 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA physics-informed foundation model for quantitative diffusion MRI
May 29, 2026Understanding the human brain requires access to its microscopic tissue architecture. Diffusion magnetic resonance imaging (MRI) provides the only noninvasive window into whole-brain microstructure in vivo, yet reliable quantitative mapping remains confined to specialized research settings requiring dense sampling and optimized acquisition protocols. To address this gap, we present a physics-informed generative microstructure network (PIGMENT) that learns a universal generative prior of human brain microstructure and adapts it zero-shot to each participant's measured data to recover subject-specific maps. Trained on 11375 scans spanning multiple sites, vendors, and field strengths, PIGMENT enabled reliable quantitative mapping for tensor, kurtosis, and NODDI models across external datasets from five independent centers. It remains effective where conventional fitting becomes unreliable, recovering meaningful maps from extremely sparse acquisitions while supporting downstream tractography and structural connectivity mapping. PIGMENT estimates demonstrated strong biological validity, preserving submillimeter cortical microarchitectural patterns and early-childhood white matter developmental trajectories from 10-fold accelerated scans. Furthermore, PIGMENT enables reliable quantitative tensor mapping on cost-efficient low-field systems and the extraction of tumor-related biomarkers using ultra-fast clinical protocols. Together, these results establish PIGMENT as a physics-informed foundation model that extends quantitative diffusion MRI into regimes traditionally too sparse, heterogeneous, or clinically constrained for reliable analysis.
IDOL-Net: An Interactive Dual-Domain Parallel Network for CT Metal Artifact Reduction
Apr 03, 2021
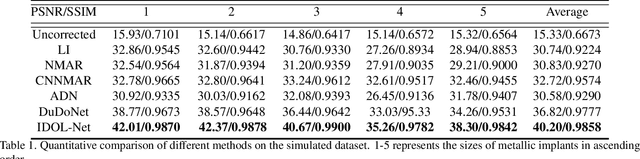
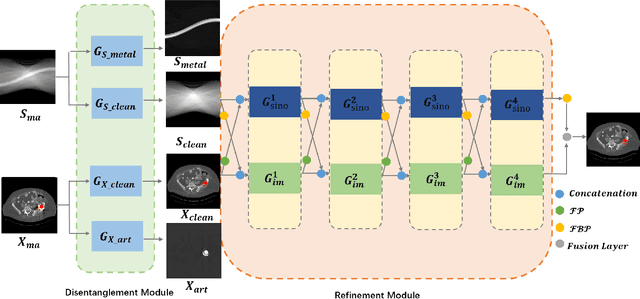

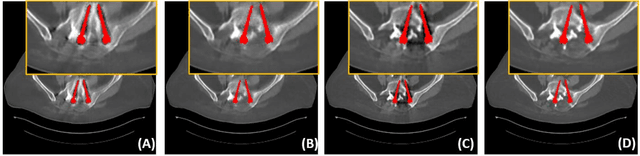
Due to the presence of metallic implants, the imaging quality of computed tomography (CT) would be heavily degraded. With the rapid development of deep learning, several network models have been proposed for metal artifact reduction (MAR). Since the dual-domain MAR methods can leverage the hybrid information from both sinogram and image domains, they have significantly improved the performance compared to single-domain methods. However,current dual-domain methods usually operate on both domains in a specific order, which implicitly imposes a certain priority prior into MAR and may ignore the latent information interaction between both domains. To address this problem, in this paper, we propose a novel interactive dualdomain parallel network for CT MAR, dubbed as IDOLNet. Different from existing dual-domain methods, the proposed IDOL-Net is composed of two modules. The disentanglement module is utilized to generate high-quality prior sinogram and image as the complementary inputs. The follow-up refinement module consists of two parallel and interactive branches that simultaneously operate on image and sinogram domain, fully exploiting the latent information interaction between both domains. The simulated and clinical results demonstrate that the proposed IDOL-Net outperforms several state-of-the-art models in both qualitative and quantitative aspects.
