 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangMamba: A Language-driven Mamba Framework for Low-dose CT Denoising with Vision-language Models
Jul 08, 2025Low-dose computed tomography (LDCT) reduces radiation exposure but often degrades image quality, potentially compromising diagnostic accuracy. Existing deep learning-based denoising methods focus primarily on pixel-level mappings, overlooking the potential benefits of high-level semantic guidance. Recent advances in vision-language models (VLMs) suggest that language can serve as a powerful tool for capturing structured semantic information, offering new opportunities to improve LDCT reconstruction. In this paper, we introduce LangMamba, a Language-driven Mamba framework for LDCT denoising that leverages VLM-derived representations to enhance supervision from normal-dose CT (NDCT). LangMamba follows a two-stage learning strategy. First, we pre-train a Language-guided AutoEncoder (LangAE) that leverages frozen VLMs to map NDCT images into a semantic space enriched with anatomical information. Second, we synergize LangAE with two key components to guide LDCT denoising: Semantic-Enhanced Efficient Denoiser (SEED), which enhances NDCT-relevant local semantic while capturing global features with efficient Mamba mechanism, and Language-engaged Dual-space Alignment (LangDA) Loss, which ensures that denoised images align with NDCT in both perceptual and semantic spaces. Extensive experiments on two public datasets demonstrate that LangMamba outperforms conventional state-of-the-art methods, significantly improving detail preservation and visual fidelity. Remarkably, LangAE exhibits strong generalizability to unseen datasets, thereby reducing training costs. Furthermore, LangDA loss improves explainability by integrating language-guided insights into image reconstruction and offers a plug-and-play fashion. Our findings shed new light on the potential of language as a supervisory signal to advance LDCT denoising. The code is publicly available on https://github.com/hao1635/LangMamba.
Information-Maximized Soft Variable Discretization for Self-Supervised Image Representation Learning
Jan 07, 2025



Self-supervised learning (SSL) has emerged as a crucial technique in image processing, encoding, and understanding, especially for developing today's vision foundation models that utilize large-scale datasets without annotations to enhance various downstream tasks. This study introduces a novel SSL approach, Information-Maximized Soft Variable Discretization (IMSVD), for image representation learning. Specifically, IMSVD softly discretizes each variable in the latent space, enabling the estimation of their probability distributions over training batches and allowing the learning process to be directly guided by information measures. Motivated by the MultiView assumption, we propose an information-theoretic objective function to learn transform-invariant, non-travail, and redundancy-minimized representation features. We then derive a joint-cross entropy loss function for self-supervised image representation learning, which theoretically enjoys superiority over the existing methods in reducing feature redundancy. Notably, our non-contrastive IMSVD method statistically performs contrastive learning. Extensive experimental results demonstrate the effectiveness of IMSVD on various downstream tasks in terms of both accuracy and efficiency. Thanks to our variable discretization, the embedding features optimized by IMSVD offer unique explainability at the variable level. IMSVD has the potential to be adapted to other learning paradigms. Our code is publicly available at https://github.com/niuchuangnn/IMSVD.
