 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Semantics and Geometry: A Decoupled LVLM-SAM Framework for Reasoning Segmentation in Remote Sensing
Dec 22, 2025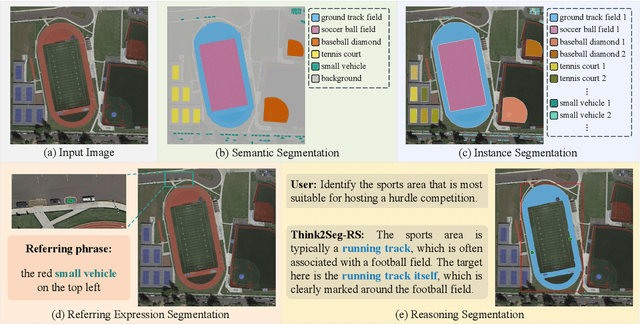
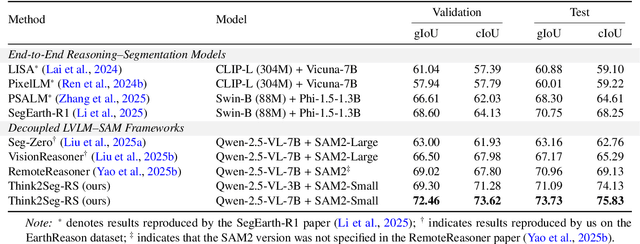
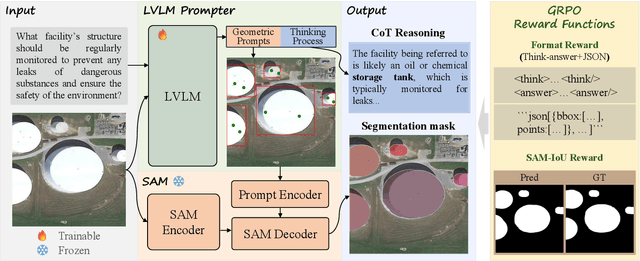
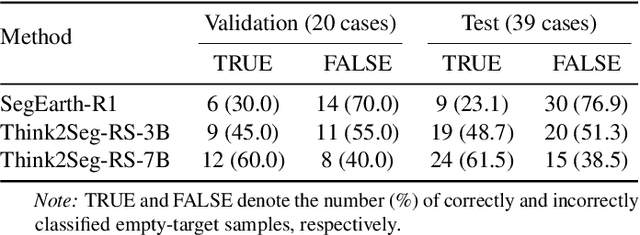
Large Vision-Language Models (LVLMs) hold great promise for advancing remote sensing (RS) analysis, yet existing reasoning segmentation frameworks couple linguistic reasoning and pixel prediction through end-to-end supervised fine-tuning, leading to weak geometric grounding and limited generalization across tasks. To address this, we developed Think2Seg-RS, a decoupled framework that trains an LVLM prompter to control a frozen Segment Anything Model (SAM) via structured geometric prompts. Through a mask-only reinforcement learning objective, the LVLM learns to translate abstract semantic reasoning into spatially grounded actions, achieving state-of-the-art performance on the EarthReason dataset. Remarkably, the learned prompting policy generalizes zero-shot to multiple referring segmentation benchmarks, exposing a distinct divide between semantic-level and instance-level grounding. We further found that compact segmenters outperform larger ones under semantic-level supervision, and that negative prompts are ineffective in heterogeneous aerial backgrounds. Together, these findings establish semantic-level reasoning segmentation as a new paradigm for geospatial understanding, opening the way toward unified, interpretable LVLM-driven Earth observation. Our code and model are available at https://github.com/Ricardo-XZ/Think2Seg-RS.
