 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Evaluated Stand-alone Attention-Assisted Graph Neural Network with Spatial and Structural Information Interaction for Precise Endoscopic Image Segmentation
Aug 09, 2025Accurate endoscopic image segmentation on the polyps is critical for early colorectal cancer detection. However, this task remains challenging due to low contrast with surrounding mucosa, specular highlights, and indistinct boundaries. To address these challenges, we propose FOCUS-Med, which stands for Fusion of spatial and structural graph with attentional context-aware polyp segmentation in endoscopic medical imaging. FOCUS-Med integrates a Dual Graph Convolutional Network (Dual-GCN) module to capture contextual spatial and topological structural dependencies. This graph-based representation enables the model to better distinguish polyps from background tissues by leveraging topological cues and spatial connectivity, which are often obscured in raw image intensities. It enhances the model's ability to preserve boundaries and delineate complex shapes typical of polyps. In addition, a location-fused stand-alone self-attention is employed to strengthen global context integration. To bridge the semantic gap between encoder-decoder layers, we incorporate a trainable weighted fast normalized fusion strategy for efficient multi-scale aggregation. Notably, we are the first to introduce the use of a Large Language Model (LLM) to provide detailed qualitative evaluations of segmentation quality. Extensive experiments on public benchmarks demonstrate that FOCUS-Med achieves state-of-the-art performance across five key metrics, underscoring its effectiveness and clinical potential for AI-assisted colonoscopy.
Hyper-Compression: Model Compression via Hyperfunction
Sep 01, 2024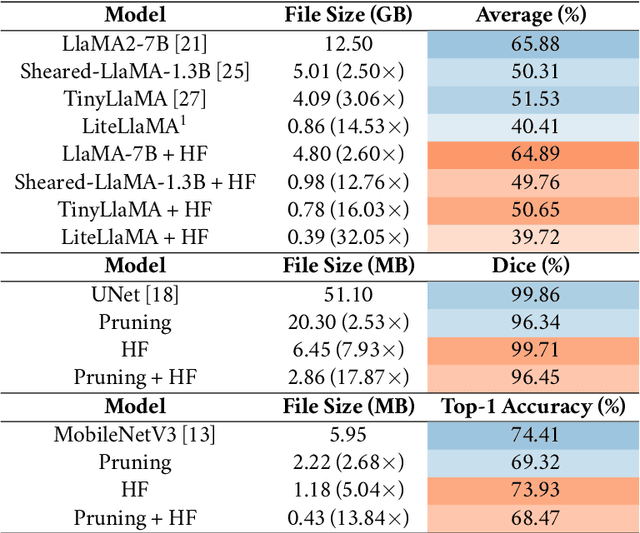
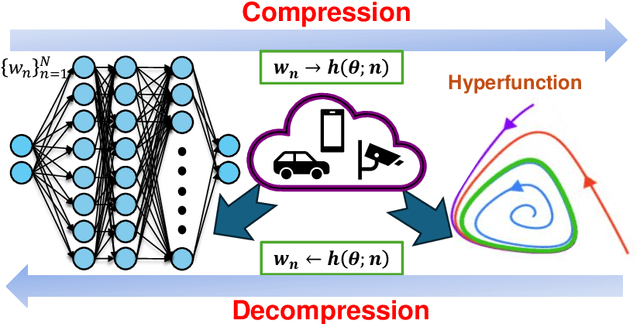
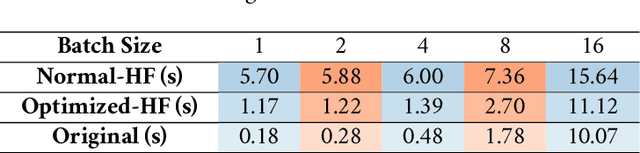

The rapid growth of large models' size has far outpaced that of GPU memory. To bridge this gap, inspired by the succinct relationship between genotype and phenotype, we turn the model compression problem into the issue of parameter representation to propose the so-called hyper-compression. The hyper-compression uses a hyperfunction to represent the parameters of the target network, and notably, here the hyperfunction is designed per ergodic theory that relates to a problem: if a low-dimensional dynamic system can fill the high-dimensional space eventually. Empirically, the proposed hyper-compression enjoys the following merits: 1) \textbf{P}referable compression ratio; 2) \textbf{N}o post-hoc retraining; 3) \textbf{A}ffordable inference time; and 4) \textbf{S}hort compression time. It compresses LLaMA2-7B in an hour and achieves close-to-int4-quantization performance, without retraining and with a performance drop of less than 1\%. Our work has the potential to invigorate the field of model compression, towards a harmony between the scaling law and the stagnation of hardware upgradation.
