 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Maximized Soft Variable Discretization for Self-Supervised Image Representation Learning
Jan 07, 2025



Self-supervised learning (SSL) has emerged as a crucial technique in image processing, encoding, and understanding, especially for developing today's vision foundation models that utilize large-scale datasets without annotations to enhance various downstream tasks. This study introduces a novel SSL approach, Information-Maximized Soft Variable Discretization (IMSVD), for image representation learning. Specifically, IMSVD softly discretizes each variable in the latent space, enabling the estimation of their probability distributions over training batches and allowing the learning process to be directly guided by information measures. Motivated by the MultiView assumption, we propose an information-theoretic objective function to learn transform-invariant, non-travail, and redundancy-minimized representation features. We then derive a joint-cross entropy loss function for self-supervised image representation learning, which theoretically enjoys superiority over the existing methods in reducing feature redundancy. Notably, our non-contrastive IMSVD method statistically performs contrastive learning. Extensive experimental results demonstrate the effectiveness of IMSVD on various downstream tasks in terms of both accuracy and efficiency. Thanks to our variable discretization, the embedding features optimized by IMSVD offer unique explainability at the variable level. IMSVD has the potential to be adapted to other learning paradigms. Our code is publicly available at https://github.com/niuchuangnn/IMSVD.
Diffusion Prior Regularized Iterative Reconstruction for Low-dose CT
Oct 10, 2023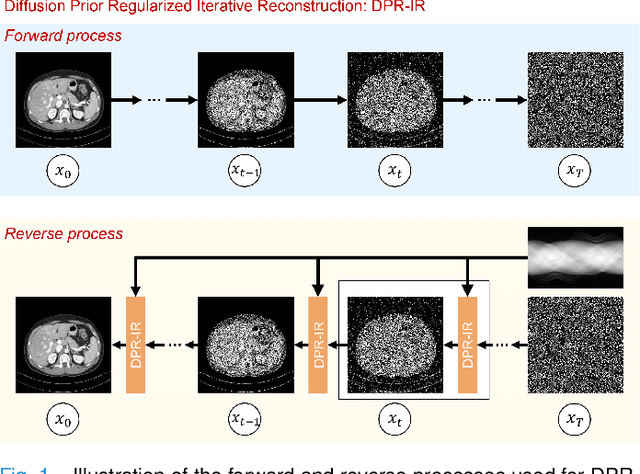
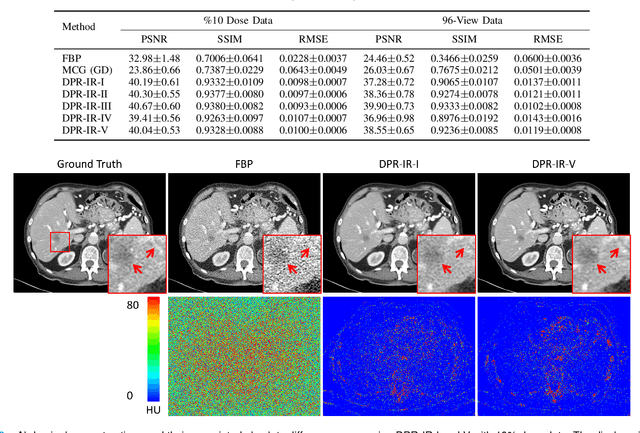
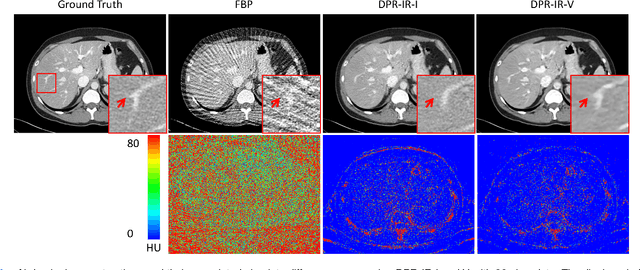
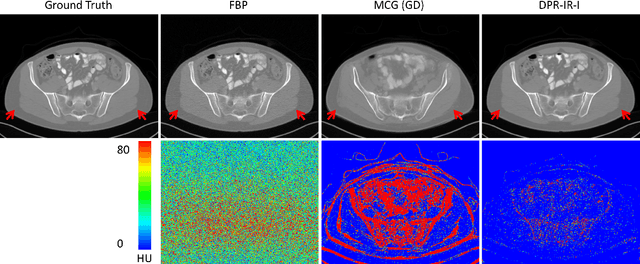
Computed tomography (CT) involves a patient's exposure to ionizing radiation. To reduce the radiation dose, we can either lower the X-ray photon count or down-sample projection views. However, either of the ways often compromises image quality. To address this challenge, here we introduce an iterative reconstruction algorithm regularized by a diffusion prior. Drawing on the exceptional imaging prowess of the denoising diffusion probabilistic model (DDPM), we merge it with a reconstruction procedure that prioritizes data fidelity. This fusion capitalizes on the merits of both techniques, delivering exceptional reconstruction results in an unsupervised framework. To further enhance the efficiency of the reconstruction process, we incorporate the Nesterov momentum acceleration technique. This enhancement facilitates superior diffusion sampling in fewer steps. As demonstrated in our experiments, our method offers a potential pathway to high-definition CT image reconstruction with minimized radiation.