RSTeller: Scaling Up Visual Language Modeling in Remote Sensing with Rich Linguistic Semantics from Openly Available Data and Large Language Models
Aug 27, 2024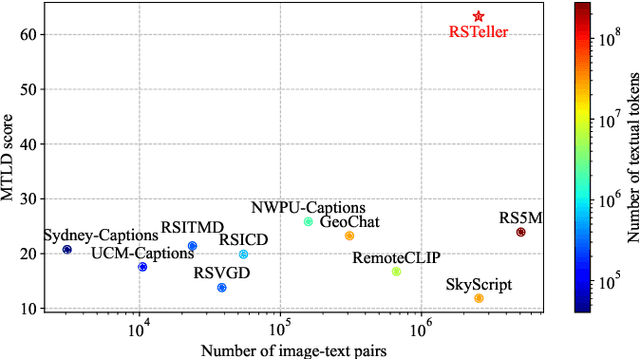

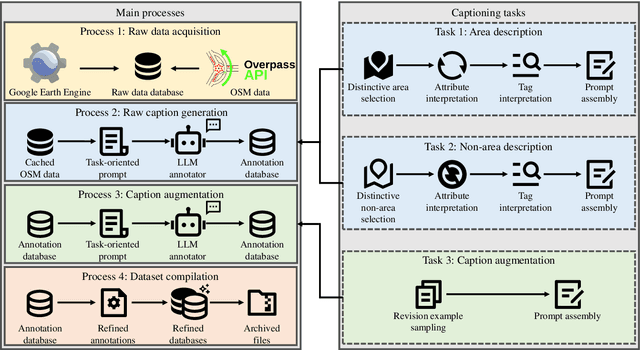

Abundant, well-annotated multimodal data in remote sensing are pivotal for aligning complex visual remote sensing (RS) scenes with human language, enabling the development of specialized vision language models across diverse RS interpretation tasks. However, annotating RS images with rich linguistic semantics at scale demands expertise in RS and substantial human labor, making it costly and often impractical. In this study, we propose a workflow that leverages large language models (LLMs) to generate multimodal datasets with semantically rich captions at scale from plain OpenStreetMap (OSM) data for images sourced from the Google Earth Engine (GEE) platform. This approach facilitates the generation of paired remote sensing data and can be readily scaled up using openly available data. Within this framework, we present RSTeller, a multimodal dataset comprising over 1 million RS images, each accompanied by multiple descriptive captions. Extensive experiments demonstrate that RSTeller enhances the performance of multiple existing vision language models for RS scene understanding through continual pre-training. Our methodology significantly reduces the manual effort and expertise needed for annotating remote sensing imagery while democratizing access to high-quality annotated data. This advancement fosters progress in visual language modeling and encourages broader participation in remote sensing research and applications. The RSTeller dataset is available at https://github.com/SlytherinGe/RSTeller.
High-Resolution Swin Transformer for Automatic Medical Image Segmentation
Jul 23, 2022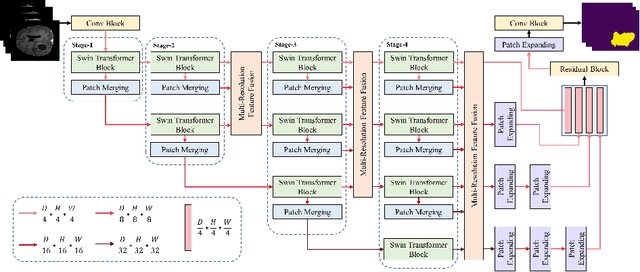

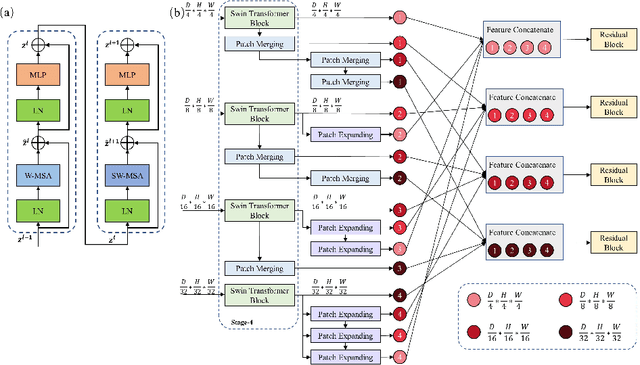

The Resolution of feature maps is critical for medical image segmentation. Most of the existing Transformer-based networks for medical image segmentation are U-Net-like architecture that contains an encoder that utilizes a sequence of Transformer blocks to convert the input medical image from high-resolution representation into low-resolution feature maps and a decoder that gradually recovers the high-resolution representation from low-resolution feature maps. Unlike previous studies, in this paper, we utilize the network design style from the High-Resolution Network (HRNet), replace the convolutional layers with Transformer blocks, and continuously exchange information from the different resolution feature maps that are generated by Transformer blocks. The newly Transformer-based network presented in this paper is denoted as High-Resolution Swin Transformer Network (HRSTNet). Extensive experiments illustrate that HRSTNet can achieve comparable performance with the state-of-the-art Transformer-based U-Net-like architecture on Brain Tumor Segmentation(BraTS) 2021 and the liver dataset from Medical Segmentation Decathlon. The code of HRSTNet will be publicly available at https://github.com/auroua/HRSTNet.