Physics-informed Score-based Diffusion Model for Limited-angle Reconstruction of Cardiac Computed Tomography
May 23, 2024



Cardiac computed tomography (CT) has emerged as a major imaging modality for the diagnosis and monitoring of cardiovascular diseases. High temporal resolution is essential to ensure diagnostic accuracy. Limited-angle data acquisition can reduce scan time and improve temporal resolution, but typically leads to severe image degradation and motivates for improved reconstruction techniques. In this paper, we propose a novel physics-informed score-based diffusion model (PSDM) for limited-angle reconstruction of cardiac CT. At the sampling time, we combine a data prior from a diffusion model and a model prior obtained via an iterative algorithm and Fourier fusion to further enhance the image quality. Specifically, our approach integrates the primal-dual hybrid gradient (PDHG) algorithm with score-based diffusion models, thereby enabling us to reconstruct high-quality cardiac CT images from limited-angle data. The numerical simulations and real data experiments confirm the effectiveness of our proposed approach.
LoMAE: Low-level Vision Masked Autoencoders for Low-dose CT Denoising
Oct 19, 2023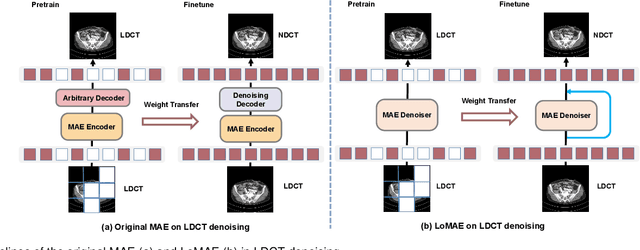
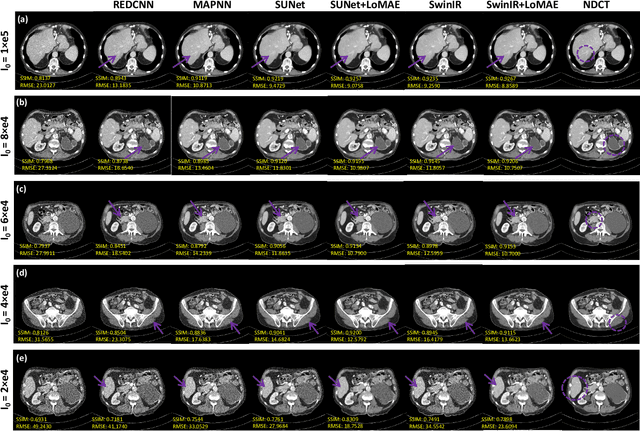
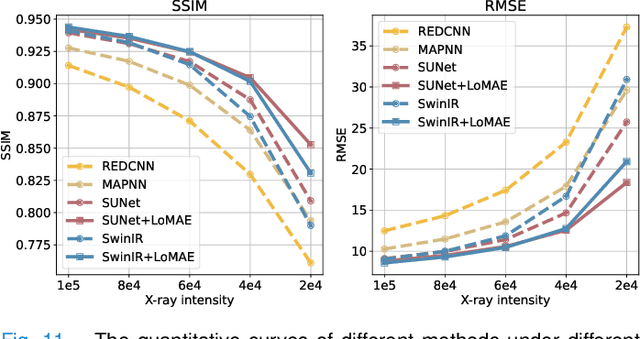
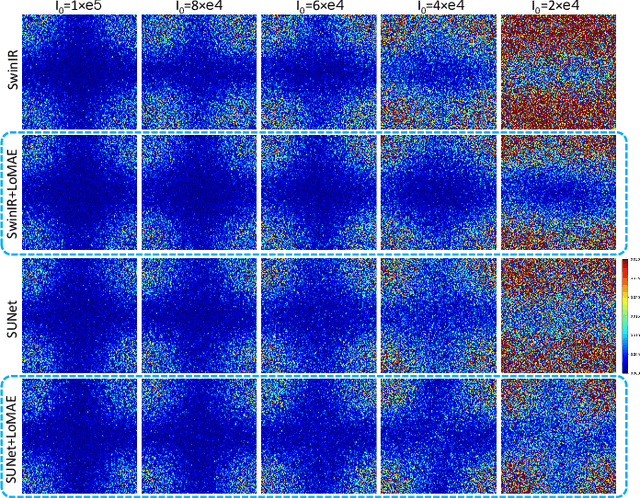
Low-dose computed tomography (LDCT) offers reduced X-ray radiation exposure but at the cost of compromised image quality, characterized by increased noise and artifacts. Recently, transformer models emerged as a promising avenue to enhance LDCT image quality. However, the success of such models relies on a large amount of paired noisy and clean images, which are often scarce in clinical settings. In the fields of computer vision and natural language processing, masked autoencoders (MAE) have been recognized as an effective label-free self-pretraining method for transformers, due to their exceptional feature representation ability. However, the original pretraining and fine-tuning design fails to work in low-level vision tasks like denoising. In response to this challenge, we redesign the classical encoder-decoder learning model and facilitate a simple yet effective low-level vision MAE, referred to as LoMAE, tailored to address the LDCT denoising problem. Moreover, we introduce an MAE-GradCAM method to shed light on the latent learning mechanisms of the MAE/LoMAE. Additionally, we explore the LoMAE's robustness and generability across a variety of noise levels. Experiments results show that the proposed LoMAE can enhance the transformer's denoising performance and greatly relieve the dependence on the ground truth clean data. It also demonstrates remarkable robustness and generalizability over a spectrum of noise levels.