Blind CT Image Quality Assessment Using DDPM-derived Content and Transformer-based Evaluator
Oct 04, 2023Lowering radiation dose per view and utilizing sparse views per scan are two common CT scan modes, albeit often leading to distorted images characterized by noise and streak artifacts. Blind image quality assessment (BIQA) strives to evaluate perceptual quality in alignment with what radiologists perceive, which plays an important role in advancing low-dose CT reconstruction techniques. An intriguing direction involves developing BIQA methods that mimic the operational characteristic of the human visual system (HVS). The internal generative mechanism (IGM) theory reveals that the HVS actively deduces primary content to enhance comprehension. In this study, we introduce an innovative BIQA metric that emulates the active inference process of IGM. Initially, an active inference module, implemented as a denoising diffusion probabilistic model (DDPM), is constructed to anticipate the primary content. Then, the dissimilarity map is derived by assessing the interrelation between the distorted image and its primary content. Subsequently, the distorted image and dissimilarity map are combined into a multi-channel image, which is inputted into a transformer-based image quality evaluator. Remarkably, by exclusively utilizing this transformer-based quality evaluator, we won the second place in the MICCAI 2023 low-dose computed tomography perceptual image quality assessment grand challenge. Leveraging the DDPM-derived primary content, our approach further improves the performance on the challenge dataset.
Sub-volume-based Denoising Diffusion Probabilistic Model for Cone-beam CT Reconstruction from Incomplete Data
Mar 25, 2023Deep learning (DL) has emerged as a new approach in the field of computed tomography (CT) with many applicaitons. A primary example is CT reconstruction from incomplete data, such as sparse-view image reconstruction. However, applying DL to sparse-view cone-beam CT (CBCT) remains challenging. Many models learn the mapping from sparse-view CT images to the ground truth but often fail to achieve satisfactory performance. Incorporating sinogram data and performing dual-domain reconstruction improve image quality with artifact suppression, but a straightforward 3D implementation requires storing an entire 3D sinogram in memory and many parameters of dual-domain networks. This remains a major challenge, limiting further research, development and applications. In this paper, we propose a sub-volume-based 3D denoising diffusion probabilistic model (DDPM) for CBCT image reconstruction from down-sampled data. Our DDPM network, trained on data cubes extracted from paired fully sampled sinograms and down-sampled sinograms, is employed to inpaint down-sampled sinograms. Our method divides the entire sinogram into overlapping cubes and processes them in parallel on multiple GPUs, successfully overcoming the memory limitation. Experimental results demonstrate that our approach effectively suppresses few-view artifacts while preserving textural details faithfully.
