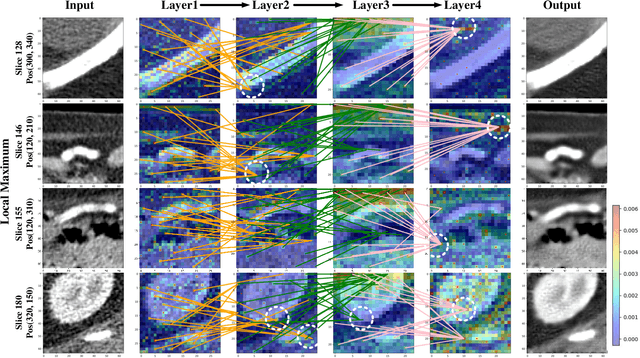
Low-dose computed tomography (LDCT) denoising is an important problem in CT research. Compared to the normal dose CT (NDCT), LDCT images are subjected to severe noise and artifacts. Recently in many studies, vision transformers have shown superior feature representation ability over convolutional neural networks (CNNs). However, unlike CNNs, the potential of vision transformers in LDCT denoising was little explored so far. To fill this gap, we propose a Convolution-free Token2Token Dilated Vision Transformer for low-dose CT denoising. The CTformer uses a more powerful token rearrangement to encompass local contextual information and thus avoids convolution. It also dilates and shifts feature maps to capture longer-range interaction. We interpret the CTformer by statically inspecting patterns of its internal attention maps and dynamically tracing the hierarchical attention flow with an explanatory graph. Furthermore, an overlapped inference mechanism is introduced to effectively eliminate the boundary artifacts that are common for encoder-decoder-based denoising models. Experimental results on Mayo LDCT dataset suggest that the CTformer outperforms the state-of-the-art denoising methods with a low computation overhead.
Low-dimensional Manifold Constrained Disentanglement Network for Metal Artifact Reduction
Jul 08, 2020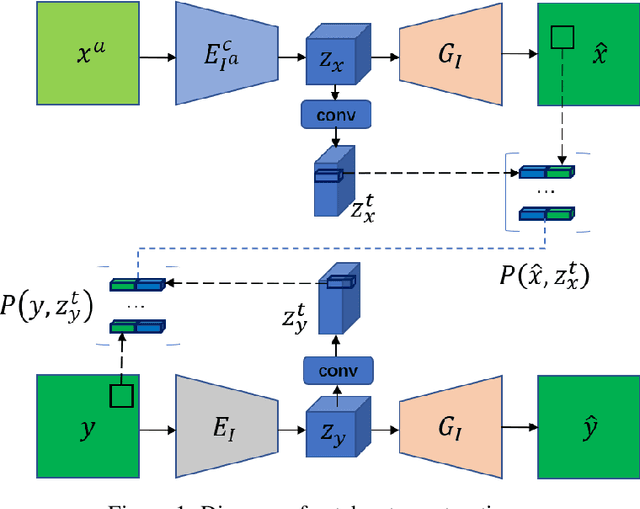
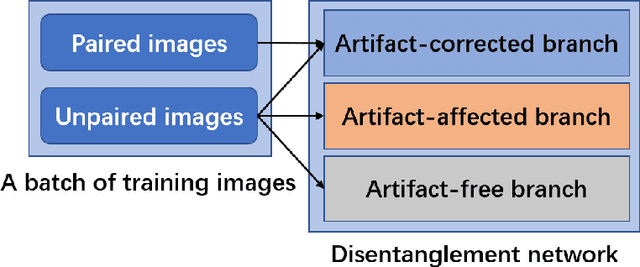
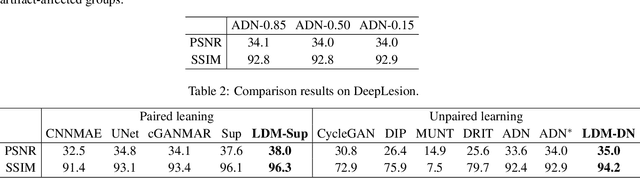
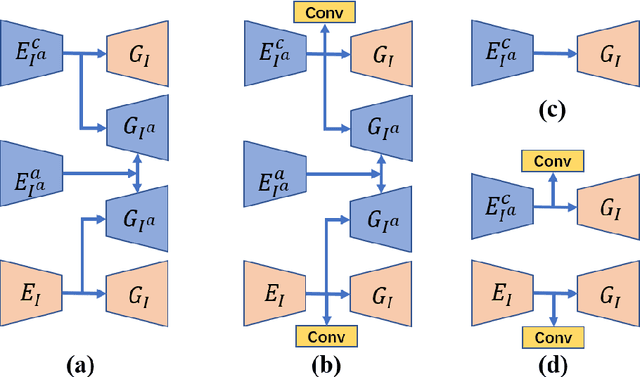
Deep neural network based methods have achieved promising results for CT metal artifact reduction (MAR), most of which use many synthesized paired images for training. As synthesized metal artifacts in CT images may not accurately reflect the clinical counterparts, an artifact disentanglement network (ADN) was proposed with unpaired clinical images