DSFNet: Convolutional Encoder-Decoder Architecture Combined Dual-GCN and Stand-alone Self-attention by Fast Normalized Fusion for Polyps Segmentation
Aug 15, 2023In the past few decades, deep learning technology has been widely used in medical image segmentation and has made significant breakthroughs in the fields of liver and liver tumor segmentation, brain and brain tumor segmentation, video disc segmentation, heart image segmentation, and so on. However, the segmentation of polyps is still a challenging task since the surface of the polyps is flat and the color is very similar to that of surrounding tissues. Thus, It leads to the problems of the unclear boundary between polyps and surrounding mucosa, local overexposure, and bright spot reflection. To counter this problem, this paper presents a novel U-shaped network, namely DSFNet, which effectively combines the advantages of Dual-GCN and self-attention mechanisms. First, we introduce a feature enhancement block module based on Dual-GCN module as an attention mechanism to enhance the feature extraction of local spatial and structural information with fine granularity. Second, the stand-alone self-attention module is designed to enhance the integration ability of the decoding stage model to global information. Finally, the Fast Normalized Fusion method with trainable weights is used to efficiently fuse the corresponding three feature graphs in encoding, bottleneck, and decoding blocks, thus promoting information transmission and reducing the semantic gap between encoder and decoder. Our model is tested on two public datasets including Endoscene and Kvasir-SEG and compared with other state-of-the-art models. Experimental results show that the proposed model surpasses other competitors in many indicators, such as Dice, MAE, and IoU. In the meantime, ablation studies are also conducted to verify the efficacy and effectiveness of each module. Qualitative and quantitative analysis indicates that the proposed model has great clinical significance.
Simulation of Arbitrary Level Contrast Dose in MRI Using an Iterative Global Transformer Model
Jul 22, 2023



Deep learning (DL) based contrast dose reduction and elimination in MRI imaging is gaining traction, given the detrimental effects of Gadolinium-based Contrast Agents (GBCAs). These DL algorithms are however limited by the availability of high quality low dose datasets. Additionally, different types of GBCAs and pathologies require different dose levels for the DL algorithms to work reliably. In this work, we formulate a novel transformer (Gformer) based iterative modelling approach for the synthesis of images with arbitrary contrast enhancement that corresponds to different dose levels. The proposed Gformer incorporates a sub-sampling based attention mechanism and a rotational shift module that captures the various contrast related features. Quantitative evaluation indicates that the proposed model performs better than other state-of-the-art methods. We further perform quantitative evaluation on downstream tasks such as dose reduction and tumor segmentation to demonstrate the clinical utility.