Patch-Based Denoising Diffusion Probabilistic Model for Sparse-View CT Reconstruction
Nov 18, 2022



Sparse-view computed tomography (CT) can be used to reduce radiation dose greatly but is suffers from severe image artifacts. Recently, the deep learning based method for sparse-view CT reconstruction has attracted a major attention. However, neural networks often have a limited ability to remove the artifacts when they only work in the image domain. Deep learning-based sinogram processing can achieve a better anti-artifact performance, but it inevitably requires feature maps of the whole image in a video memory, which makes handling large-scale or three-dimensional (3D) images rather challenging. In this paper, we propose a patch-based denoising diffusion probabilistic model (DDPM) for sparse-view CT reconstruction. A DDPM network based on patches extracted from fully sampled projection data is trained and then used to inpaint down-sampled projection data. The network does not require paired full-sampled and down-sampled data, enabling unsupervised learning. Since the data processing is patch-based, the deep learning workflow can be distributed in parallel, overcoming the memory problem of large-scale data. Our experiments show that the proposed method can effectively suppress few-view artifacts while faithfully preserving textural details.
Low-Dose CT Using Denoising Diffusion Probabilistic Model for 20$\times$ Speedup
Sep 29, 2022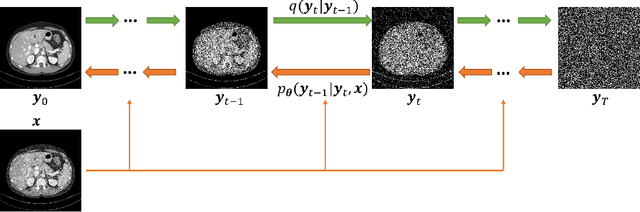
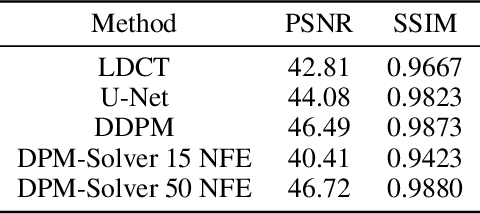
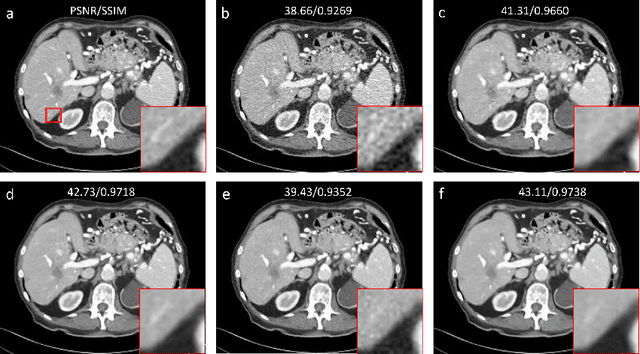

Low-dose computed tomography (LDCT) is an important topic in the field of radiology over the past decades. LDCT reduces ionizing radiation-induced patient health risks but it also results in a low signal-to-noise ratio (SNR) and a potential compromise in the diagnostic performance. In this paper, to improve the LDCT denoising performance, we introduce the conditional denoising diffusion probabilistic model (DDPM) and show encouraging results with a high computational efficiency. Specifically, given the high sampling cost of the original DDPM model, we adapt the fast ordinary differential equation (ODE) solver for a much-improved sampling efficiency. The experiments show that the accelerated DDPM can achieve 20x speedup without compromising image quality.
