 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedRIR: Rethinking Information Representation in Federated Learning
Feb 02, 2025Mobile and Web-of-Things (WoT) devices at the network edge generate vast amounts of data for machine learning applications, yet privacy concerns hinder centralized model training. Federated Learning (FL) allows clients (devices) to collaboratively train a shared model coordinated by a central server without transfer private data, but inherent statistical heterogeneity among clients presents challenges, often leading to a dilemma between clients' needs for personalized local models and the server's goal of building a generalized global model. Existing FL methods typically prioritize either global generalization or local personalization, resulting in a trade-off between these two objectives and limiting the full potential of diverse client data. To address this challenge, we propose a novel framework that simultaneously enhances global generalization and local personalization by Rethinking Information Representation in the Federated learning process (FedRIR). Specifically, we introduce Masked Client-Specific Learning (MCSL), which isolates and extracts fine-grained client-specific features tailored to each client's unique data characteristics, thereby enhancing personalization. Concurrently, the Information Distillation Module (IDM) refines the global shared features by filtering out redundant client-specific information, resulting in a purer and more robust global representation that enhances generalization. By integrating the refined global features with the isolated client-specific features, we construct enriched representations that effectively capture both global patterns and local nuances, thereby improving the performance of downstream tasks on the client. The code is available at https://github.com/Deep-Imaging-Group/FedRIR.
Navigate Complex Physical Worlds via Geometrically Constrained LLM
Oct 23, 2024
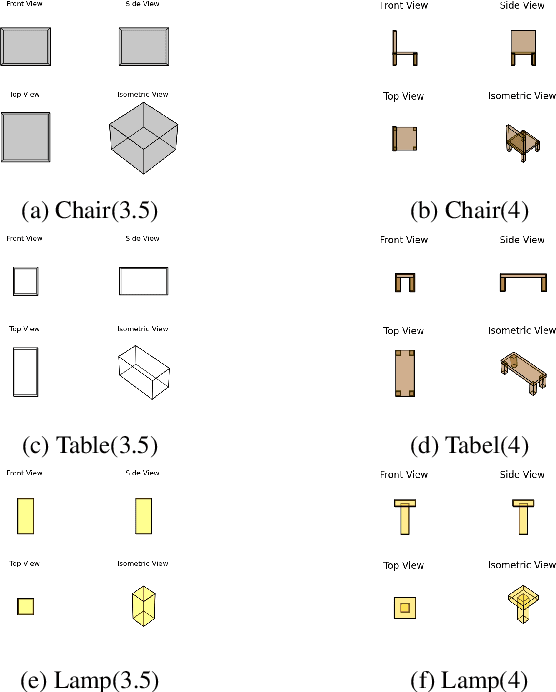
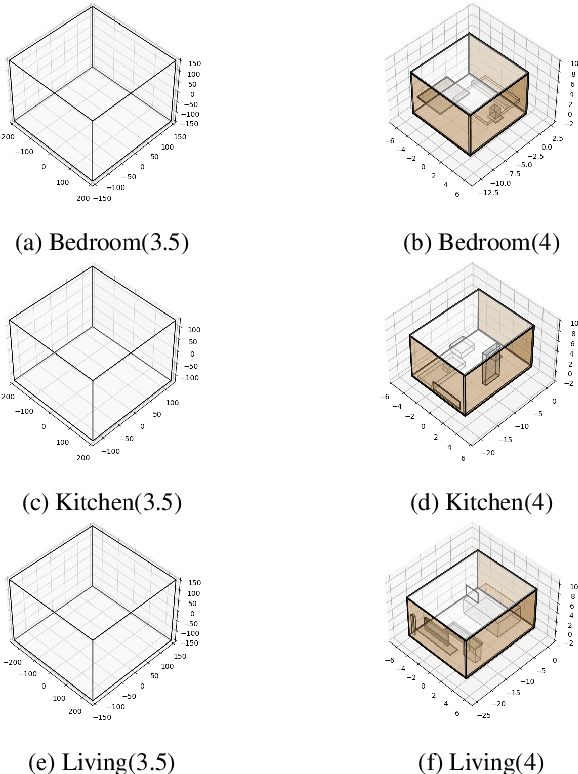

This study investigates the potential of Large Language Models (LLMs) for reconstructing and constructing the physical world solely based on textual knowledge. It explores the impact of model performance on spatial understanding abilities. To enhance the comprehension of geometric and spatial relationships in the complex physical world, the study introduces a set of geometric conventions and develops a workflow based on multi-layer graphs and multi-agent system frameworks. It examines how LLMs achieve multi-step and multi-objective geometric inference in a spatial environment using multi-layer graphs under unified geometric conventions. Additionally, the study employs a genetic algorithm, inspired by large-scale model knowledge, to solve geometric constraint problems. In summary, this work innovatively explores the feasibility of using text-based LLMs as physical world builders and designs a workflow to enhance their capabilities.