Self-supervised Representation Learning for Evolutionary Neural Architecture Search
Oct 31, 2020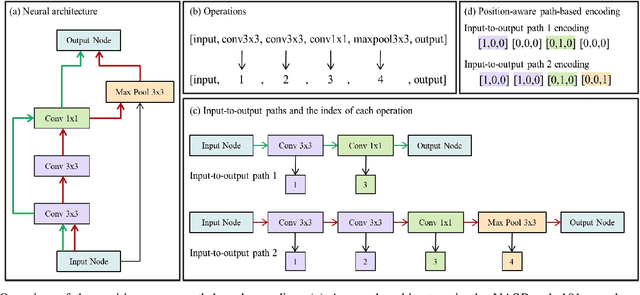
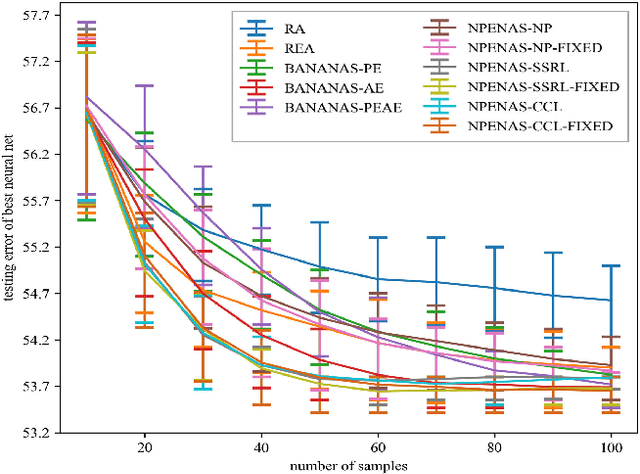
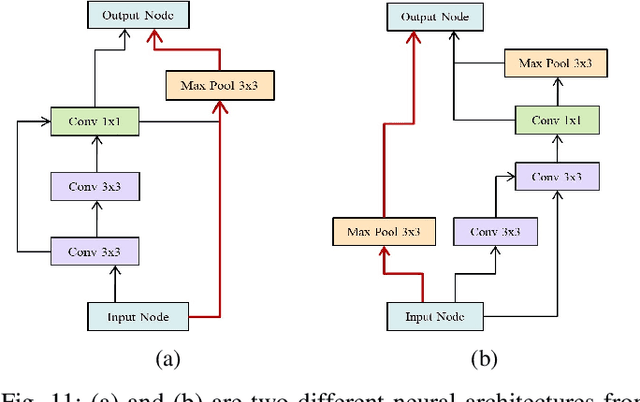
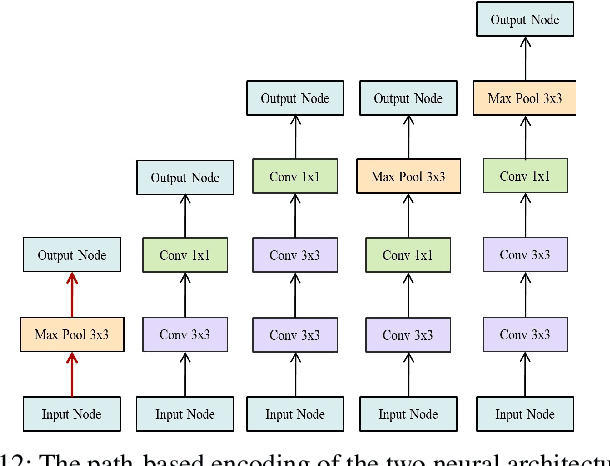
Recently proposed neural architecture search (NAS) algorithms adopt neural predictors to accelerate the architecture search. The capability of neural predictors to accurately predict the performance metrics of neural architecture is critical to NAS, and the acquisition of training datasets for neural predictors is time-consuming. How to obtain a neural predictor with high prediction accuracy using a small amount of training data is a central problem to neural predictor-based NAS. Here, we firstly design a new architecture encoding scheme that overcomes the drawbacks of existing vector-based architecture encoding schemes to calculate the graph edit distance of neural architectures. To enhance the predictive performance of neural predictors, we devise two self-supervised learning methods from different perspectives to pre-train the architecture embedding part of neural predictors to generate a meaningful representation of neural architectures. The first one is to train a carefully designed two branch graph neural network model to predict the graph edit distance of two input neural architectures. The second method is inspired by the prevalently contrastive learning, and we present a new contrastive learning algorithm that utilizes a central feature vector as a proxy to contrast positive pairs against negative pairs. Experimental results illustrate that the pre-trained neural predictors can achieve