 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoCGM: Poisson-Conditioned Generative Model for Sparse-View CT Reconstruction
Nov 17, 2025In computed tomography (CT), reducing the number of projection views is an effective strategy to lower radiation exposure and/or improve temporal resolution. However, this often results in severe aliasing artifacts and loss of structural details in reconstructed images, posing significant challenges for clinical applications. Inspired by the success of the Poisson Flow Generative Model (PFGM++) in natural image generation, we propose a PoCGM (Poisson-Conditioned Generative Model) to address the challenges of sparse-view CT reconstruction. Since PFGM++ was originally designed for unconditional generation, it lacks direct applicability to medical imaging tasks that require integrating conditional inputs. To overcome this limitation, the PoCGM reformulates PFGM++ into a conditional generative framework by incorporating sparse-view data as guidance during both training and sampling phases. By modeling the posterior distribution of full-view reconstructions conditioned on sparse observations, PoCGM effectively suppresses artifacts while preserving fine structural details. Qualitative and quantitative evaluations demonstrate that PoCGM outperforms the baselines, achieving improved artifact suppression, enhanced detail preservation, and reliable performance in dose-sensitive and time-critical imaging scenarios.
ResPF: Residual Poisson Flow for Efficient and Physically Consistent Sparse-View CT Reconstruction
Jun 06, 2025Sparse-view computed tomography (CT) is a practical solution to reduce radiation dose, but the resulting ill-posed inverse problem poses significant challenges for accurate image reconstruction. Although deep learning and diffusion-based methods have shown promising results, they often lack physical interpretability or suffer from high computational costs due to iterative sampling starting from random noise. Recent advances in generative modeling, particularly Poisson Flow Generative Models (PFGM), enable high-fidelity image synthesis by modeling the full data distribution. In this work, we propose Residual Poisson Flow (ResPF) Generative Models for efficient and accurate sparse-view CT reconstruction. Based on PFGM++, ResPF integrates conditional guidance from sparse measurements and employs a hijacking strategy to significantly reduce sampling cost by skipping redundant initial steps. However, skipping early stages can degrade reconstruction quality and introduce unrealistic structures. To address this, we embed a data-consistency into each iteration, ensuring fidelity to sparse-view measurements. Yet, PFGM sampling relies on a fixed ordinary differential equation (ODE) trajectory induced by electrostatic fields, which can be disrupted by step-wise data consistency, resulting in unstable or degraded reconstructions. Inspired by ResNet, we introduce a residual fusion module to linearly combine generative outputs with data-consistent reconstructions, effectively preserving trajectory continuity. To the best of our knowledge, this is the first application of Poisson flow models to sparse-view CT. Extensive experiments on synthetic and clinical datasets demonstrate that ResPF achieves superior reconstruction quality, faster inference, and stronger robustness compared to state-of-the-art iterative, learning-based, and diffusion models.
$ρ$-NeRF: Leveraging Attenuation Priors in Neural Radiance Field for 3D Computed Tomography Reconstruction
Dec 03, 2024
This paper introduces $\rho$-NeRF, a self-supervised approach that sets a new standard in novel view synthesis (NVS) and computed tomography (CT) reconstruction by modeling a continuous volumetric radiance field enriched with physics-based attenuation priors. The $\rho$-NeRF represents a three-dimensional (3D) volume through a fully-connected neural network that takes a single continuous four-dimensional (4D) coordinate, spatial location $(x, y, z)$ and an initialized attenuation value ($\rho$), and outputs the attenuation coefficient at that position. By querying these 4D coordinates along X-ray paths, the classic forward projection technique is applied to integrate attenuation data across the 3D space. By matching and refining pre-initialized attenuation values derived from traditional reconstruction algorithms like Feldkamp-Davis-Kress algorithm (FDK) or conjugate gradient least squares (CGLS), the enriched schema delivers superior fidelity in both projection synthesis and image recognition.
Physics-informed Score-based Diffusion Model for Limited-angle Reconstruction of Cardiac Computed Tomography
May 23, 2024



Cardiac computed tomography (CT) has emerged as a major imaging modality for the diagnosis and monitoring of cardiovascular diseases. High temporal resolution is essential to ensure diagnostic accuracy. Limited-angle data acquisition can reduce scan time and improve temporal resolution, but typically leads to severe image degradation and motivates for improved reconstruction techniques. In this paper, we propose a novel physics-informed score-based diffusion model (PSDM) for limited-angle reconstruction of cardiac CT. At the sampling time, we combine a data prior from a diffusion model and a model prior obtained via an iterative algorithm and Fourier fusion to further enhance the image quality. Specifically, our approach integrates the primal-dual hybrid gradient (PDHG) algorithm with score-based diffusion models, thereby enabling us to reconstruct high-quality cardiac CT images from limited-angle data. The numerical simulations and real data experiments confirm the effectiveness of our proposed approach.
