 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Gaining Accurate Pouring Skills through Self-Supervised Learning and Generalization
Nov 19, 2020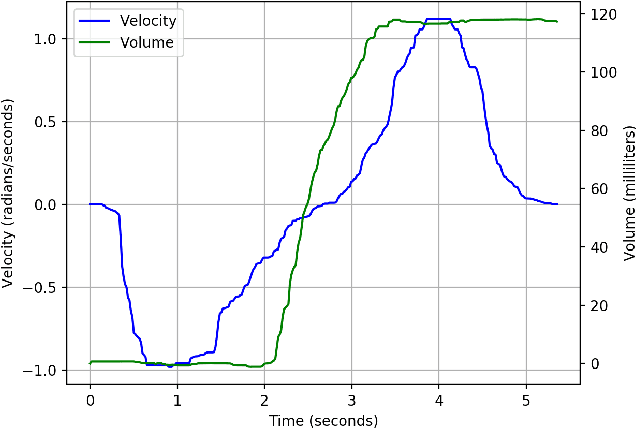
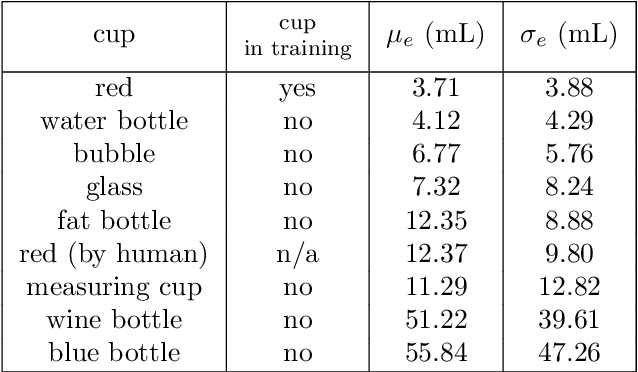
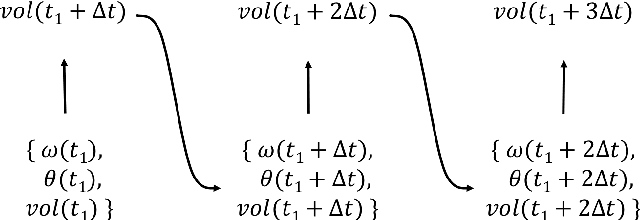
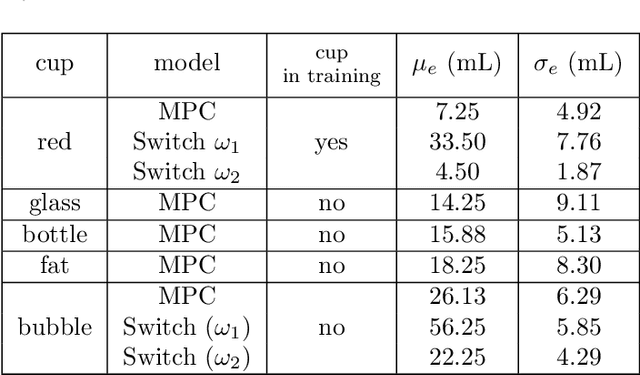
Pouring is one of the most commonly executed tasks in humans' daily lives, whose accuracy is affected by multiple factors, including the type of material to be poured and the geometry of the source and receiving containers. In this work, we propose a self-supervised learning approach that learns the pouring dynamics, pouring motion, and outcomes from unsupervised demonstrations for accurate pouring. The learned pouring model is then generalized by self-supervised practicing to different conditions such as using unaccustomed pouring cups. We have evaluated the proposed approach first with one container from the training set and four new but similar containers. The proposed approach achieved better pouring accuracy than a regular human with a similar pouring speed for all five cups. Both the accuracy and pouring speed outperform state-of-the-art works. We have also evaluated the proposed self-supervised generalization approach using unaccustomed containers that are far different from the ones in the training set. The self-supervised generalization reduces the pouring error of the unaccustomed containers to the desired accuracy level.