comparable or superior performance compared with their supervised counterparts with several times less training samples. We achieve state-of-the-art performance on the NASBench-101 and NASBench201 benchmarks when integrating the pre-trained neural predictors with an evolutionary NAS algorithm.
Low-dimensional Manifold Constrained Disentanglement Network for Metal Artifact Reduction
Jul 08, 2020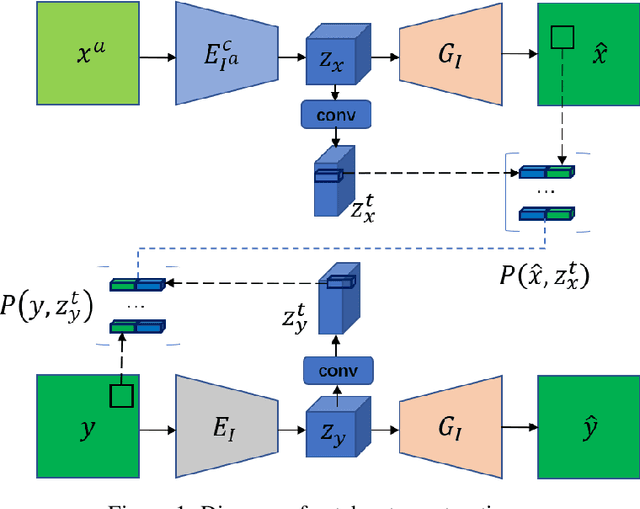
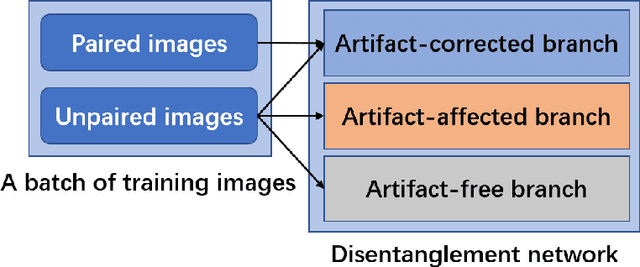
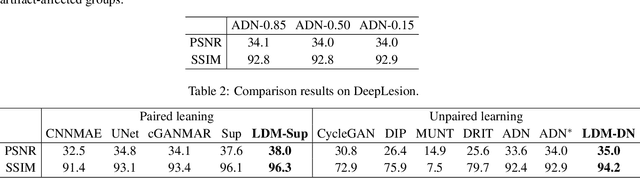
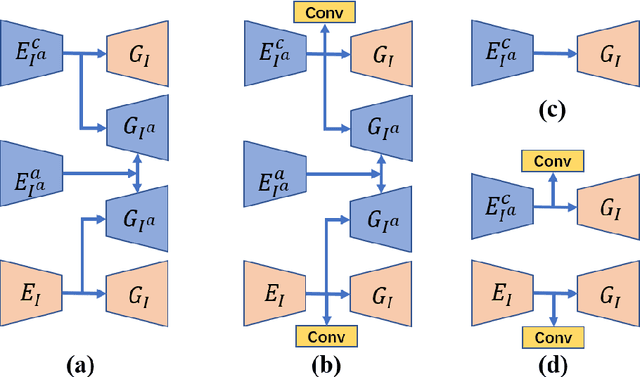
Deep neural network based methods have achieved promising results for CT metal artifact reduction (MAR), most of which use many synthesized paired images for training. As synthesized metal artifacts in CT images may not accurately reflect the clinical counterparts, an artifact disentanglement network (ADN) was proposed with unpaired clinical images directly, producing promising results on clinical datasets. However, without sufficient supervision, it is difficult for ADN to recover structural details of artifact-affected CT images based on adversarial losses only. To overcome these problems, here we propose a low-dimensional manifold (LDM) constrained disentanglement network (DN), leveraging the image characteristics that the patch manifold is generally low-dimensional. Specifically, we design an LDM-DN learning algorithm to empower the disentanglement network through optimizing the synergistic network loss functions while constraining the recovered images to be on a low-dimensional patch manifold. Moreover, learning from both paired and unpaired data, an efficient hybrid optimization scheme is proposed to