 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$ρ$-NeRF: Leveraging Attenuation Priors in Neural Radiance Field for 3D Computed Tomography Reconstruction
Dec 03, 2024
This paper introduces $\rho$-NeRF, a self-supervised approach that sets a new standard in novel view synthesis (NVS) and computed tomography (CT) reconstruction by modeling a continuous volumetric radiance field enriched with physics-based attenuation priors. The $\rho$-NeRF represents a three-dimensional (3D) volume through a fully-connected neural network that takes a single continuous four-dimensional (4D) coordinate, spatial location $(x, y, z)$ and an initialized attenuation value ($\rho$), and outputs the attenuation coefficient at that position. By querying these 4D coordinates along X-ray paths, the classic forward projection technique is applied to integrate attenuation data across the 3D space. By matching and refining pre-initialized attenuation values derived from traditional reconstruction algorithms like Feldkamp-Davis-Kress algorithm (FDK) or conjugate gradient least squares (CGLS), the enriched schema delivers superior fidelity in both projection synthesis and image recognition.
Advanced Payment Security System:XGBoost, CatBoost and SMOTE Integrated
Jun 07, 2024With the rise of various online and mobile payment systems, transaction fraud has become a significant threat to financial security. This study explores the application of advanced machine learning models, specifically XGBoost and LightGBM, for developing a more accurate and robust Payment Security Protection Model.To enhance data reliability, we meticulously processed the data sources and used SMOTE (Synthetic Minority Over-sampling Technique) to address class imbalance and improve data representation. By selecting highly correlated features, we aimed to strengthen the training process and boost model performance.We conducted thorough performance evaluations of our proposed models, comparing them against traditional methods including Random Forest, Neural Network, and Logistic Regression. Key metrics such as Precision, Recall, and F1 Score were used to rigorously assess their effectiveness.Our detailed analyses and comparisons reveal that the combination of SMOTE with XGBoost and LightGBM offers a highly efficient and powerful mechanism for payment security protection. The results show that these models not only outperform traditional approaches but also hold significant promise for advancing the field of transaction fraud prevention.
Credit Card Fraud Detection Using Advanced Transformer Model
Jun 06, 2024



With the proliferation of various online and mobile payment systems, credit card fraud has emerged as a significant threat to financial security. This study focuses on innovative applications of the latest Transformer models for more robust and precise fraud detection. To ensure the reliability of the data, we meticulously processed the data sources, balancing the dataset to address the issue of data sparsity significantly. We also selected highly correlated vectors to strengthen the training process.To guarantee the reliability and practicality of the new Transformer model, we conducted performance comparisons with several widely adopted models, including Support Vector Machine (SVM), Random Forest, Neural Network, and Logistic Regression. We rigorously compared these models using metrics such as Precision, Recall, and F1 Score. Through these detailed analyses and comparisons, we present to the readers a highly efficient and powerful anti-fraud mechanism with promising prospects. The results demonstrate that the Transformer model not only excels in traditional applications but also shows great potential in niche areas like fraud detection, offering a substantial advancement in the field.
Physics-informed Score-based Diffusion Model for Limited-angle Reconstruction of Cardiac Computed Tomography
May 23, 2024



Cardiac computed tomography (CT) has emerged as a major imaging modality for the diagnosis and monitoring of cardiovascular diseases. High temporal resolution is essential to ensure diagnostic accuracy. Limited-angle data acquisition can reduce scan time and improve temporal resolution, but typically leads to severe image degradation and motivates for improved reconstruction techniques. In this paper, we propose a novel physics-informed score-based diffusion model (PSDM) for limited-angle reconstruction of cardiac CT. At the sampling time, we combine a data prior from a diffusion model and a model prior obtained via an iterative algorithm and Fourier fusion to further enhance the image quality. Specifically, our approach integrates the primal-dual hybrid gradient (PDHG) algorithm with score-based diffusion models, thereby enabling us to reconstruct high-quality cardiac CT images from limited-angle data. The numerical simulations and real data experiments confirm the effectiveness of our proposed approach.