Masked Autoencoders for Low dose CT denoising
Oct 10, 2022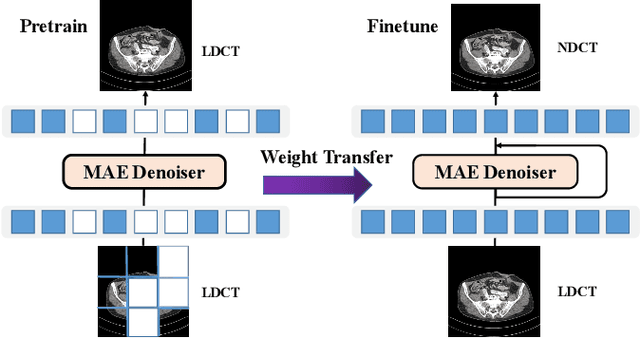
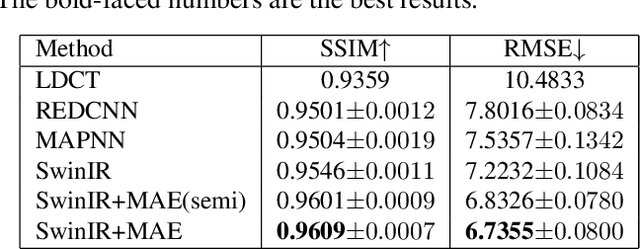
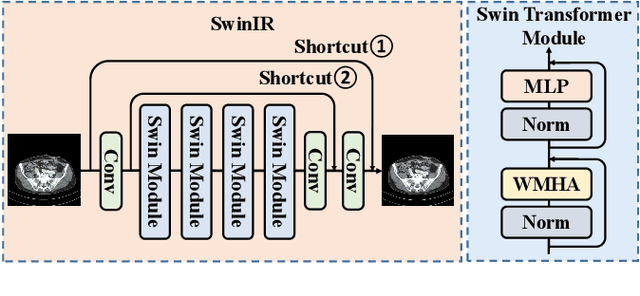
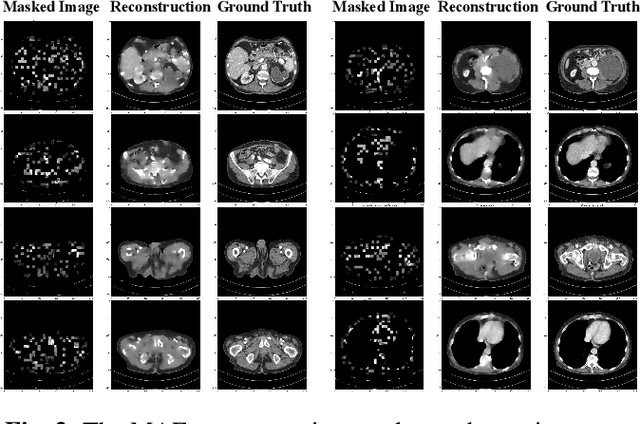
Low-dose computed tomography (LDCT) reduces the X-ray radiation but compromises image quality with more noises and artifacts. A plethora of transformer models have been developed recently to improve LDCT image quality. However, the success of a transformer model relies on a large amount of paired noisy and clean data, which is often unavailable in clinical applications. In computer vision and natural language processing fields, masked autoencoders (MAE) have been proposed as an effective label-free self-pretraining method for transformers, due to its excellent feature representation ability. Here, we redesign the classical encoder-decoder learning model to match the denoising task and apply it to LDCT denoising problem. The MAE can leverage the unlabeled data and facilitate structural preservation for the LDCT denoising model when ground truth data are missing. Experiments on the Mayo dataset validate that the MAE can boost the transformer's denoising performance and relieve the dependence on the ground truth data.