DAN-Net: Dual-Domain Adaptive-Scaling Non-local Network for CT Metal Artifact Reduction
Feb 16, 2021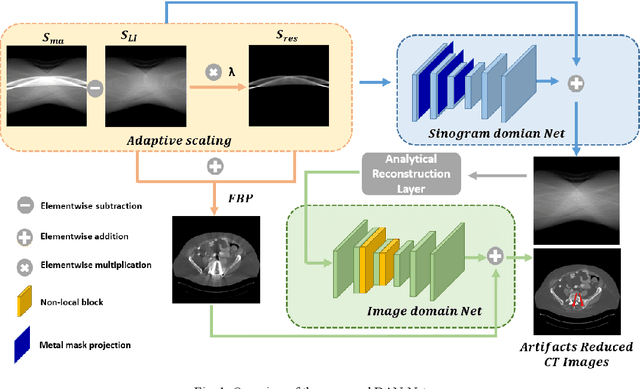
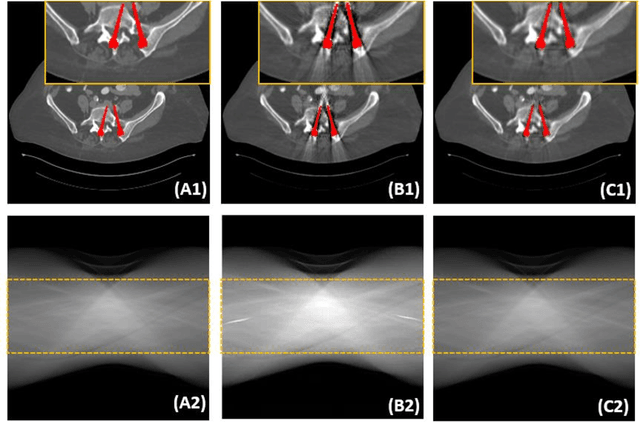
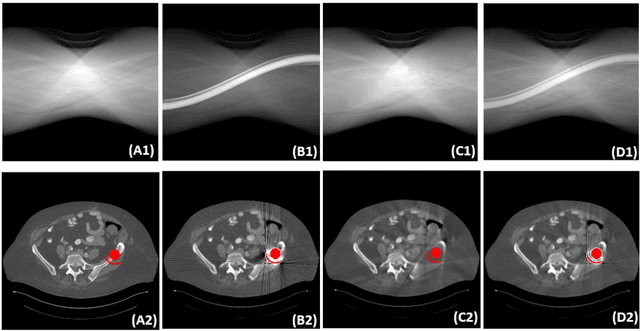
Metal implants can heavily attenuate X-rays in computed tomography (CT) scans, leading to severe artifacts in reconstructed images, which significantly jeopardize image quality and negatively impact subsequent diagnoses and treatment planning. With the rapid development of deep learning in the field of medical imaging, several network models have been proposed for metal artifact reduction (MAR) in CT. Despite the encouraging results achieved by these methods, there is still much room to further improve performance. In this paper, a novel Dual-domain Adaptive-scaling Non-local network (DAN-Net) for MAR. We correct the corrupted sinogram using adaptive scaling first to preserve more tissue and bone details as a more informative input. Then, an end-to-end dual-domain network is adopted to successively process the sinogram and its corresponding reconstructed image generated by the analytical reconstruction layer. In addition, to better suppress the existing artifacts and restrain the potential secondary artifacts caused by inaccurate results of the sinogram-domain network, a novel residual sinogram learning strategy and nonlocal module are leveraged in the proposed network model. In the experiments, the proposed DAN-Net demonstrates performance competitive with several state-of-the-art MAR methods in both qualitative and quantitative aspects.
LEARN++: Recurrent Dual-Domain Reconstruction Network for Compressed Sensing CT
Dec 13, 2020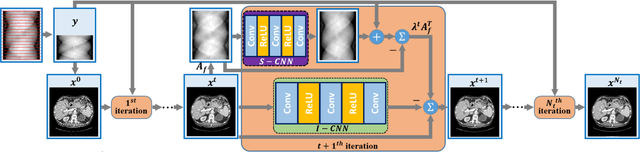

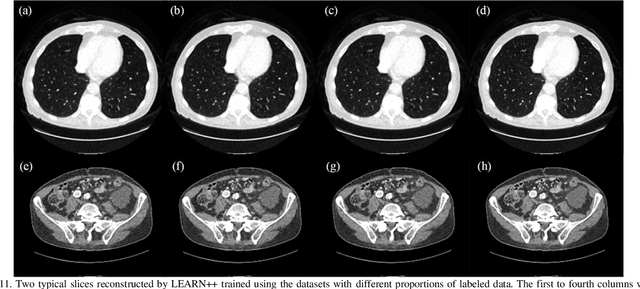

Compressed sensing (CS) computed tomography has been proven to be important for several clinical applications, such as sparse-view computed tomography (CT), digital tomosynthesis and interior tomography. Traditional compressed sensing focuses on the design of handcrafted prior regularizers, which are usually image-dependent and time-consuming. Inspired by recently proposed deep learning-based CT reconstruction models, we extend the state-of-the-art LEARN model to a dual-domain version, dubbed LEARN++. Different from existing iteration unrolling methods, which only involve projection data in the data consistency layer, the proposed LEARN++ model integrates two parallel and interactive subnetworks to perform image restoration and sinogram inpainting operations on both the image and projection domains simultaneously, which can fully explore the latent relations between projection data and reconstructed images. The experimental results demonstrate that the proposed LEARN++ model achieves competitive qualitative and quantitative results compared to several state-of-the-art methods in terms of both artifact reduction and detail preservation.