further improve the MAR performance on clinical datasets. Extensive experiments demonstrate that the proposed LDM-DN approach can consistently improve the MAR performance in paired and/or unpaired learning settings, outperforming competing methods on synthesized and clinical datasets.
NPENAS: Neural Predictor Guided Evolution for Neural Architecture Search
Mar 28, 2020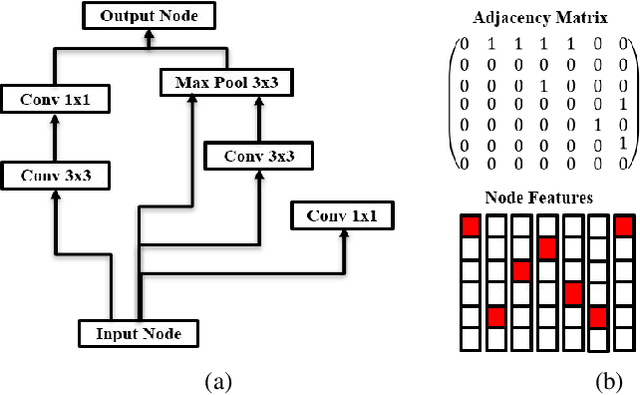
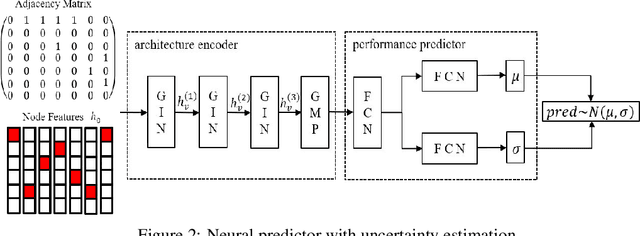
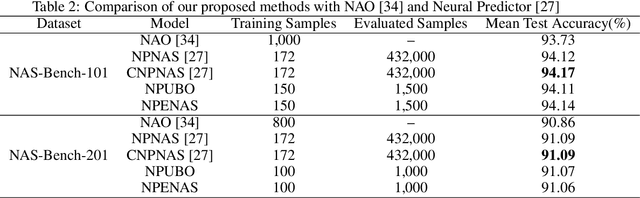
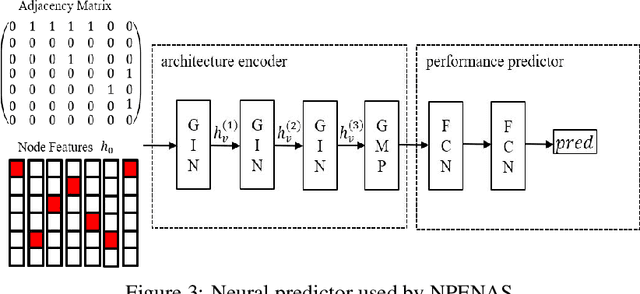
Neural architecture search (NAS) is a promising method for automatically finding excellent architectures.Commonly used search strategies such as evolutionary algorithm, Bayesian optimization, and Predictor method employs a predictor to rank sampled architectures. In this paper, we propose two predictor based algorithms NPUBO and NPENAS for neural architecture search. Firstly we propose NPUBO which takes a neural predictor with uncertainty estimation as surrogate model for Bayesian optimization. Secondly we propose a simple and effective predictor guided evolution algorithm(NPENAS), which uses neural predictor to guide evolutionary algorithm to perform selection and mutation. Finally we analyse the architecture sampling pipeline and find that mostly used random sampling pipeline tends to generate architectures in a subspace of the real underlying search space. Our proposed methods can find architecture achieves high test accuracy which is comparable with recently proposed methods on NAS-Bench-101 and NAS-Bench-201 dataset using less training and evaluated samples. Code will be publicly available after finish all the experiments.