Cross-Institutional Structured Radiology Reporting for Lung Cancer Screening Using a Dynamic Template-Constrained Large Language Model
Sep 26, 2024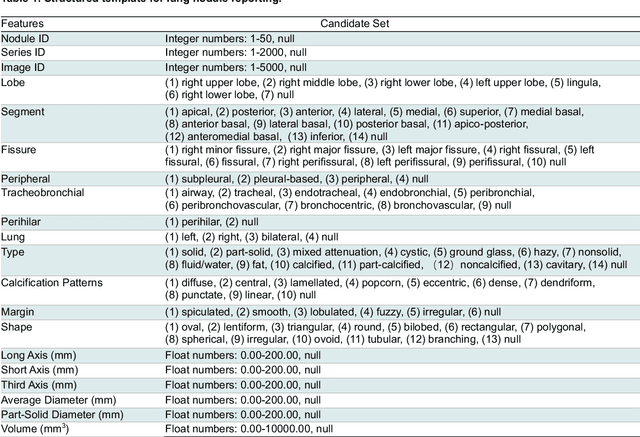
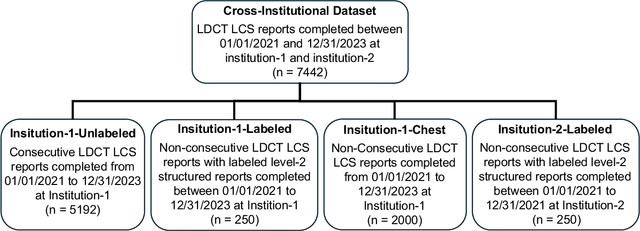
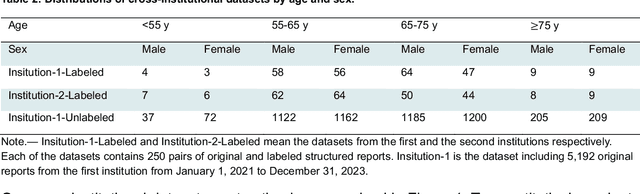
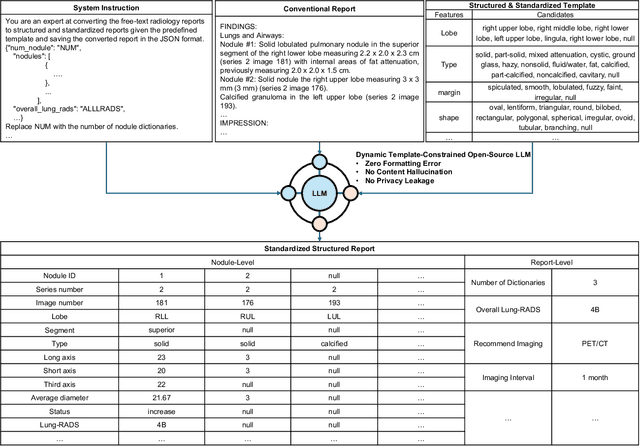
Structured radiology reporting is advantageous for optimizing clinical workflows and patient outcomes. Current LLMs in creating structured reports face the challenges of formatting errors, content hallucinations, and privacy leakage concerns when uploaded to external servers. We aim to develop an enhanced open-source LLM for creating structured and standardized LCS reports from free-text descriptions. After institutional IRB approvals, 5,442 de-identified LCS reports from two institutions were retrospectively analyzed. 500 reports were randomly selected from the two institutions evenly and then manually labeled for evaluation. Two radiologists from the two institutions developed a standardized template including 29 features for lung nodule reporting. We proposed template-constrained decoding to enhance state-of-the-art open-source LLMs, including LLAMA, Qwen, and Mistral. The LLM performance was extensively evaluated in terms of F1 score, confidence interval, McNemar test, and z-test. Based on the structured reports created from the large-scale dataset, a nodule-level retrieval system was prototyped and an automatic statistical analysis was performed. Our software, vLLM-structure, is publicly available for local deployment with enhanced LLMs. Our template-constrained decoding approach consistently enhanced the LLM performance on multi-institutional datasets, with neither formatting errors nor content hallucinations. Our method improved the best open-source LLAMA-3.1 405B by up to 10.42%, and outperformed GPT-4o by 17.19%. A novel nodule retrieval system was successfully prototyped and demonstrated on a large-scale multimodal database using our enhanced LLM technologies. The automatically derived statistical distributions were closely consistent with the prior findings in terms of nodule type, location, size, status, and Lung-RADS.
Deep Few-view High-resolution Photon-counting Extremity CT at Halved Dose for a Clinical Trial
Mar 19, 2024The latest X-ray photon-counting computed tomography (PCCT) for extremity allows multi-energy high-resolution (HR) imaging for tissue characterization and material decomposition. However, both radiation dose and imaging speed need improvement for contrast-enhanced and other studies. Despite the success of deep learning methods for 2D few-view reconstruction, applying them to HR volumetric reconstruction of extremity scans for clinical diagnosis has been limited due to GPU memory constraints, training data scarcity, and domain gap issues. In this paper, we propose a deep learning-based approach for PCCT image reconstruction at halved dose and doubled speed in a New Zealand clinical trial. Particularly, we present a patch-based volumetric refinement network to alleviate the GPU memory limitation, train network with synthetic data, and use model-based iterative refinement to bridge the gap between synthetic and real-world data. The simulation and phantom experiments demonstrate consistently improved results under different acquisition conditions on both in- and off-domain structures using a fixed network. The image quality of 8 patients from the clinical trial are evaluated by three radiologists in comparison with the standard image reconstruction with a full-view dataset. It is shown that our proposed approach is essentially identical to or better than the clinical benchmark in terms of diagnostic image quality scores. Our approach has a great potential to improve the safety and efficiency of PCCT without compromising image quality.
