 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Swin Transformer for Automatic Medical Image Segmentation
Jul 23, 2022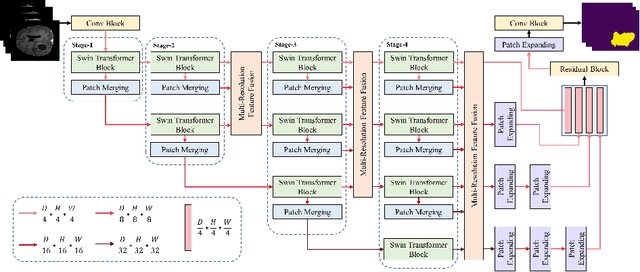

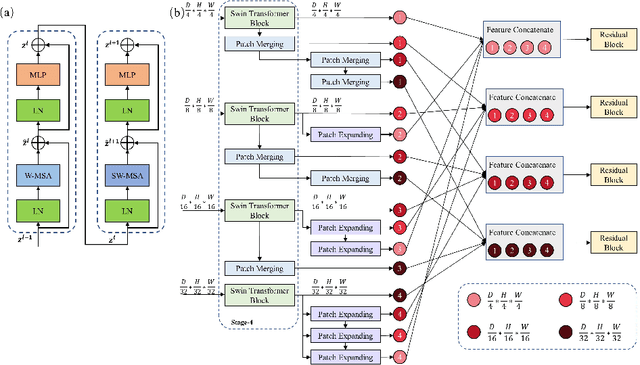

The Resolution of feature maps is critical for medical image segmentation. Most of the existing Transformer-based networks for medical image segmentation are U-Net-like architecture that contains an encoder that utilizes a sequence of Transformer blocks to convert the input medical image from high-resolution representation into low-resolution feature maps and a decoder that gradually recovers the high-resolution representation from low-resolution feature maps. Unlike previous studies, in this paper, we utilize the network design style from the High-Resolution Network (HRNet), replace the convolutional layers with Transformer blocks, and continuously exchange information from the different resolution feature maps that are generated by Transformer blocks. The newly Transformer-based network presented in this paper is denoted as High-Resolution Swin Transformer Network (HRSTNet). Extensive experiments illustrate that HRSTNet can achieve comparable performance with the state-of-the-art Transformer-based U-Net-like architecture on Brain Tumor Segmentation(BraTS) 2021 and the liver dataset from Medical Segmentation Decathlon. The code of HRSTNet will be publicly available at https://github.com/auroua/HRSTNet.
Self-supervised Representation Learning for Evolutionary Neural Architecture Search
Oct 31, 2020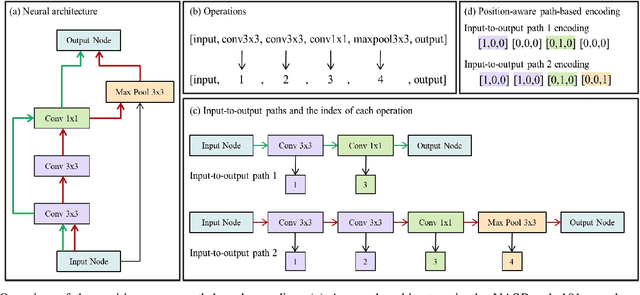
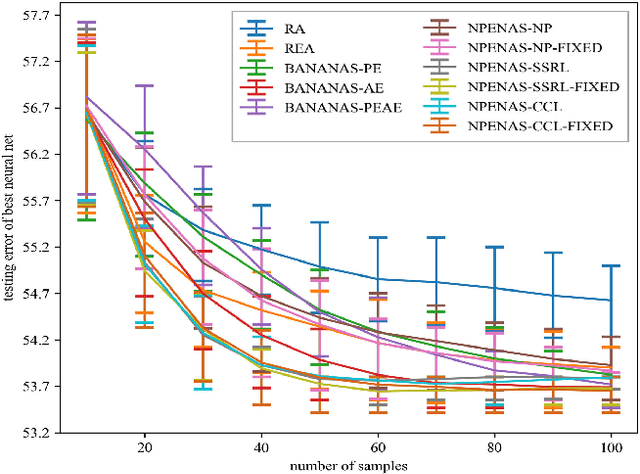
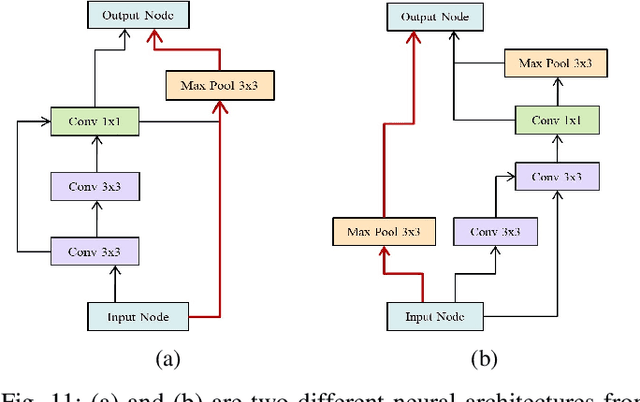
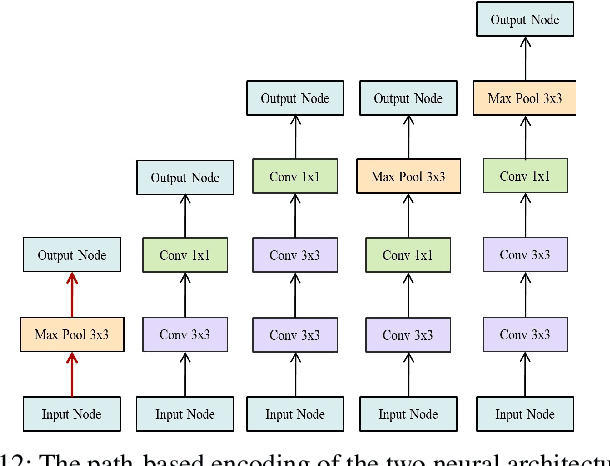
Recently proposed neural architecture search (NAS) algorithms adopt neural predictors to accelerate the architecture search. The capability of neural predictors to accurately predict the performance metrics of neural architecture is critical to NAS, and the acquisition of training datasets for neural predictors is time-consuming. How to obtain a neural predictor with high prediction accuracy using a small amount of training data is a central problem to neural predictor-based NAS. Here, we firstly design a new architecture encoding scheme that overcomes the drawbacks of existing vector-based architecture encoding schemes to calculate the graph edit distance of neural architectures. To enhance the predictive performance of neural predictors, we devise two self-supervised learning methods from different perspectives to pre-train the architecture embedding part of neural predictors to generate a meaningful representation of neural architectures. The first one is to train a carefully designed two branch graph neural network model to predict the graph edit distance of two input neural architectures. The second method is inspired by the prevalently contrastive learning, and we present a new contrastive learning algorithm that utilizes a central feature vector as a proxy to contrast positive pairs against negative pairs. Experimental results illustrate that the pre-trained neural predictors can achieve comparable or superior performance compared with their supervised counterparts with several times less training samples. We achieve state-of-the-art performance on the NASBench-101 and NASBench201 benchmarks when integrating the pre-trained neural predictors with an evolutionary NAS algorithm.