 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Evaluated Stand-alone Attention-Assisted Graph Neural Network with Spatial and Structural Information Interaction for Precise Endoscopic Image Segmentation
Aug 09, 2025Accurate endoscopic image segmentation on the polyps is critical for early colorectal cancer detection. However, this task remains challenging due to low contrast with surrounding mucosa, specular highlights, and indistinct boundaries. To address these challenges, we propose FOCUS-Med, which stands for Fusion of spatial and structural graph with attentional context-aware polyp segmentation in endoscopic medical imaging. FOCUS-Med integrates a Dual Graph Convolutional Network (Dual-GCN) module to capture contextual spatial and topological structural dependencies. This graph-based representation enables the model to better distinguish polyps from background tissues by leveraging topological cues and spatial connectivity, which are often obscured in raw image intensities. It enhances the model's ability to preserve boundaries and delineate complex shapes typical of polyps. In addition, a location-fused stand-alone self-attention is employed to strengthen global context integration. To bridge the semantic gap between encoder-decoder layers, we incorporate a trainable weighted fast normalized fusion strategy for efficient multi-scale aggregation. Notably, we are the first to introduce the use of a Large Language Model (LLM) to provide detailed qualitative evaluations of segmentation quality. Extensive experiments on public benchmarks demonstrate that FOCUS-Med achieves state-of-the-art performance across five key metrics, underscoring its effectiveness and clinical potential for AI-assisted colonoscopy.
Hyper-Compression: Model Compression via Hyperfunction
Sep 01, 2024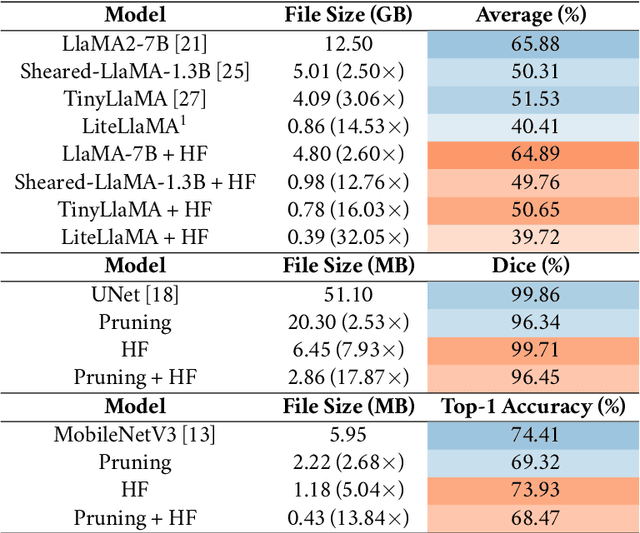
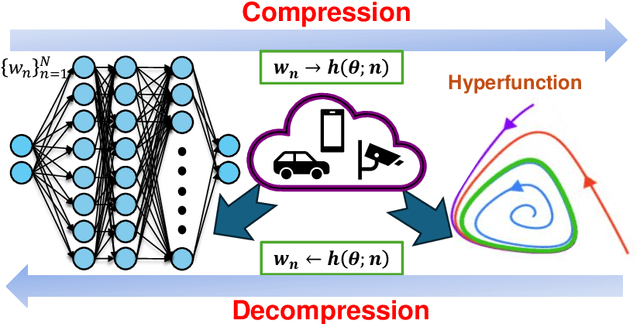
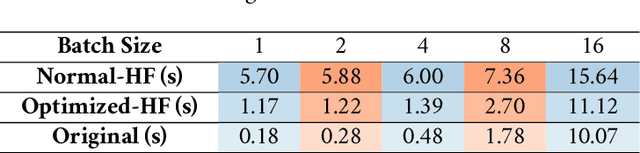

The rapid growth of large models' size has far outpaced that of GPU memory. To bridge this gap, inspired by the succinct relationship between genotype and phenotype, we turn the model compression problem into the issue of parameter representation to propose the so-called hyper-compression. The hyper-compression uses a hyperfunction to represent the parameters of the target network, and notably, here the hyperfunction is designed per ergodic theory that relates to a problem: if a low-dimensional dynamic system can fill the high-dimensional space eventually. Empirically, the proposed hyper-compression enjoys the following merits: 1) \textbf{P}referable compression ratio; 2) \textbf{N}o post-hoc retraining; 3) \textbf{A}ffordable inference time; and 4) \textbf{S}hort compression time. It compresses LLaMA2-7B in an hour and achieves close-to-int4-quantization performance, without retraining and with a performance drop of less than 1\%. Our work has the potential to invigorate the field of model compression, towards a harmony between the scaling law and the stagnation of hardware upgradation.
DSFNet: Convolutional Encoder-Decoder Architecture Combined Dual-GCN and Stand-alone Self-attention by Fast Normalized Fusion for Polyps Segmentation
Aug 15, 2023In the past few decades, deep learning technology has been widely used in medical image segmentation and has made significant breakthroughs in the fields of liver and liver tumor segmentation, brain and brain tumor segmentation, video disc segmentation, heart image segmentation, and so on. However, the segmentation of polyps is still a challenging task since the surface of the polyps is flat and the color is very similar to that of surrounding tissues. Thus, It leads to the problems of the unclear boundary between polyps and surrounding mucosa, local overexposure, and bright spot reflection. To counter this problem, this paper presents a novel U-shaped network, namely DSFNet, which effectively combines the advantages of Dual-GCN and self-attention mechanisms. First, we introduce a feature enhancement block module based on Dual-GCN module as an attention mechanism to enhance the feature extraction of local spatial and structural information with fine granularity. Second, the stand-alone self-attention module is designed to enhance the integration ability of the decoding stage model to global information. Finally, the Fast Normalized Fusion method with trainable weights is used to efficiently fuse the corresponding three feature graphs in encoding, bottleneck, and decoding blocks, thus promoting information transmission and reducing the semantic gap between encoder and decoder. Our model is tested on two public datasets including Endoscene and Kvasir-SEG and compared with other state-of-the-art models. Experimental results show that the proposed model surpasses other competitors in many indicators, such as Dice, MAE, and IoU. In the meantime, ablation studies are also conducted to verify the efficacy and effectiveness of each module. Qualitative and quantitative analysis indicates that the proposed model has great clinical significance.