Low-dose CT Denoising with Language-engaged Dual-space Alignment
Mar 10, 2024



While various deep learning methods were proposed for low-dose computed tomography (CT) denoising, they often suffer from over-smoothing, blurring, and lack of explainability. To alleviate these issues, we propose a plug-and-play Language-Engaged Dual-space Alignment loss (LEDA) to optimize low-dose CT denoising models. Our idea is to leverage large language models (LLMs) to align denoised CT and normal dose CT images in both the continuous perceptual space and discrete semantic space, which is the first LLM-based scheme for low-dose CT denoising. LEDA involves two steps: the first is to pretrain an LLM-guided CT autoencoder, which can encode a CT image into continuous high-level features and quantize them into a token space to produce semantic tokens derived from the LLM's vocabulary; and the second is to minimize the discrepancy between the denoised CT images and normal dose CT in terms of both encoded high-level features and quantized token embeddings derived by the LLM-guided CT autoencoder. Extensive experimental results on two public LDCT denoising datasets demonstrate that our LEDA can enhance existing denoising models in terms of quantitative metrics and qualitative evaluation, and also provide explainability through language-level image understanding. Source code is available at https://github.com/hao1635/LEDA.
Photon-counting CT using a Conditional Diffusion Model for Super-resolution and Texture-preservation
Feb 25, 2024
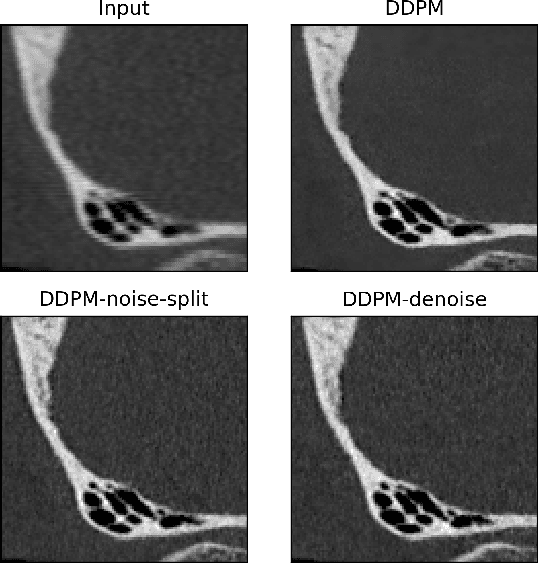
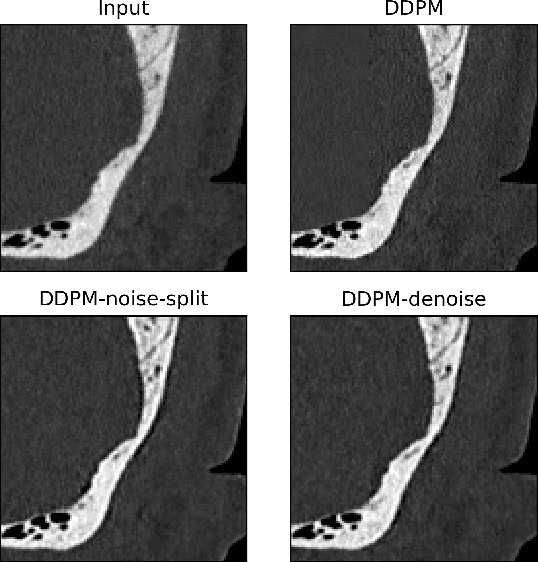
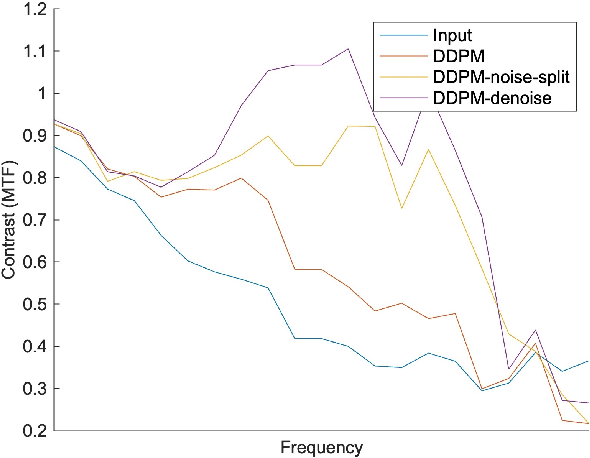
Ultra-high resolution images are desirable in photon counting CT (PCCT), but resolution is physically limited by interactions such as charge sharing. Deep learning is a possible method for super-resolution (SR), but sourcing paired training data that adequately models the target task is difficult. Additionally, SR algorithms can distort noise texture, which is an important in many clinical diagnostic scenarios. Here, we train conditional denoising diffusion probabilistic models (DDPMs) for PCCT super-resolution, with the objective to retain textural characteristics of local noise. PCCT simulation methods are used to synthesize realistic resolution degradation. To preserve noise texture, we explore decoupling the noise and signal image inputs and outputs via deep denoisers, explicitly mapping to each during the SR process. Our experimental results indicate that our DDPM trained on simulated data can improve sharpness in real PCCT images. Additionally, the disentanglement of noise from the original image allows our model more faithfully preserve noise texture.