One Network to Solve Them All: A Sequential Multi-Task Joint Learning Network Framework for MR Imaging Pipeline
May 14, 2021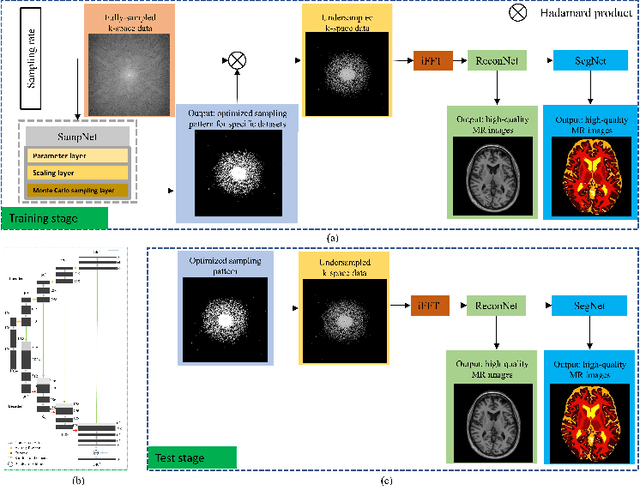
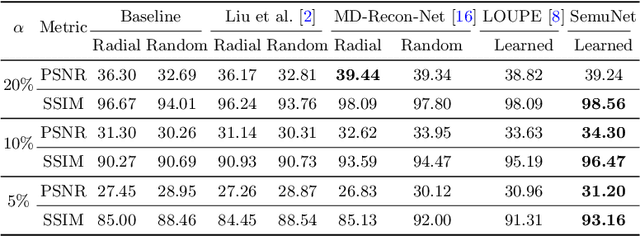
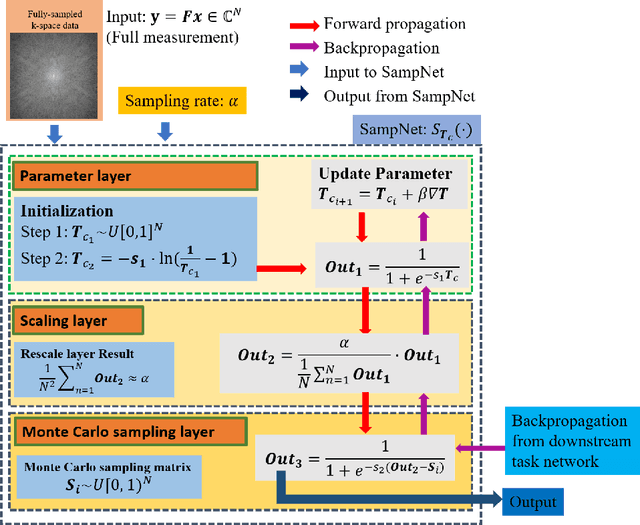
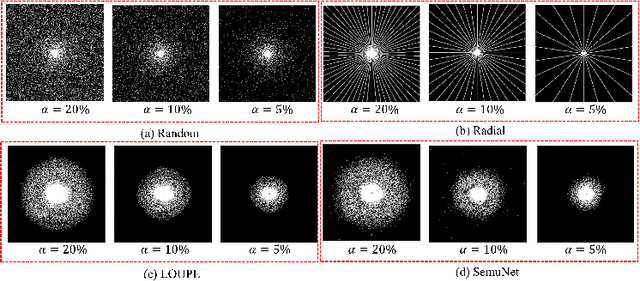
Magnetic resonance imaging (MRI) acquisition, reconstruction, and segmentation are usually processed independently in the conventional practice of MRI workflow. It is easy to notice that there are significant relevances among these tasks and this procedure artificially cuts off these potential connections, which may lead to losing clinically important information for the final diagnosis. To involve these potential relations for further performance improvement, a sequential multi-task joint learning network model is proposed to train a combined end-to-end pipeline in a differentiable way, aiming at exploring the mutual influence among those tasks simultaneously. Our design consists of three cascaded modules: 1) deep sampling pattern learning module optimizes the $k$-space sampling pattern with predetermined sampling rate; 2) deep reconstruction module is dedicated to reconstructing MR images from the undersampled data using the learned sampling pattern; 3) deep segmentation module encodes MR images reconstructed from the previous module to segment the interested tissues. The proposed model retrieves the latently interactive and cyclic relations among those tasks, from which each task will be mutually beneficial. The proposed framework is verified on MRB dataset, which achieves superior performance on other SOTA methods in terms of both reconstruction and segmentation.