VGG Fine-tuning for Cooking State Recognition
May 13, 2019

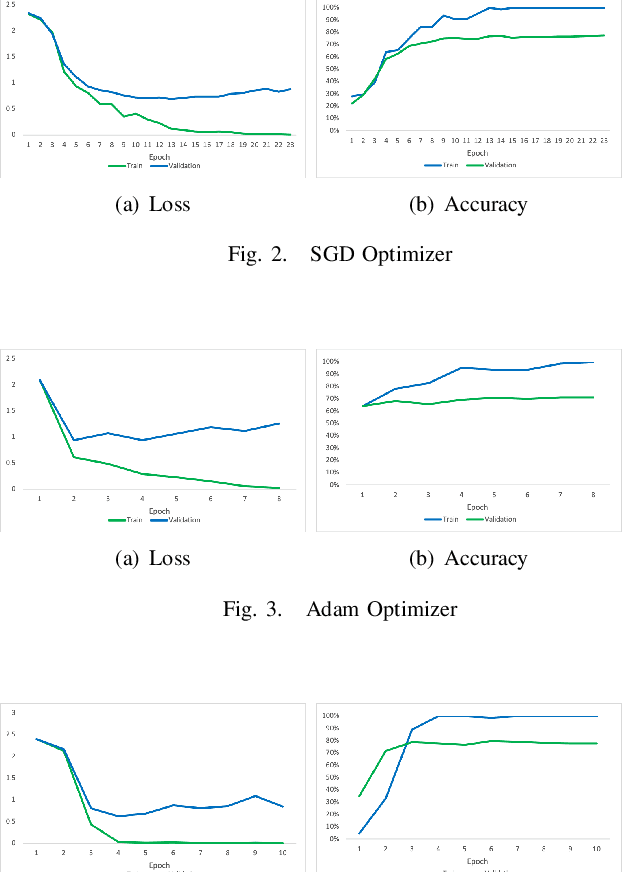
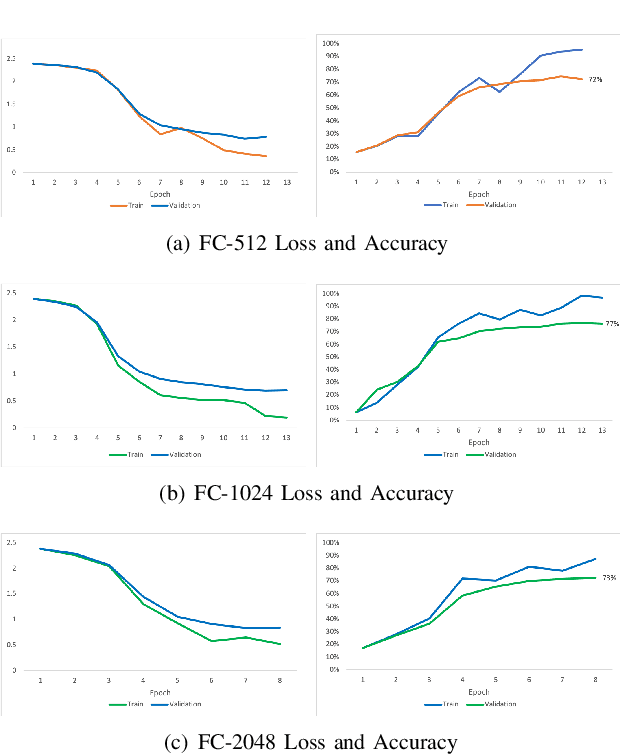
An important task that domestic robots need to achieve is the recognition of states of food ingredients so they can continue their cooking actions. This project focuses on a fine-tuning algorithm for the VGG (Visual Geometry Group) architecture of deep convolutional neural networks (CNN) for object recognition. The algorithm aims to identify eleven different ingredient cooking states for an image dataset. The original VGG model was adjusted and trained to properly classify the food states. The model was initialized with Imagenet weights. Different experiments were carried out in order to find the model parameters that provided the best performance. The accuracy achieved for the validation set was 76.7% and for the test set 76.6% after changing several parameters of the VGG model.