 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation of Arbitrary Level Contrast Dose in MRI Using an Iterative Global Transformer Model
Jul 22, 2023



Deep learning (DL) based contrast dose reduction and elimination in MRI imaging is gaining traction, given the detrimental effects of Gadolinium-based Contrast Agents (GBCAs). These DL algorithms are however limited by the availability of high quality low dose datasets. Additionally, different types of GBCAs and pathologies require different dose levels for the DL algorithms to work reliably. In this work, we formulate a novel transformer (Gformer) based iterative modelling approach for the synthesis of images with arbitrary contrast enhancement that corresponds to different dose levels. The proposed Gformer incorporates a sub-sampling based attention mechanism and a rotational shift module that captures the various contrast related features. Quantitative evaluation indicates that the proposed model performs better than other state-of-the-art methods. We further perform quantitative evaluation on downstream tasks such as dose reduction and tumor segmentation to demonstrate the clinical utility.
One Model to Synthesize Them All: Multi-contrast Multi-scale Transformer for Missing Data Imputation
Apr 28, 2022


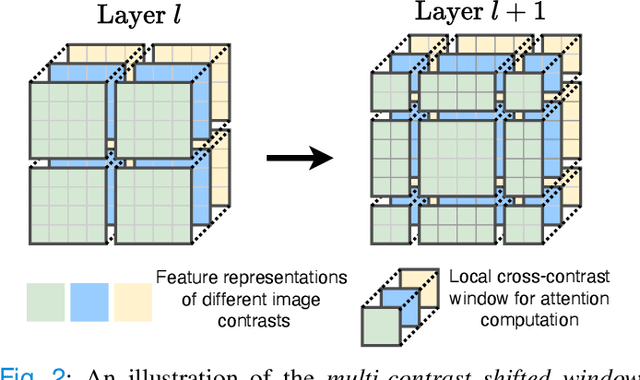
Multi-contrast magnetic resonance imaging (MRI) is widely used in clinical practice as each contrast provides complementary information. However, the availability of each contrast may vary amongst patients in reality. This poses challenges to both radiologists and automated image analysis algorithms. A general approach for tackling this problem is missing data imputation, which aims to synthesize the missing contrasts from existing ones. While several convolutional neural network (CNN) based algorithms have been proposed, they suffer from the fundamental limitations of CNN models, such as requirement for fixed numbers of input and output channels, inability to capture long-range dependencies, and lack of interpretability. In this paper, we formulate missing data imputation as a sequence-to-sequence learning problem and propose a multi-contrast multi-scale Transformer (MMT), which can take any subset of input contrasts and synthesize those that are missing. MMT consists of a multi-scale Transformer encoder that builds hierarchical representations of inputs combined with a multi-scale Transformer decoder that generates the outputs in a coarse-to-fine fashion. Thanks to the proposed multi-contrast Swin Transformer blocks, it can efficiently capture intra- and inter-contrast dependencies for accurate image synthesis. Moreover, MMT is inherently interpretable. It allows us to understand the importance of each input contrast in different regions by analyzing the in-built attention maps of Transformer blocks in the decoder. Extensive experiments on two large-scale multi-contrast MRI datasets demonstrate that MMT outperforms the state-of-the-art methods quantitatively and qualitatively.