MANAS: Multi-Scale and Multi-Level Neural Architecture Search for Low-Dose CT Denoising
Mar 24, 2021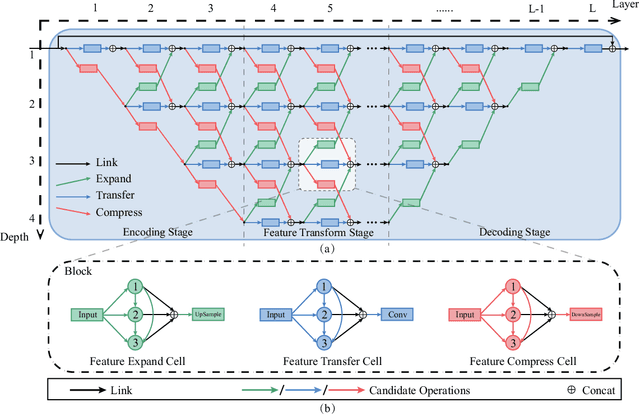

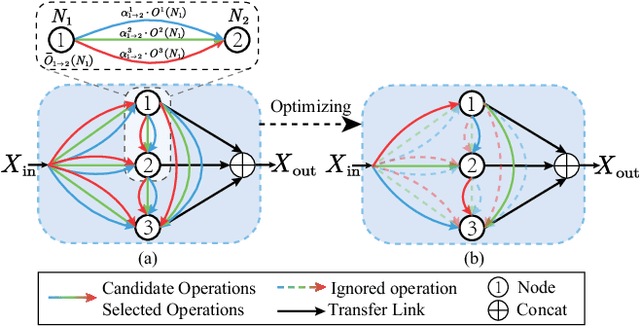
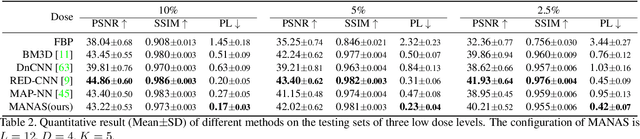
Lowering the radiation dose in computed tomography (CT) can greatly reduce the potential risk to public health. However, the reconstructed images from the dose-reduced CT or low-dose CT (LDCT) suffer from severe noise, compromising the subsequent diagnosis and analysis. Recently, convolutional neural networks have achieved promising results in removing noise from LDCT images; the network architectures used are either handcrafted or built on top of conventional networks such as ResNet and U-Net. Recent advance on neural network architecture search (NAS) has proved that the network architecture has a dramatic effect on the model performance, which indicates that current network architectures for LDCT may be sub-optimal. Therefore, in this paper, we make the first attempt to apply NAS to LDCT and propose a multi-scale and multi-level NAS for LDCT denoising, termed MANAS. On the one hand, the proposed MANAS fuses features extracted by different scale cells to capture multi-scale image structural details. On the other hand, the proposed MANAS can search a hybrid cell- and network-level structure for better performance. Extensively experimental results on three different dose levels demonstrate that the proposed MANAS can achieve better performance in terms of preserving image structural details than several state-of-the-art methods. In addition, we also validate the effectiveness of the multi-scale and multi-level architecture for LDCT denoising.
