 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoMAE: Low-level Vision Masked Autoencoders for Low-dose CT Denoising
Paper and Code
Oct 19, 2023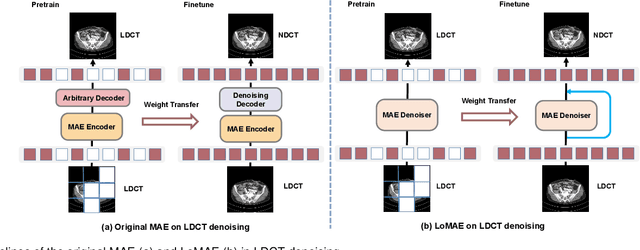
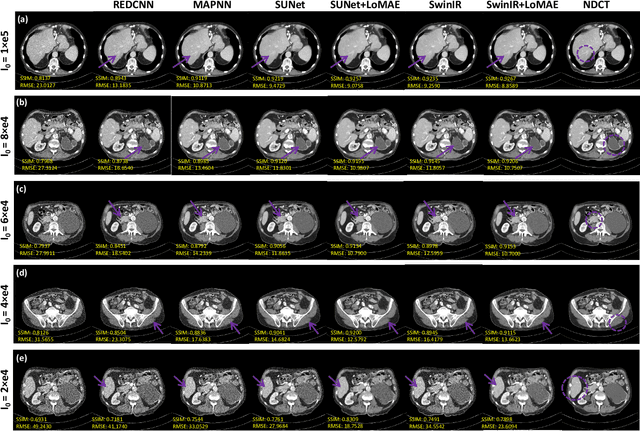
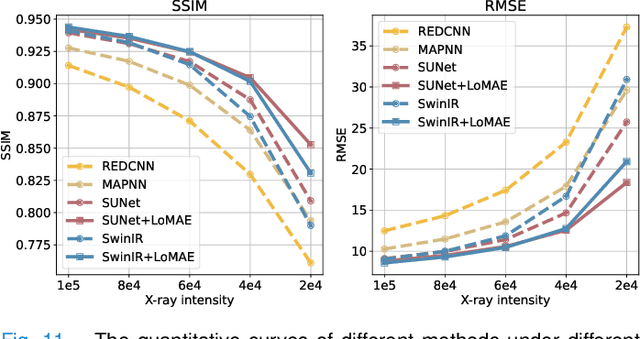
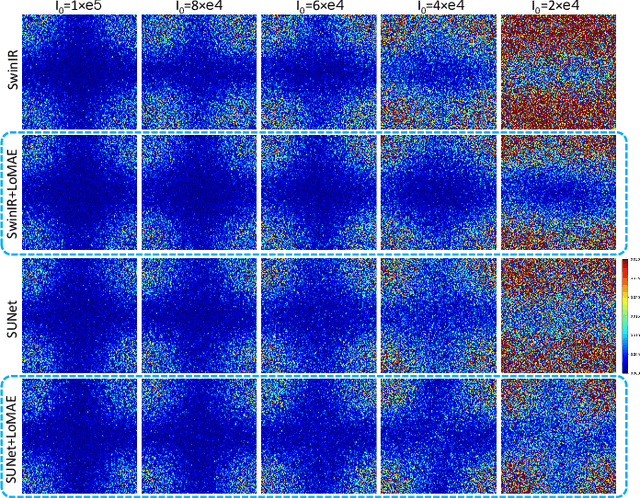
Low-dose computed tomography (LDCT) offers reduced X-ray radiation exposure but at the cost of compromised image quality, characterized by increased noise and artifacts. Recently, transformer models emerged as a promising avenue to enhance LDCT image quality. However, the success of such models relies on a large amount of paired noisy and clean images, which are often scarce in clinical settings. In the fields of computer vision and natural language processing, masked autoencoders (MAE) have been recognized as an effective label-free self-pretraining method for transformers, due to their exceptional feature representation ability. However, the original pretraining and fine-tuning design fails to work in low-level vision tasks like denoising. In response to this challenge, we redesign the classical encoder-decoder learning model and facilitate a simple yet effective low-level vision MAE, referred to as LoMAE, tailored to address the LDCT denoising problem. Moreover, we introduce an MAE-GradCAM method to shed light on the latent learning mechanisms of the MAE/LoMAE. Additionally, we explore the LoMAE's robustness and generability across a variety of noise levels. Experiments results show that the proposed LoMAE can enhance the transformer's denoising performance and greatly relieve the dependence on the ground truth clean data. It also demonstrates remarkable robustness and generalizability over a spectrum of noise levels.