LoMAE: Low-level Vision Masked Autoencoders for Low-dose CT Denoising
Oct 19, 2023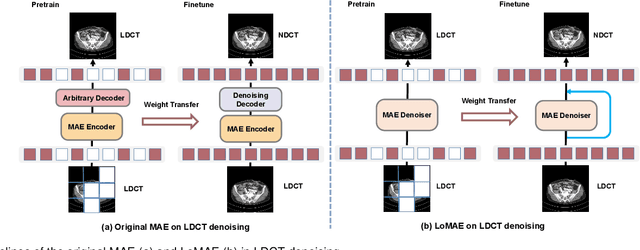
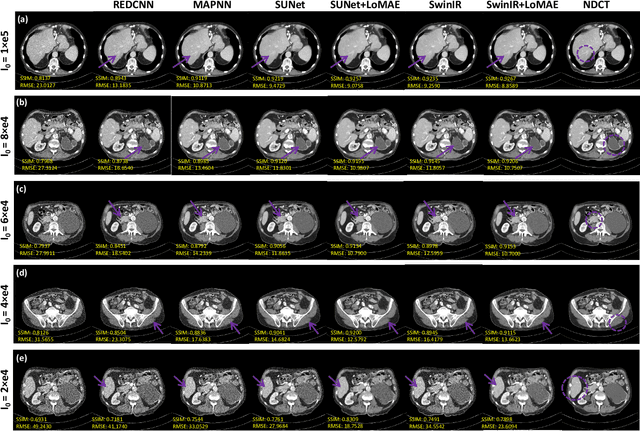
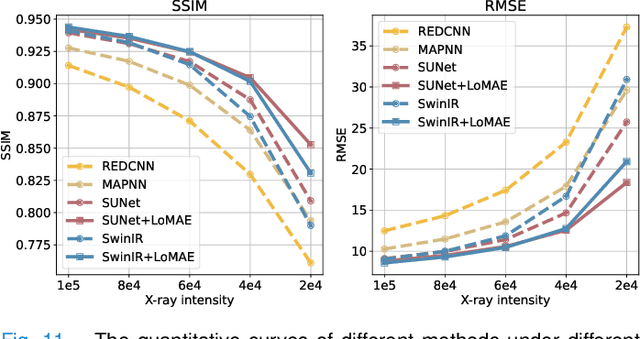
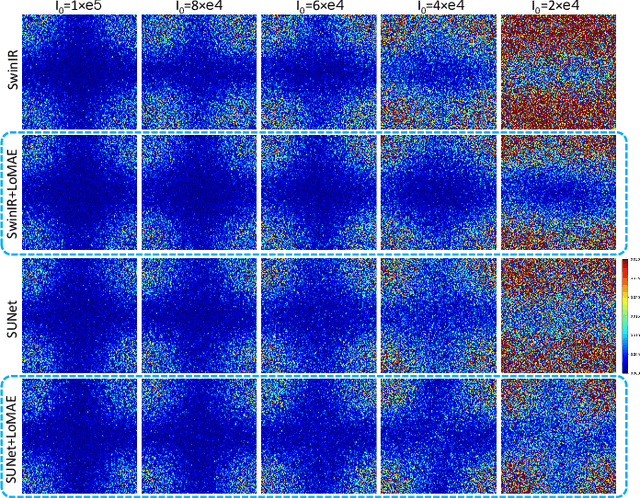
Low-dose computed tomography (LDCT) offers reduced X-ray radiation exposure but at the cost of compromised image quality, characterized by increased noise and artifacts. Recently, transformer models emerged as a promising avenue to enhance LDCT image quality. However, the success of such models relies on a large amount of paired noisy and clean images, which are often scarce in clinical settings. In the fields of computer vision and natural language processing, masked autoencoders (MAE) have been recognized as an effective label-free self-pretraining method for transformers, due to their exceptional feature representation ability. However, the original pretraining and fine-tuning design fails to work in low-level vision tasks like denoising. In response to this challenge, we redesign the classical encoder-decoder learning model and facilitate a simple yet effective low-level vision MAE, referred to as LoMAE, tailored to address the LDCT denoising problem. Moreover, we introduce an MAE-GradCAM method to shed light on the latent learning mechanisms of the MAE/LoMAE. Additionally, we explore the LoMAE's robustness and generability across a variety of noise levels. Experiments results show that the proposed LoMAE can enhance the transformer's denoising performance and greatly relieve the dependence on the ground truth clean data. It also demonstrates remarkable robustness and generalizability over a spectrum of noise levels.
Masked Autoencoders for Low dose CT denoising
Oct 10, 2022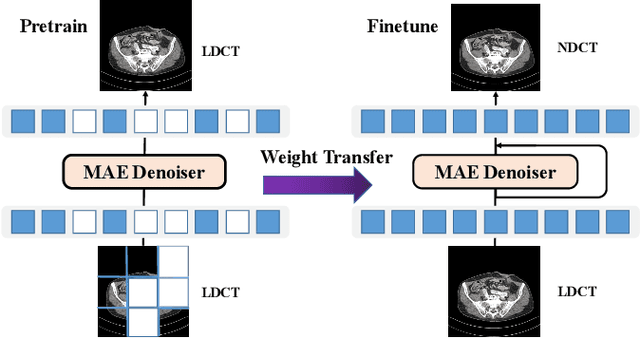
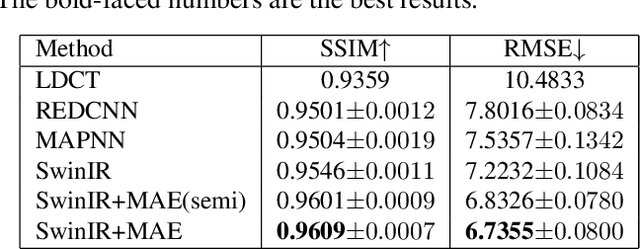
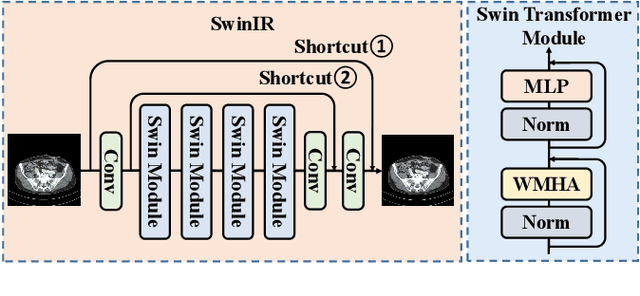
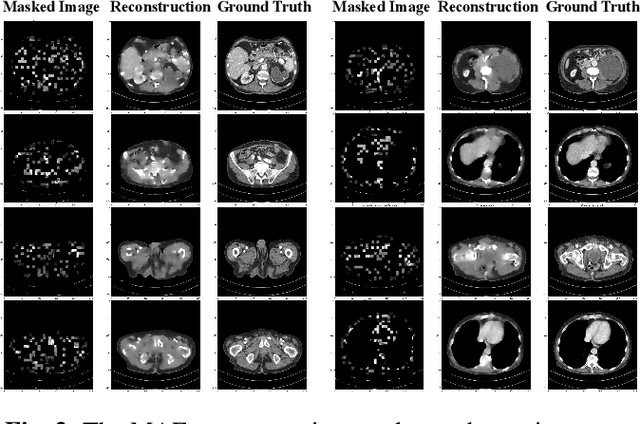
Low-dose computed tomography (LDCT) reduces the X-ray radiation but compromises image quality with more noises and artifacts. A plethora of transformer models have been developed recently to improve LDCT image quality. However, the success of a transformer model relies on a large amount of paired noisy and clean data, which is often unavailable in clinical applications. In computer vision and natural language processing fields, masked