IQAGPT: Image Quality Assessment with Vision-language and ChatGPT Models
Dec 25, 2023Large language models (LLMs), such as ChatGPT, have demonstrated impressive capabilities in various tasks and attracted an increasing interest as a natural language interface across many domains. Recently, large vision-language models (VLMs) like BLIP-2 and GPT-4 have been intensively investigated, which learn rich vision-language correlation from image-text pairs. However, despite these developments, the application of LLMs and VLMs in image quality assessment (IQA), particularly in medical imaging, remains to be explored, which is valuable for objective performance evaluation and potential supplement or even replacement of radiologists' opinions. To this end, this paper introduces IQAGPT, an innovative image quality assessment system integrating an image quality captioning VLM with ChatGPT for generating quality scores and textual reports. First, we build a CT-IQA dataset for training and evaluation, comprising 1,000 CT slices with diverse quality levels professionally annotated. To better leverage the capabilities of LLMs, we convert annotated quality scores into semantically rich text descriptions using a prompt template. Second, we fine-tune the image quality captioning VLM on the CT-IQA dataset to generate quality descriptions. The captioning model fuses the image and text features through cross-modal attention. Third, based on the quality descriptions, users can talk with ChatGPT to rate image quality scores or produce a radiological quality report. Our preliminary results demonstrate the feasibility of assessing image quality with large models. Remarkably, our IQAGPT outperforms GPT-4 and CLIP-IQA, as well as the multi-task classification and regression models that solely rely on images.
Diffusion Prior Regularized Iterative Reconstruction for Low-dose CT
Oct 10, 2023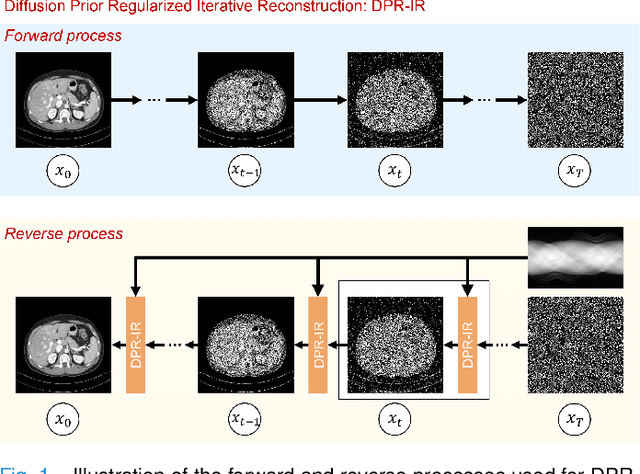
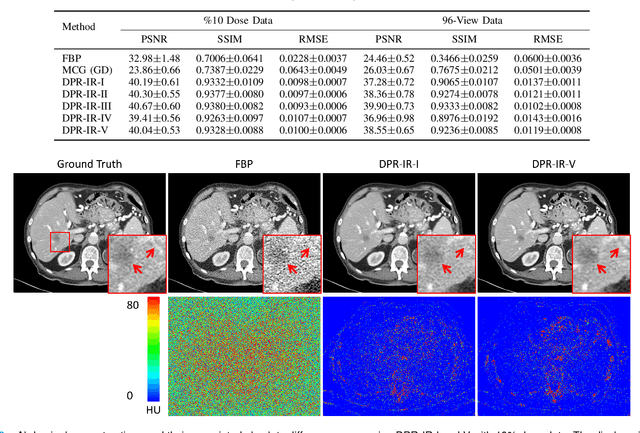
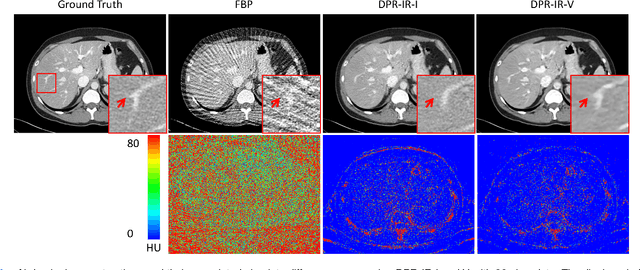
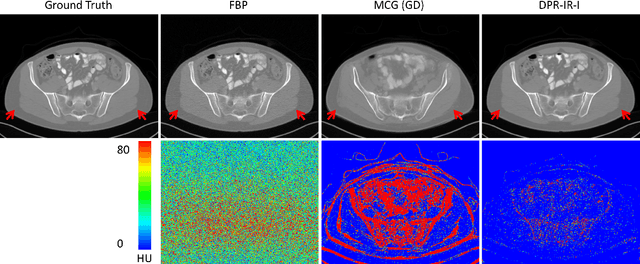
Computed tomography (CT) involves a patient's exposure to ionizing radiation. To reduce the radiation dose, we can either lower the X-ray photon count or down-sample projection views. However, either of the ways often compromises image quality. To address this challenge, here we introduce an iterative reconstruction algorithm regularized by a diffusion prior. Drawing on the exceptional imaging prowess of the denoising diffusion probabilistic model (DDPM), we merge it with a reconstruction procedure that prioritizes data fidelity. This fusion capitalizes on the merits of both techniques, delivering exceptional reconstruction results in an unsupervised framework. To further enhance the efficiency of the reconstruction process, we incorporate the Nesterov momentum acceleration technique. This enhancement facilitates superior diffusion sampling in fewer steps. As demonstrated in our experiments, our method offers a potential pathway to high-definition CT image reconstruction with minimized radiation.