GATCluster: Self-Supervised Gaussian-Attention Network for Image Clustering
Feb 27, 2020
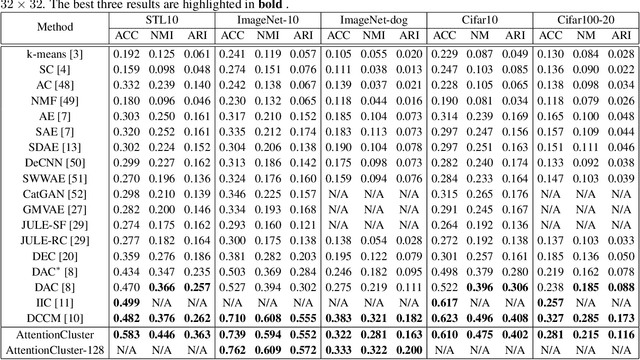
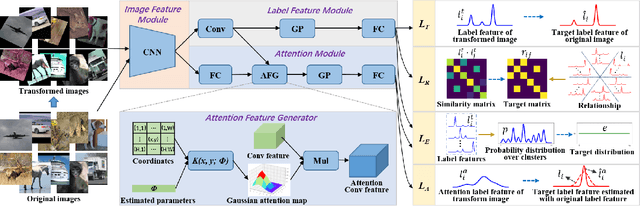
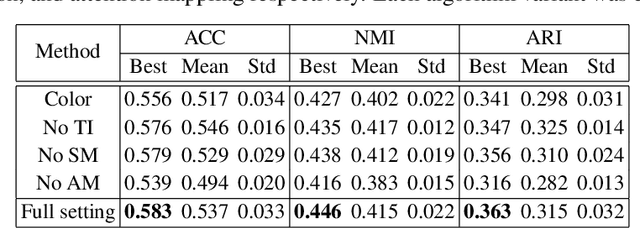
Deep clustering has achieved state-of-the-art results via joint representation learning and clustering, but still has an inferior performance for the real scene images, e.g., those in ImageNet. With such images, deep clustering methods face several challenges, including extracting discriminative features, avoiding trivial solutions, capturing semantic information, and performing on large-size image datasets. To address these problems, here we propose a self-supervised attention network for image clustering (AttentionCluster). Rather than extracting intermediate features first and then performing the traditional clustering algorithm, AttentionCluster directly outputs semantic cluster labels that are more discriminative than intermediate features and does not need further post-processing. To train the AttentionCluster in a completely unsupervised manner, we design four learning tasks with the constraints of transformation invariance, separability maximization, entropy analysis, and attention mapping. Specifically, the transformation invariance and separability maximization tasks learn the relationships between sample pairs. The entropy analysis task aims to avoid trivial solutions. To capture the object-oriented semantics, we design a self-supervised attention mechanism that includes a parameterized attention module and a soft-attention loss. All the guiding signals for clustering are self-generated during the training process. Moreover, we develop a two-step learning algorithm that is training-friendly and memory-efficient for processing large-size images. Extensive experiments demonstrate the superiority of our proposed method in comparison with the state-of-the-art image clustering benchmarks.