Hypernetwork-based Personalized Federated Learning for Multi-Institutional CT Imaging
Jun 09, 2022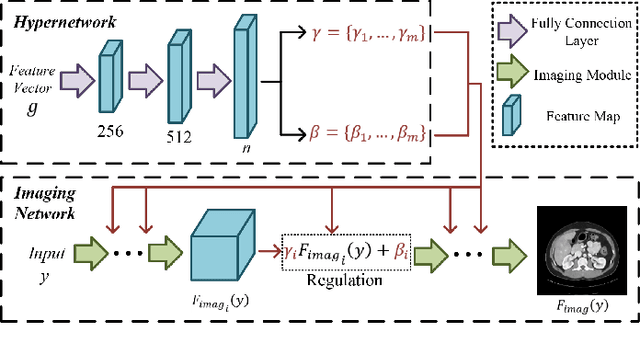
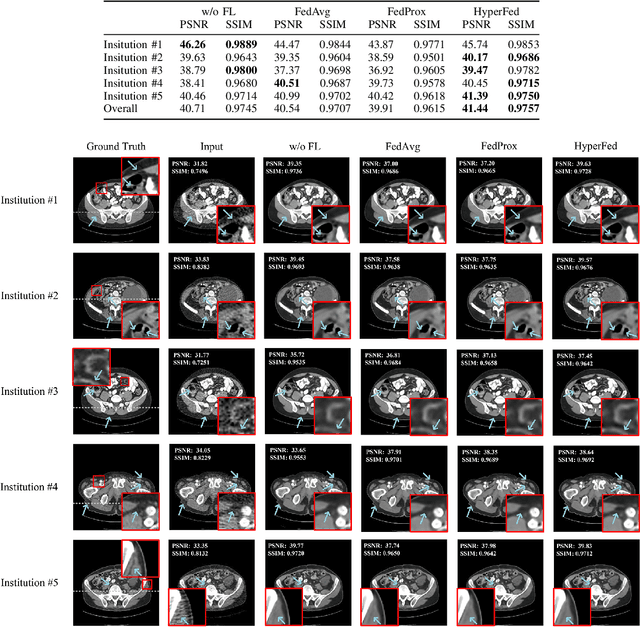
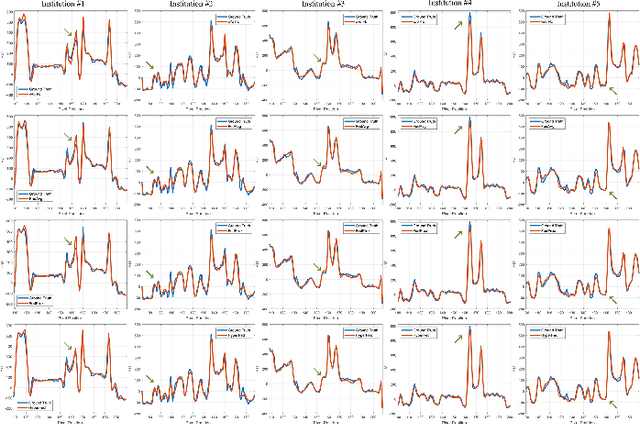
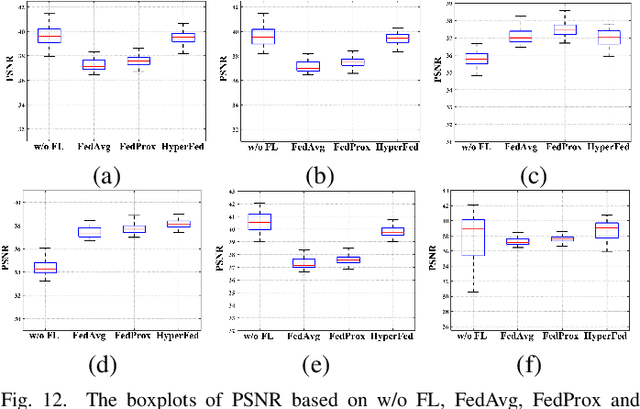
Computed tomography (CT) is of great importance in clinical practice due to its powerful ability to provide patients' anatomical information without any invasive inspection, but its potential radiation risk is raising people's concerns. Deep learning-based methods are considered promising in CT reconstruction, but these network models are usually trained with the measured data obtained from specific scanning protocol and need to centralizedly collect large amounts of data, which will lead to serious data domain shift, and privacy concerns. To relieve these problems, in this paper, we propose a hypernetwork-based federated learning method for personalized CT imaging, dubbed as HyperFed. The basic assumption of HyperFed is that the optimization problem for each institution can be divided into two parts: the local data adaption problem and the global CT imaging problem, which are implemented by an institution-specific hypernetwork and a global-sharing imaging network, respectively. The purpose of global-sharing imaging network is to learn stable and effective common features from different institutions. The institution-specific hypernetwork is carefully designed to obtain hyperparameters to condition the global-sharing imaging network for personalized local CT reconstruction. Experiments show that HyperFed achieves competitive performance in CT reconstruction compared with several other state-of-the-art methods. It is believed as a promising direction to improve CT imaging quality and achieve personalized demands of different institutions or scanners without privacy data sharing. The codes will be released at https://github.com/Zi-YuanYang/HyperFed.