Head-Neck Dual-energy CT Contrast Media Reduction Using Diffusion Models
Aug 24, 2023



Iodinated contrast media is essential for dual-energy computed tomography (DECT) angiography. Previous studies show that iodinated contrast media may cause side effects, and the interruption of the supply chain in 2022 led to a severe contrast media shortage in the US. Both factors justify the necessity of contrast media reduction in relevant clinical applications. In this study, we propose a diffusion model-based deep learning framework to address this challenge. First, we simulate different levels of low contrast dosage DECT scans from the standard normal contrast dosage DECT scans using material decomposition. Conditional denoising diffusion probabilistic models are then trained to enhance the contrast media and create contrast-enhanced images. Our results demonstrate that the proposed methods can generate high-quality contrast-enhanced results even for images obtained with as low as 12.5% of the normal contrast dosage. Furthermore, our method outperforms selected competing methods in a human reader study.
CT Multi-Task Learning with a Large Image-Text Model
Apr 03, 2023Large language models (LLM) not only empower multiple language tasks but also serve as a general interface across different spaces. Up to now, it has not been demonstrated yet how to effectively translate the successes of LLMs in the computer vision field to the medical imaging field which involves high-dimensional and multi-modal medical images. In this paper, we report a feasibility study of building a multi-task CT large image-text (LIT) model for lung cancer diagnosis by combining an LLM and a large image model (LIM). Specifically, the LLM and LIM are used as encoders to perceive multi-modal information under task-specific text prompts, which synergizes multi-source information and task-specific and patient-specific priors for optimized diagnostic performance. The key components of our LIT model and associated techniques are evaluated with an emphasis on 3D lung CT analysis. Our initial results show that the LIT model performs multiple medical tasks well, including lung segmentation, lung nodule detection, and lung cancer classification. Active efforts are in progress to develop large image-language models for superior medical imaging in diverse applications and optimal patient outcomes.