DAN-Net: Dual-Domain Adaptive-Scaling Non-local Network for CT Metal Artifact Reduction
Feb 16, 2021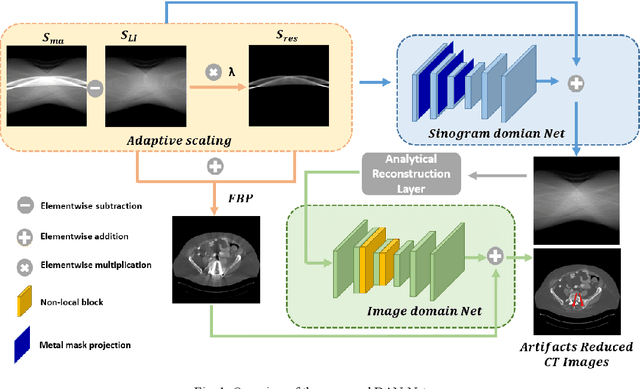
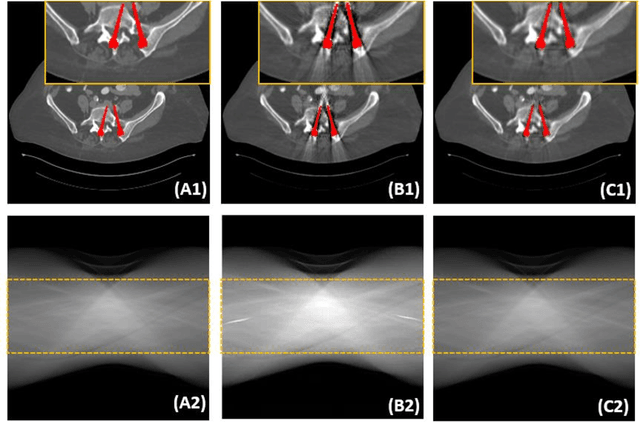
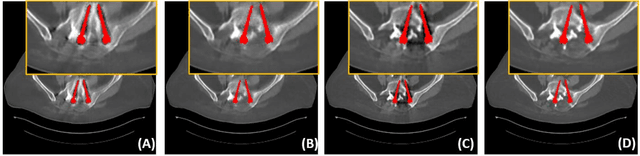
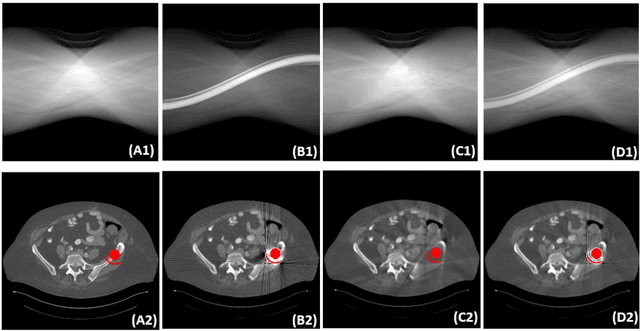
Metal implants can heavily attenuate X-rays in computed tomography (CT) scans, leading to severe artifacts in reconstructed images, which significantly jeopardize image quality and negatively impact subsequent diagnoses and treatment planning. With the rapid development of deep learning in the field of medical imaging, several network models have been proposed for metal artifact reduction (MAR) in CT. Despite the encouraging results achieved by these methods, there is still much room to further improve performance. In this paper, a novel Dual-domain Adaptive-scaling Non-local network (DAN-Net) for MAR. We correct the corrupted sinogram using adaptive scaling first to preserve more tissue and bone details as a more informative input. Then, an end-to-end dual-domain network is adopted to successively process the sinogram and its corresponding reconstructed image generated by the analytical reconstruction layer. In addition, to better suppress the existing artifacts and restrain the potential secondary artifacts caused by inaccurate results of the sinogram-domain network, a novel residual sinogram learning strategy and nonlocal module are leveraged in the proposed network model. In the experiments, the proposed DAN-Net demonstrates performance competitive with several state-of-the-art MAR methods in both qualitative and quantitative aspects.