LoMAE: Low-level Vision Masked Autoencoders for Low-dose CT Denoising
Oct 19, 2023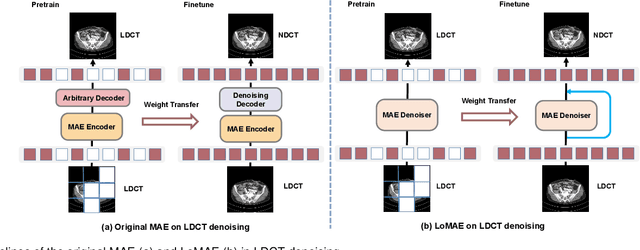
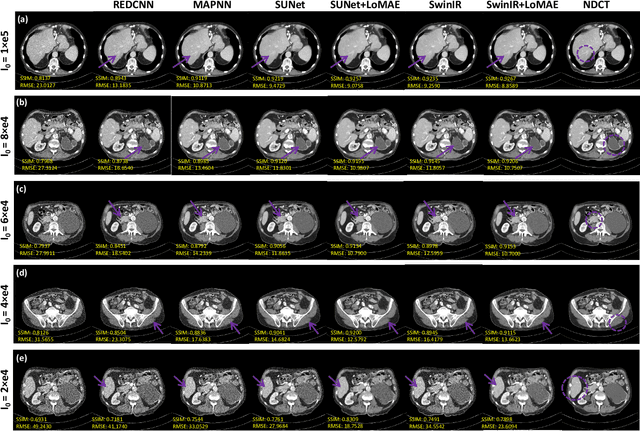
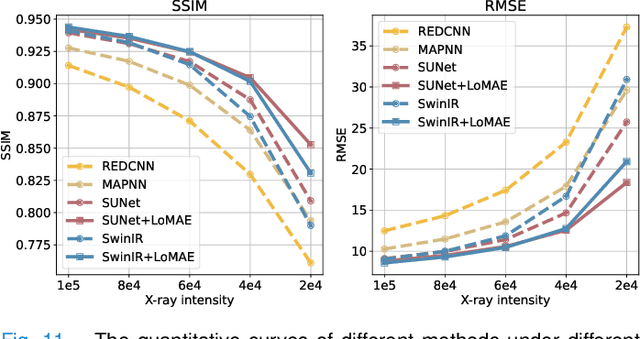
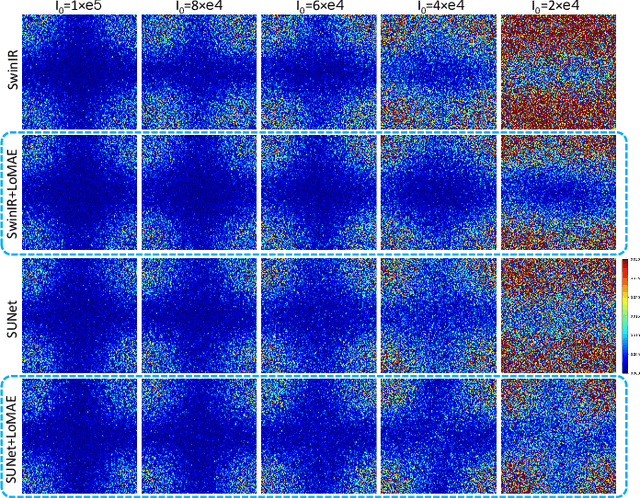
Low-dose computed tomography (LDCT) offers reduced X-ray radiation exposure but at the cost of compromised image quality, characterized by increased noise and artifacts. Recently, transformer models emerged as a promising avenue to enhance LDCT image quality. However, the success of such models relies on a large amount of paired noisy and clean images, which are often scarce in clinical settings. In the fields of computer vision and natural language processing, masked autoencoders (MAE) have been recognized as an effective label-free self-pretraining method for transformers, due to their exceptional feature representation ability. However, the original pretraining and fine-tuning design fails to work in low-level vision tasks like denoising. In response to this challenge, we redesign the classical encoder-decoder learning model and facilitate a simple yet effective low-level vision MAE, referred to as LoMAE, tailored to address the LDCT denoising problem. Moreover, we introduce an MAE-GradCAM method to shed light on the latent learning mechanisms of the MAE/LoMAE. Additionally, we explore the LoMAE's robustness and generability across a variety of noise levels. Experiments results show that the proposed LoMAE can enhance the transformer's denoising performance and greatly relieve the dependence on the ground truth clean data. It also demonstrates remarkable robustness and generalizability over a spectrum of noise levels.
Reduced Deep Convolutional Activation Features (R-DeCAF) in Histopathology Images to Improve the Classification Performance for Breast Cancer Diagnosis
Jan 05, 2023Breast cancer is the second most common cancer among women worldwide. Diagnosis of breast cancer by the pathologists is a time-consuming procedure and subjective. Computer aided diagnosis frameworks are utilized to relieve pathologist workload by classifying the data automatically, in which deep convolutional neural networks (CNNs) are effective solutions. The features extracted from activation layer of pre-trained CNNs are called deep convolutional activation features (DeCAF). In this paper, we have analyzed that all DeCAF features are not necessarily led to a higher accuracy in the classification task and dimension reduction plays an important role. Therefore, different dimension reduction methods are applied to achieve an effective combination of features by capturing the essence of DeCAF features. To this purpose, we have proposed reduced deep convolutional activation features (R-DeCAF). In this framework, pre-trained CNNs such as AlexNet, VGG-16 and VGG-19 are utilized in transfer learning mode as feature extractors. DeCAF features are extracted from the first fully connected layer of the mentioned CNNs and support vector machine has been used for binary classification. Among linear and nonlinear dimensionality reduction algorithms, linear approaches such as principal component analysis (PCA) represent a better combination among deep features and lead to a higher accuracy in the classification task using small number of features considering specific amount of cumulative explained variance (CEV) of features. The proposed method is validated using experimental BreakHis dataset. Comprehensive results show improvement in the classification accuracy up to 4.3% with less computational time. Best achieved accuracy is 91.13% for 400x data with feature vector size (FVS) of 23 and CEV equals to 0.15 using pre-trained AlexNet as feature extractor and PCA as feature reduction algorithm.