SQ-Swin: a Pretrained Siamese Quadratic Swin Transformer for Lettuce Browning Prediction
Sep 16, 2022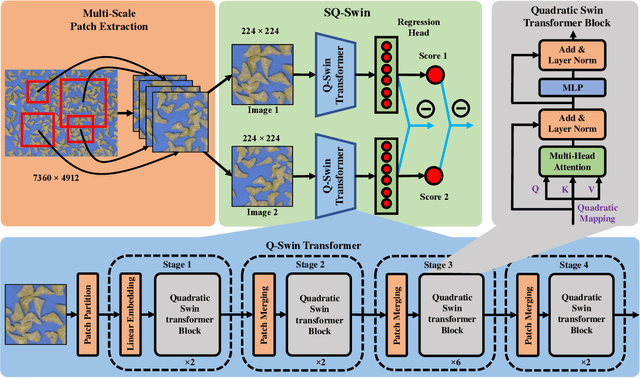

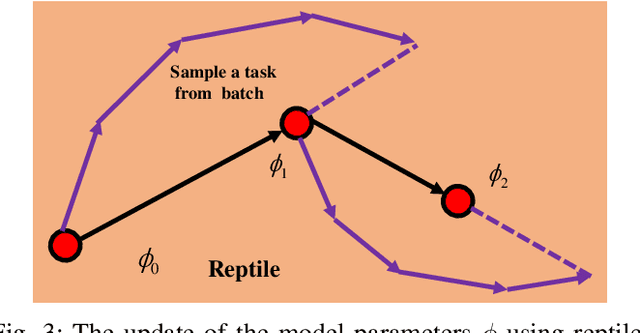

Packaged fresh-cut lettuce is widely consumed as a major component of vegetable salad owing to its high nutrition, freshness, and convenience. However, enzymatic browning discoloration on lettuce cut edges significantly reduces product quality and shelf life. While there are many research and breeding efforts underway to minimize browning, the progress is hindered by the lack of a rapid and reliable methodology to evaluate browning. Current methods to identify and quantify browning are either too subjective, labor intensive, or inaccurate. In this paper, we report a deep learning model for lettuce browning prediction. To the best of our knowledge, it is the first-of-its-kind on deep learning for lettuce browning prediction using a pretrained Siamese Quadratic Swin (SQ-Swin) transformer with several highlights. First, our model includes quadratic features in the transformer model which is more powerful to incorporate real-world representations than the linear transformer. Second, a multi-scale training strategy is proposed to augment the data and explore more of the inherent self-similarity of the lettuce images. Third, the proposed model uses a siamese architecture which learns the inter-relations among the limited training samples. Fourth, the model is pretrained on the ImageNet and then trained with the reptile meta-learning algorithm to learn higher-order gradients than a regular one. Experiment results on the fresh-cut lettuce datasets show that the proposed SQ-Swin outperforms the traditional methods and other deep learning-based backbones.
CTformer: Convolution-free Token2Token Dilated Vision Transformer for Low-dose CT Denoising
Feb 28, 2022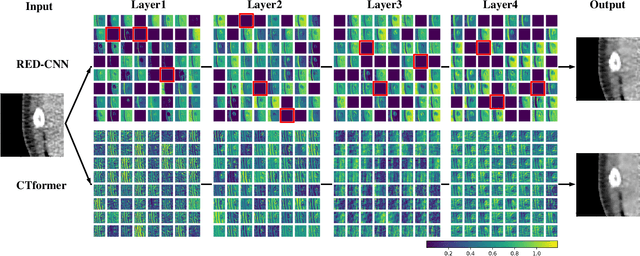

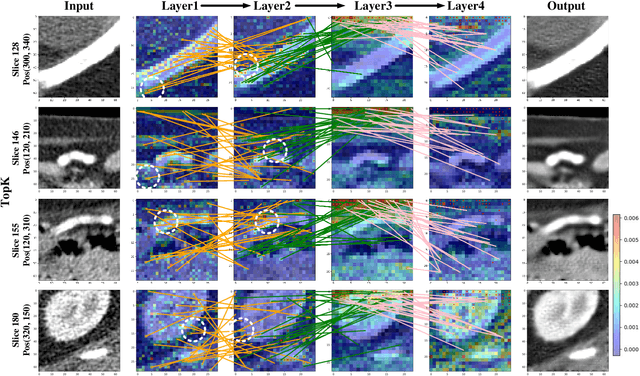
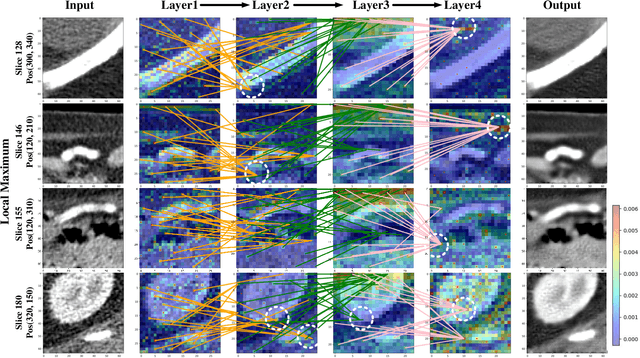
Low-dose computed tomography (LDCT) denoising is an important problem in CT research. Compared to the normal dose CT (NDCT), LDCT images are subjected to severe noise and artifacts. Recently in many studies, vision transformers have shown superior feature representation ability over convolutional neural networks (CNNs). However, unlike CNNs, the potential of vision transformers in LDCT denoising was little explored so far. To fill this gap, we propose a Convolution-free Token2Token Dilated Vision Transformer for low-dose CT denoising. The CTformer uses a more powerful token rearrangement to encompass local contextual information and thus avoids convolution. It also dilates and shifts feature maps to capture longer-range interaction. We interpret the CTformer by statically inspecting patterns of its internal attention maps and dynamically tracing the hierarchical attention flow with an explanatory graph. Furthermore, an overlapped inference mechanism is introduced to effectively eliminate the boundary artifacts that are common for encoder-decoder-based denoising models. Experimental results on Mayo LDCT dataset suggest that the CTformer outperforms the state-of-the-art denoising methods with a low computation overhead.