Robot Gaining Accurate Pouring Skills through Self-Supervised Learning and Generalization
Nov 19, 2020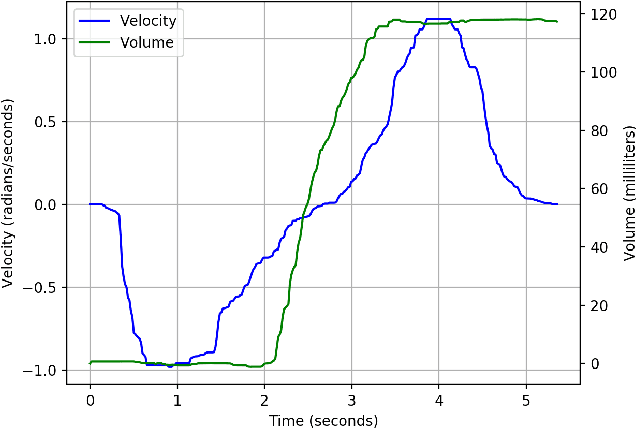
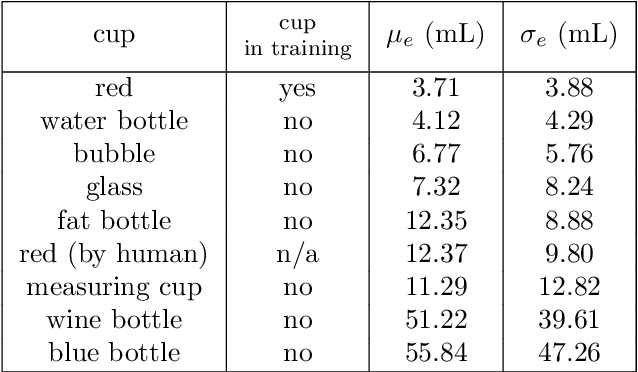
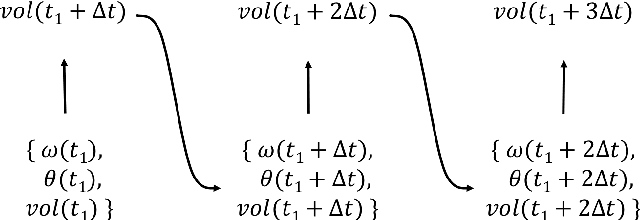
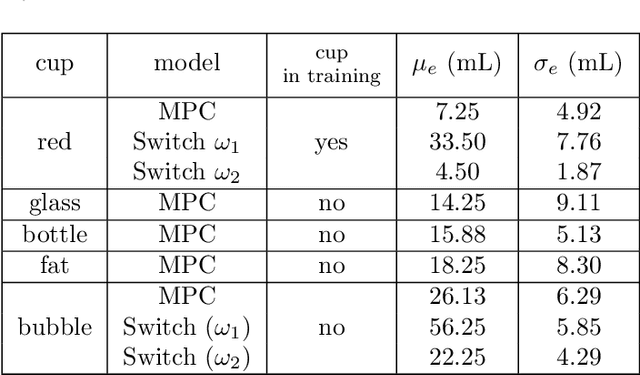
Pouring is one of the most commonly executed tasks in humans' daily lives, whose accuracy is affected by multiple factors, including the type of material to be poured and the geometry of the source and receiving containers. In this work, we propose a self-supervised learning approach that learns the pouring dynamics, pouring motion, and outcomes from unsupervised demonstrations for accurate pouring. The learned pouring model is then generalized by self-supervised practicing to different conditions such as using unaccustomed pouring cups. We have evaluated the proposed approach first with one container from the training set and four new but similar containers. The proposed approach achieved better pouring accuracy than a regular human with a similar pouring speed for all five cups. Both the accuracy and pouring speed outperform state-of-the-art works. We have also evaluated the proposed self-supervised generalization approach using unaccustomed containers that are far different from the ones in the training set. The self-supervised generalization reduces the pouring error of the unaccustomed containers to the desired accuracy level.