Convolutional Sparse Coding for Compressed Sensing CT Reconstruction
Mar 20, 2019


Over the past few years, dictionary learning (DL)-based methods have been successfully used in various image reconstruction problems. However, traditional DL-based computed tomography (CT) reconstruction methods are patch-based and ignore the consistency of pixels in overlapped patches. In addition, the features learned by these methods always contain shifted versions of the same features. In recent years, convolutional sparse coding (CSC) has been developed to address these problems. In this paper, inspired by several successful applications of CSC in the field of signal processing, we explore the potential of CSC in sparse-view CT reconstruction. By directly working on the whole image, without the necessity of dividing the image into overlapped patches in DL-based methods, the proposed methods can maintain more details and avoid artifacts caused by patch aggregation. With predetermined filters, an alternating scheme is developed to optimize the objective function. Extensive experiments with simulated and real CT data were performed to validate the effectiveness of the proposed methods. Qualitative and quantitative results demonstrate that the proposed methods achieve better performance than several existing state-of-the-art methods.
Denoising of 3-D Magnetic Resonance Images Using a Residual Encoder-Decoder Wasserstein Generative Adversarial Network
Aug 12, 2018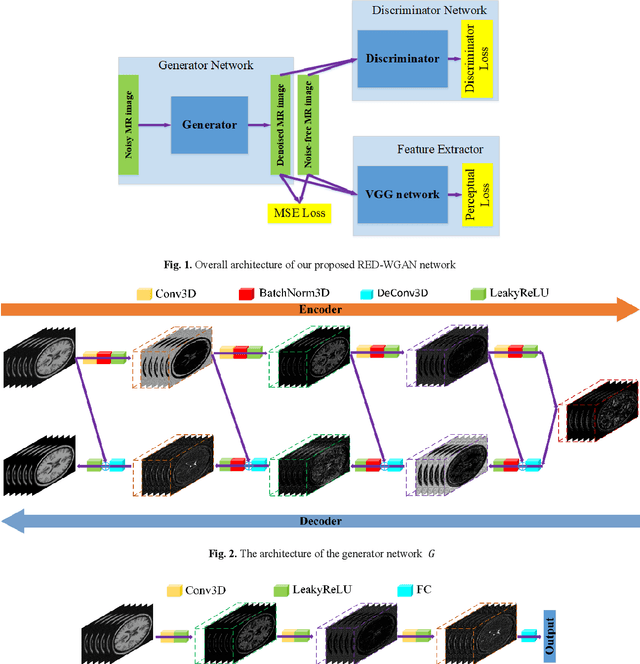
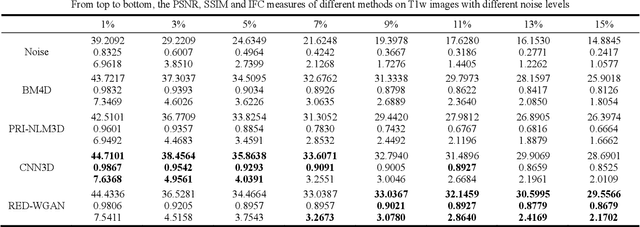
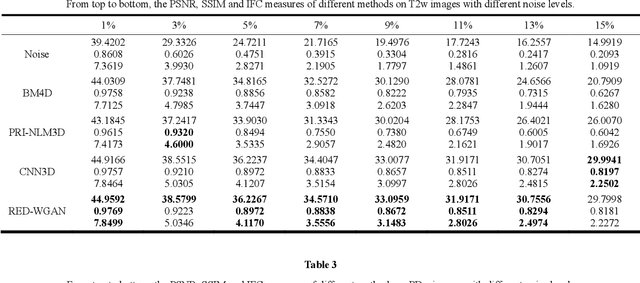
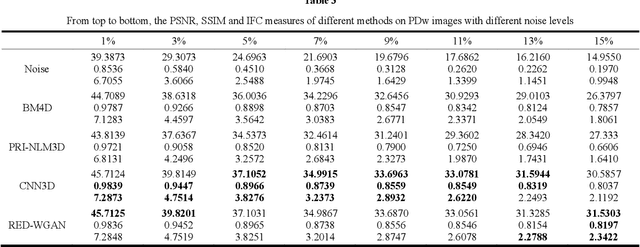
Structure-preserved denoising of 3-D magnetic resonance images (MRI) is a critical step in the medical image analysis. Over the past years, many algorithms have been proposed with impressive performances. Inspired by the idea of deep learning, in this paper, we introduce a MRI denoising method based on the residual encoder-decoder Wasserstein generative adversarial network (RED-WGAN). Specifically, to explore the structure similarity among neighboring slices, 3-D configuration are utilized as the basic processing unit. Residual autoencoder, combined with deconvolution operations are introduced into the generator network. Furthermore, to alleviate the shortcoming of traditional mean-squared error (MSE) loss function for over-smoothing, the perceptual similarity, which is implemented by calculating the distances in the feature space extracted by a pre-trained VGG-19 network, is incorporated with MSE and adversarial losses to form the new loss function. Extensive experiments are studied to access the performance of the proposed method. The experimental results show that the proposed RED-WGAN achieves superior performance relative to several state-of-art methods in both simulated and clinical data. Especially, our method demonstrates powerful ability in both noise suppression and structure preservation.