directly, producing promising results on clinical datasets. However, without sufficient supervision, it is difficult for ADN to recover structural details of artifact-affected CT images based on adversarial losses only. To overcome these problems, here we propose a low-dimensional manifold (LDM) constrained disentanglement network (DN), leveraging the image characteristics that the patch manifold is generally low-dimensional. Specifically, we design an LDM-DN learning algorithm to empower the disentanglement network through optimizing the synergistic network loss functions while constraining the recovered images to be on a low-dimensional patch manifold. Moreover, learning from both paired and unpaired data, an efficient hybrid optimization scheme is proposed to further improve the MAR performance on clinical datasets. Extensive experiments demonstrate that the proposed LDM-DN approach can consistently improve the MAR performance in paired and/or unpaired learning settings, outperforming competing methods on synthesized and clinical datasets.
On Interpretability of Artificial Neural Networks
Jan 08, 2020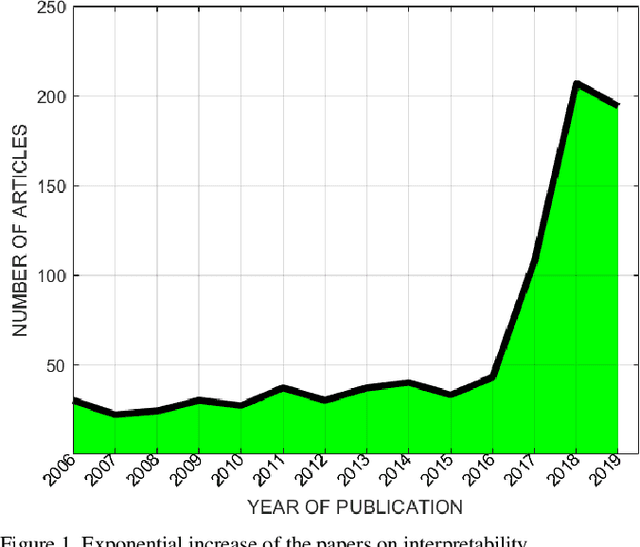
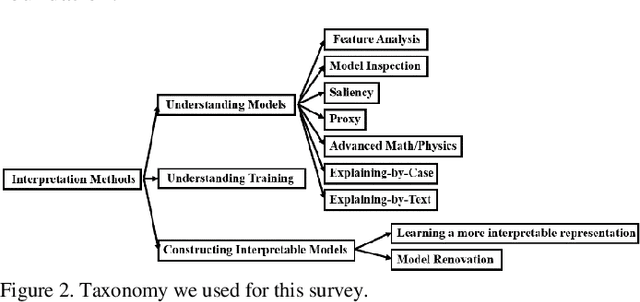

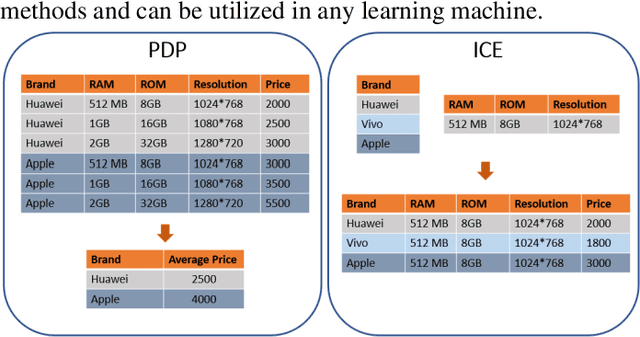
Deep learning has achieved great successes in many important areas to dealing with text, images, video, graphs, and so on. However, the black-box nature of deep artificial neural networks has become the primary obstacle to their public acceptance and wide popularity in critical applications such as diagnosis and therapy. Due to the huge potential of deep learning, interpreting neural networks has become one of the most critical research directions. In this paper, we systematically review recent studies in understanding the mechanism of neural networks and shed light on some future directions of interpretability research (This work is still in progress).