CT Reconstruction with PDF: Parameter-Dependent Framework for Multiple Scanning Geometries and Dose Levels
Oct 27, 2020
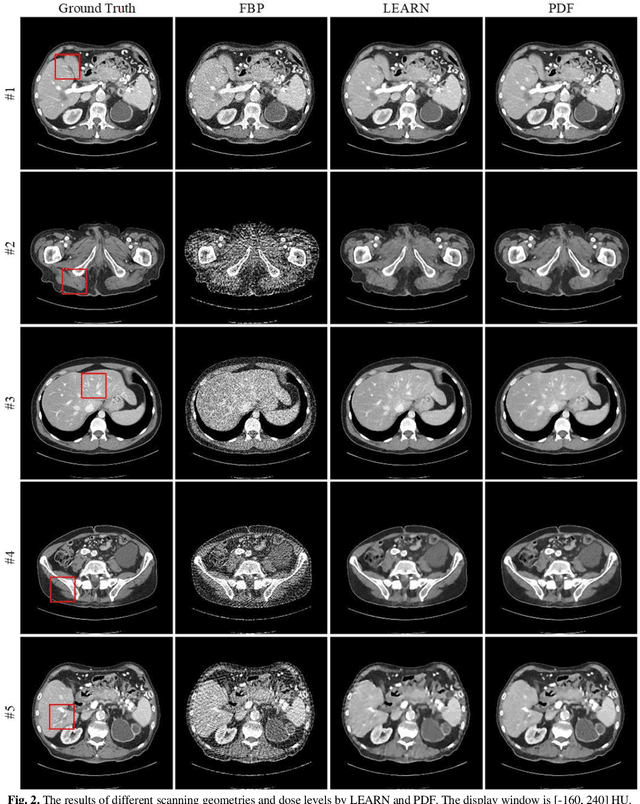

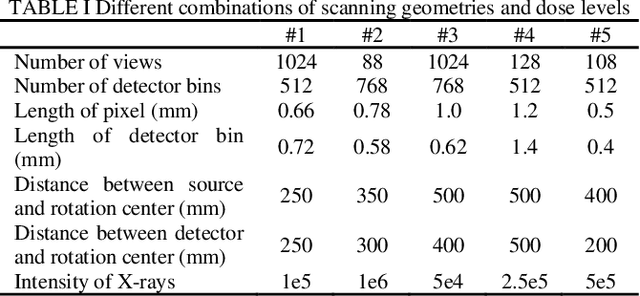
Current mainstream of CT reconstruction methods based on deep learning usually needs to fix the scanning geometry and dose level, which will significantly aggravate the training cost and need more training data for clinical application. In this paper, we propose a parameter-dependent framework (PDF) which trains data with multiple scanning geometries and dose levels simultaneously. In the proposed PDF, the geometry and dose level are parameterized and fed into two multi-layer perceptrons (MLPs). The MLPs are leveraged to modulate the feature maps of CT reconstruction network, which condition the network outputs on different scanning geometries and dose levels. The experiments show that our proposed method can obtain competing performance similar to the original network trained with specific geometry and dose level, which can efficiently save the extra training cost for multiple scanning geometries and dose levels.
Manipulation Motion Taxonomy and Coding for Robots
Oct 01, 2019
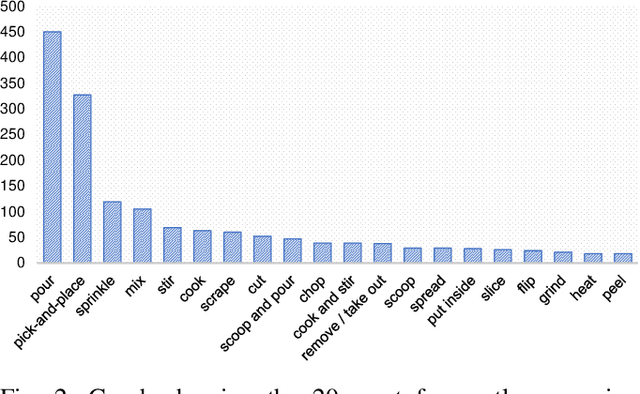
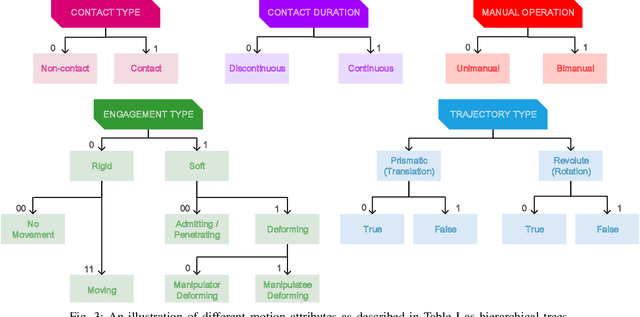
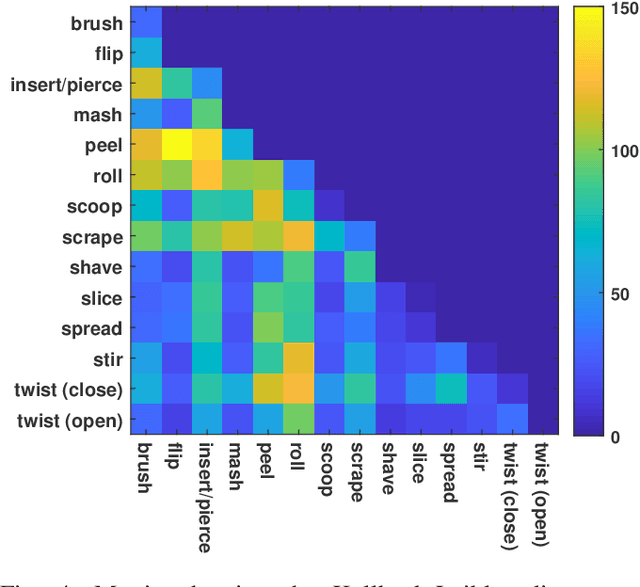
This paper introduces a taxonomy of manipulations as seen especially in cooking for 1) grouping manipulations from the robotics point of view, 2) consolidating aliases and removing ambiguity for motion types, and 3) provide a path to transferring learned manipulations to new unlearned manipulations. Using instructional videos as a reference, we selected a list of common manipulation motions seen in cooking activities grouped into similar motions based on several trajectory and contact attributes. Manipulation codes are then developed based on the taxonomy attributes to represent the manipulation motions. The manipulation taxonomy is then used for comparing motion data in the Daily Interactive Manipulation (DIM) data set to reveal their motion similarities.