Synergizing Physics/Model-based and Data-driven Methods for Low-Dose CT
Mar 29, 2022



Since 2016, deep learning (DL) has advanced tomographic imaging with remarkable successes, especially in low-dose computed tomography (LDCT) imaging. Despite being driven by big data, the LDCT denoising and pure end-to-end reconstruction networks often suffer from the black box nature and major issues such as instabilities, which is a major barrier to apply deep learning methods in low-dose CT applications. An emerging trend is to integrate imaging physics and model into deep networks, enabling a hybridization of physics/model-based and data-driven elements. In this paper, we systematically review the physics/model-based data-driven methods for LDCT, summarize the loss functions and training strategies, evaluate the performance of different methods, and discuss relevant issues and future directions
Unsupervised PET Reconstruction from a Bayesian Perspective
Oct 29, 2021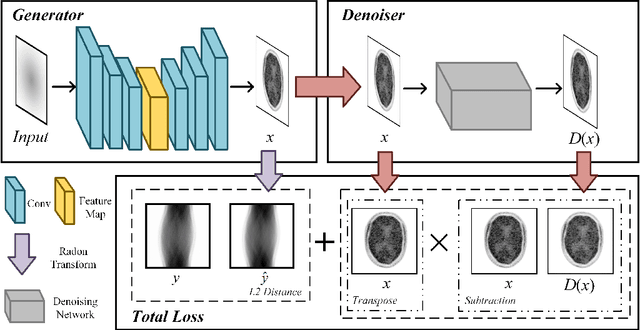

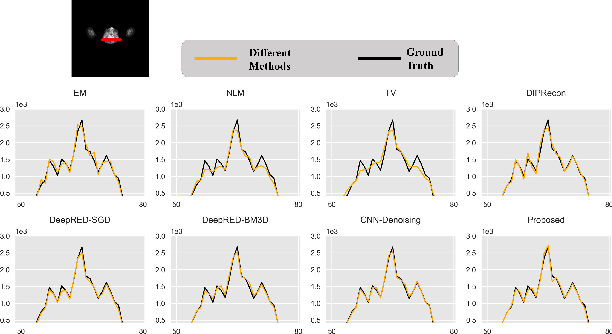
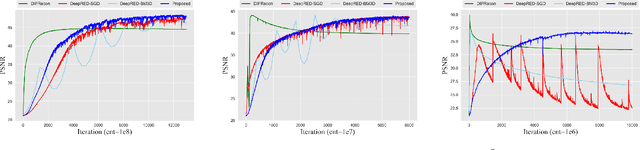
Positron emission tomography (PET) reconstruction has become an ill-posed inverse problem due to low-count projection data, and a robust algorithm is urgently required to improve imaging quality. Recently, the deep image prior (DIP) has drawn much attention and has been successfully applied in several image restoration tasks, such as denoising and inpainting, since it does not need any labels (reference image). However, overfitting is a vital defect of this framework. Hence, many methods have been proposed to mitigate this problem, and DeepRED is a typical representation that combines DIP and regularization by denoising (RED). In this article, we leverage DeepRED from a Bayesian perspective to reconstruct PET images from a single corrupted sinogram without any supervised or auxiliary information. In contrast to the conventional denoisers customarily used in RED, a DnCNN-like denoiser, which can add an adaptive constraint to DIP and facilitate the computation of derivation, is employed. Moreover, to further enhance the regularization, Gaussian noise is injected into the gradient updates, deriving a Markov chain Monte Carlo (MCMC) sampler. Experimental studies on brain and whole-body datasets demonstrate that our proposed method can achieve better performance in terms of qualitative and quantitative results compared to several classic and state-of-the-art methods.