autoencoders (MAE) have been proposed as an effective label-free self-pretraining method for transformers, due to its excellent feature representation ability. Here, we redesign the classical encoder-decoder learning model to match the denoising task and apply it to LDCT denoising problem. The MAE can leverage the unlabeled data and facilitate structural preservation for the LDCT denoising model when ground truth data are missing. Experiments on the Mayo dataset validate that the MAE can boost the transformer's denoising performance and relieve the dependence on the ground truth data.
SQ-Swin: a Pretrained Siamese Quadratic Swin Transformer for Lettuce Browning Prediction
Sep 16, 2022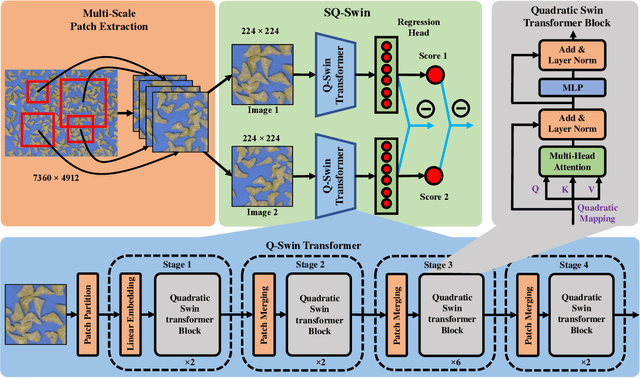

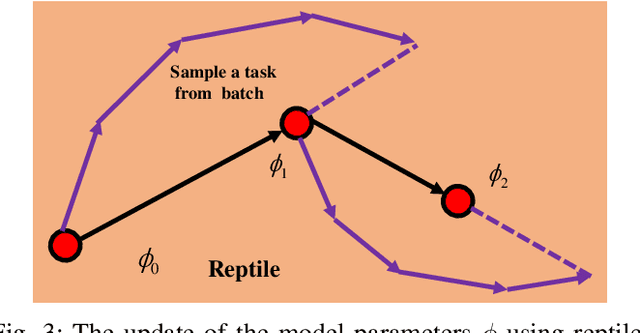

Packaged fresh-cut lettuce is widely consumed as a major component of vegetable salad owing to its high nutrition, freshness, and convenience. However, enzymatic browning discoloration on lettuce cut edges significantly reduces product quality and shelf life. While there are many research and breeding efforts underway to minimize browning, the progress is hindered by the lack of a rapid and reliable methodology to evaluate browning. Current methods to identify and quantify browning are either too subjective, labor intensive, or inaccurate. In this paper, we report a deep learning model for lettuce browning prediction. To the best of our knowledge, it is the first-of-its-kind on deep learning for lettuce browning prediction using a pretrained Siamese Quadratic Swin (SQ-Swin) transformer with several highlights. First, our model includes quadratic features in the transformer model which is more powerful to incorporate real-world representations than the linear transformer. Second, a multi-scale training strategy is proposed to augment the data and explore more of the inherent self-similarity of the lettuce images. Third, the proposed model uses a siamese architecture which learns the inter-relations among the limited training samples. Fourth, the model is pretrained on the ImageNet and then trained with the reptile meta-learning algorithm to learn higher-order gradients than a regular one. Experiment results on the fresh-cut lettuce datasets show that the proposed SQ-Swin outperforms the traditional methods and other deep learning-based backbones.