AFO-TAD: Anchor-free One-Stage Detector for Temporal Action Detection
Oct 18, 2019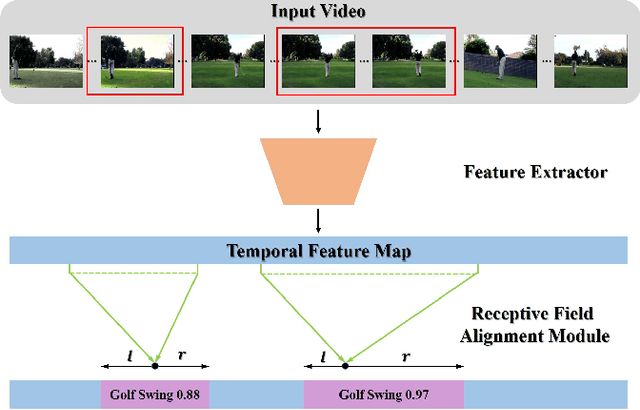
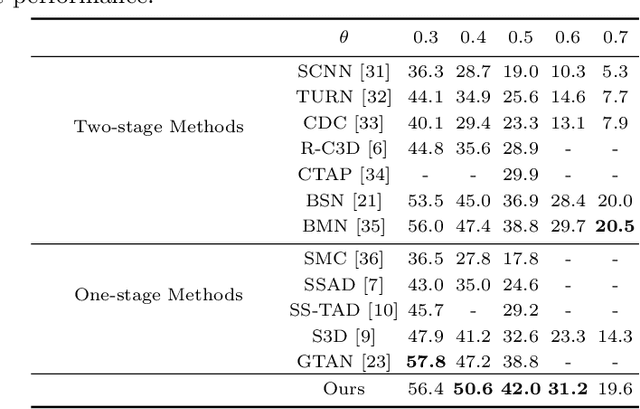
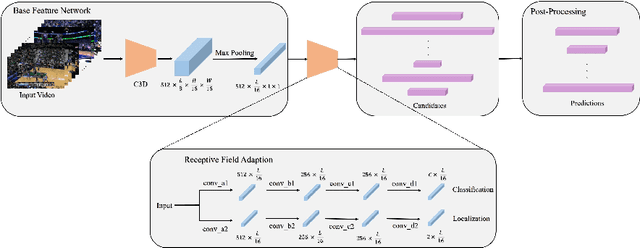
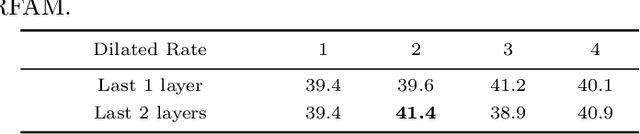
Temporal action detection is a fundamental yet challenging task in video understanding. Many of the state-of-the-art methods predict the boundaries of action instances based on predetermined anchors akin to the two-dimensional object detection detectors. However, it is hard to detect all the action instances with predetermined temporal scales because the durations of instances in untrimmed videos can vary from few seconds to several minutes. In this paper, we propose a novel action detection architecture named anchor-free one-stage temporal action detector (AFO-TAD). AFO-TAD achieves better performance for detecting action instances with arbitrary lengths and high temporal resolution, which can be attributed to two aspects. First, we design a receptive field adaption module which dynamically adjusts the receptive field for precise action detection. Second, AFO-TAD directly predicts the categories and boundaries at every temporal locations without predetermined anchors. Extensive experiments show that AFO-TAD improves the state-of-the-art performance on THUMOS'14.
DASNet: Reducing Pixel-level Annotations for Instance and Semantic Segmentation
Sep 17, 2018



Pixel-level annotation demands expensive human efforts and limits the performance of deep networks that usually benefits from more such training data. In this work we aim to achieve high quality instance and semantic segmentation results over a small set of pixel-level mask annotations and a large set of box annotations. The basic idea is exploring detection models to simplify the pixel-level supervised learning task and thus reduce the required amount of mask annotations. Our architecture, named DASNet, consists of three modules: detection, attention, and segmentation. The detection module detects all classes of objects, the attention module generates multi-scale class-specific features, and the segmentation module recovers the binary masks. Our method demonstrates substantially improved performance compared to existing semi-supervised approaches on PASCAL VOC 2012 dataset.