 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTformer: Convolution-free Token2Token Dilated Vision Transformer for Low-dose CT Denoising
Paper and Code
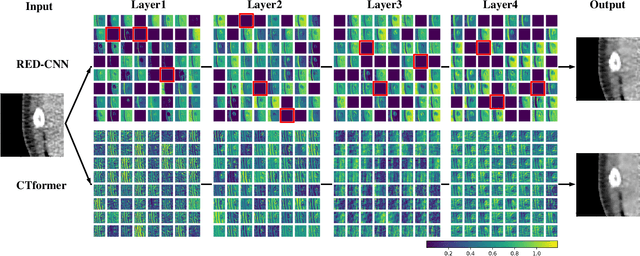

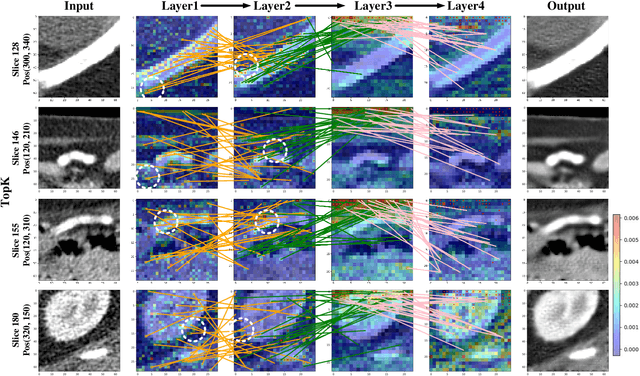
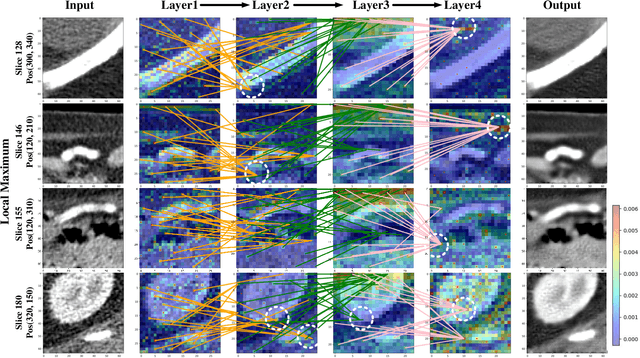
Low-dose computed tomography (LDCT) denoising is an important problem in CT research. Compared to the normal dose CT (NDCT), LDCT images are subjected to severe noise and artifacts. Recently in many studies, vision transformers have shown superior feature representation ability over convolutional neural networks (CNNs). However, unlike CNNs, the potential of vision transformers in LDCT denoising was little explored so far. To fill this gap, we propose a Convolution-free Token2Token Dilated Vision Transformer for low-dose CT denoising. The CTformer uses a more powerful token rearrangement to encompass local contextual information and thus avoids convolution. It also dilates and shifts feature maps to capture longer-range interaction. We interpret the CTformer by statically inspecting patterns of its internal attention maps and dynamically tracing the hierarchical attention flow with an explanatory graph. Furthermore, an overlapped inference mechanism is introduced to effectively eliminate the boundary artifacts that are common for encoder-decoder-based denoising models. Experimental results on Mayo LDCT dataset suggest that the CTformer outperforms the state-of-the-art denoising methods with a low computation overhead.