One Network to Solve Them All: A Sequential Multi-Task Joint Learning Network Framework for MR Imaging Pipeline
May 14, 2021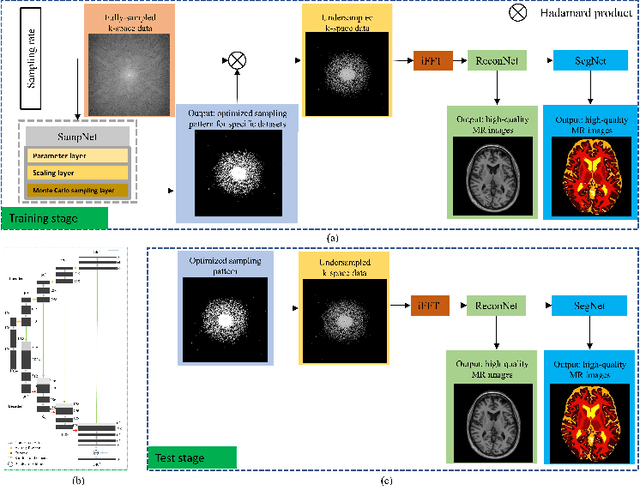
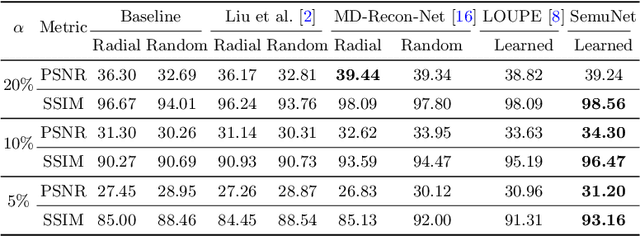
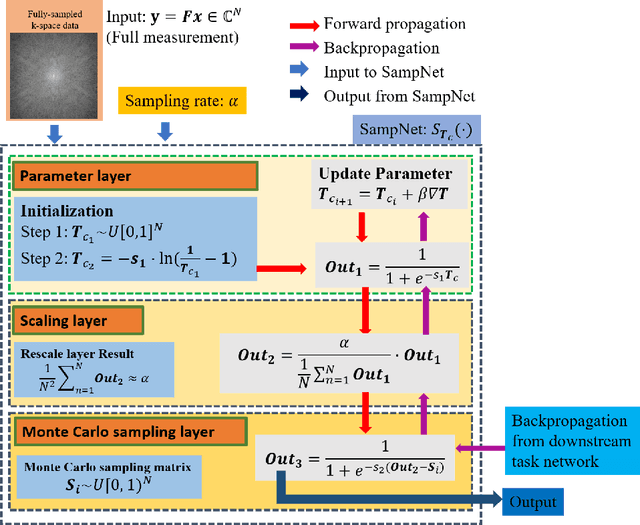
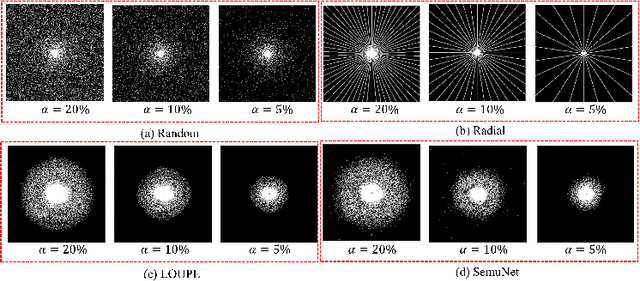
Magnetic resonance imaging (MRI) acquisition, reconstruction, and segmentation are usually processed independently in the conventional practice of MRI workflow. It is easy to notice that there are significant relevances among these tasks and this procedure artificially cuts off these potential connections, which may lead to losing clinically important information for the final diagnosis. To involve these potential relations for further performance improvement, a sequential multi-task joint learning network model is proposed to train a combined end-to-end pipeline in a differentiable way, aiming at exploring the mutual influence among those tasks simultaneously. Our design consists of three cascaded modules: 1) deep sampling pattern learning module optimizes the $k$-space sampling pattern with predetermined sampling rate; 2) deep reconstruction module is dedicated to reconstructing MR images from the undersampled data using the learned sampling pattern; 3) deep segmentation module encodes MR images reconstructed from the previous module to segment the interested tissues. The proposed model retrieves the latently interactive and cyclic relations among those tasks, from which each task will be mutually beneficial. The proposed framework is verified on MRB dataset, which achieves superior performance on other SOTA methods in terms of both reconstruction and segmentation.