Manifoldron: Direct Space Partition via Manifold Discovery
Jan 14, 2022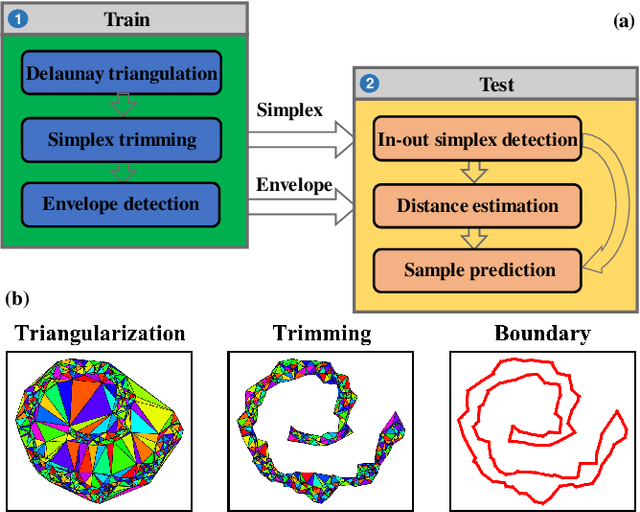
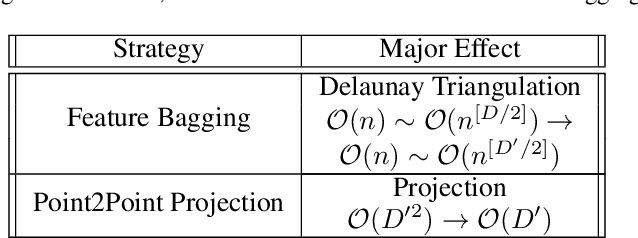
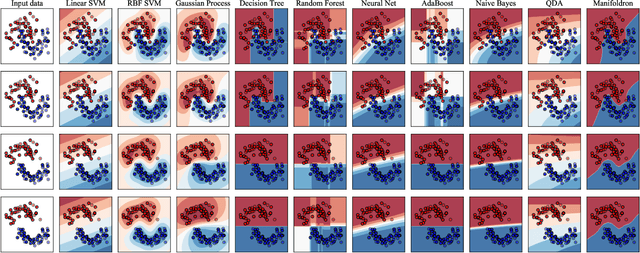
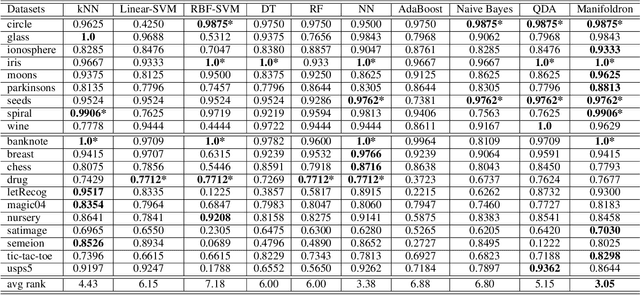
A neural network with the widely-used ReLU activation has been shown to partition the sample space into many convex polytopes for prediction. However, the parameterized way a neural network and other machine learning models use to partition the space has imperfections, e.g., the compromised interpretability for complex models, the inflexibility in decision boundary construction due to the generic character of the model, and the risk of being trapped into shortcut solutions. In contrast, although the non-parameterized models can adorably avoid or downplay these issues, they are usually insufficiently powerful either due to over-simplification or the failure to accommodate the manifold structures of data. In this context, we first propose a new type of machine learning models referred to as Manifoldron that directly derives decision boundaries from data and partitions the space via manifold structure discovery. Then, we systematically analyze the key characteristics of the Manifoldron including interpretability, manifold characterization capability, and its link to neural networks. The experimental results on 9 small and 11 large datasets demonstrate that the proposed Manifoldron performs competitively compared to the mainstream machine learning models. We have shared our code https://github.com/wdayang/Manifoldron for free download and evaluation.