Accurate Robotic Pouring for Serving Drinks
Jun 21, 2019



Pouring is the second most frequently executed motion in cooking scenarios. In this work, we present our system of accurate pouring that generates the angular velocities of the source container using recurrent neural networks. We collected demonstrations of human pouring water. We made a physical system on which the velocities of the source container were generated at each time step and executed by a motor. We tested our system on pouring water from containers that are not used for training and achieved an error of as low as 4 milliliters. We also used the system to pour oil and syrup. The accuracy achieved with oil is slightly lower than but comparable with that of water.
Functional Object-Oriented Network for Manipulation Learning
Feb 05, 2019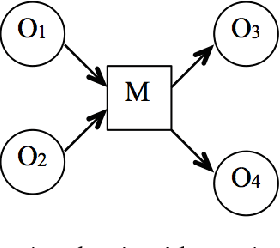
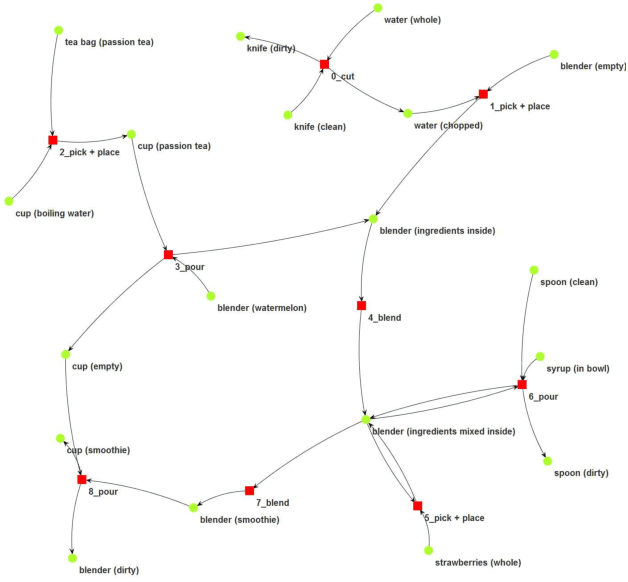


This paper presents a novel structured knowledge representation called the functional object-oriented network (FOON) to model the connectivity of the functional-related objects and their motions in manipulation tasks. The graphical model FOON is learned by observing object state change and human manipulations with the objects. Using a well-trained FOON, robots can decipher a task goal, seek the correct objects at the desired states on which to operate, and generate a sequence of proper manipulation motions. The paper describes FOON's structure and an approach to form a universal FOON with extracted knowledge from online instructional videos. A graph retrieval approach is presented to generate manipulation motion sequences from the FOON to achieve a desired goal, demonstrating the flexibility of FOON in creating a novel and adaptive means of solving a problem using knowledge gathered from multiple sources. The results are demonstrated in a simulated environment to illustrate the motion sequences generated from the FOON to carry out the desired tasks.
* Conference Paper for IROS 2016