 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Efficiency and Restoration: Lightweight Mamba-Based Model for CT Metal Artifact Reduction
Apr 08, 2026In computed tomography imaging, metal implants frequently generate severe artifacts that compromise image quality and hinder diagnostic accuracy. There are three main challenges in the existing methods: the deterioration of organ and tissue structures, dependence on sinogram data, and an imbalance between resource use and restoration efficiency. Addressing these issues, we introduce MARMamba, which effectively eliminates artifacts caused by metals of different sizes while maintaining the integrity of the original anatomical structures of the image. Furthermore, this model only focuses on CT images affected by metal artifacts, thus negating the requirement for additional input data. The model is a streamlined UNet architecture, which incorporates multi-scale Mamba (MS-Mamba) as its core module. Within MS-Mamba, a flip mamba block captures comprehensive contextual information by analyzing images from multiple orientations. Subsequently, the average maximum feed-forward network integrates critical features with average features to suppress the artifacts. This combination allows MARMamba to reduce artifacts efficiently. The experimental results demonstrate that our model excels in reducing metal artifacts, offering distinct advantages over other models. It also strikes an optimal balance between computational demands, memory usage, and the number of parameters, highlighting its practical utility in the real world. The code of the presented model is available at: https://github.com/RICKand-MORTY/MARMamba.
TC-KANRecon: High-Quality and Accelerated MRI Reconstruction via Adaptive KAN Mechanisms and Intelligent Feature Scaling
Aug 11, 2024



Magnetic Resonance Imaging (MRI) has become essential in clinical diagnosis due to its high resolution and multiple contrast mechanisms. However, the relatively long acquisition time limits its broader application. To address this issue, this study presents an innovative conditional guided diffusion model, named as TC-KANRecon, which incorporates the Multi-Free U-KAN (MF-UKAN) module and a dynamic clipping strategy. TC-KANRecon model aims to accelerate the MRI reconstruction process through deep learning methods while maintaining the quality of the reconstructed images. The MF-UKAN module can effectively balance the tradeoff between image denoising and structure preservation. Specifically, it presents the multi-head attention mechanisms and scalar modulation factors, which significantly enhances the model's robustness and structure preservation capabilities in complex noise environments. Moreover, the dynamic clipping strategy in TC-KANRecon adjusts the cropping interval according to the sampling steps, thereby mitigating image detail loss typically caused by traditional cropping methods and enriching the visual features of the images. Furthermore, the MC-Model module incorporates full-sampling k-space information, realizing efficient fusion of conditional information, enhancing the model's ability to process complex data, and improving the realism and detail richness of reconstructed images. Experimental results demonstrate that the proposed method outperforms other MRI reconstruction methods in both qualitative and quantitative evaluations. Notably, TC-KANRecon method exhibits excellent reconstruction results when processing high-noise, low-sampling-rate MRI data. Our source code is available at https://github.com/lcbkmm/TC-KANRecon.
Generative Modeling in Sinogram Domain for Sparse-view CT Reconstruction
Nov 25, 2022


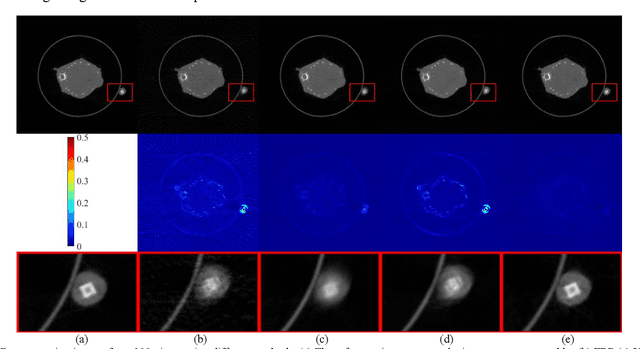
The radiation dose in computed tomography (CT) examinations is harmful for patients but can be significantly reduced by intuitively decreasing the number of projection views. Reducing projection views usually leads to severe aliasing artifacts in reconstructed images. Previous deep learning (DL) techniques with sparse-view data require sparse-view/full-view CT image pairs to train the network with supervised manners. When the number of projection view changes, the DL network should be retrained with updated sparse-view/full-view CT image pairs. To relieve this limitation, we present a fully unsupervised score-based generative model in sinogram domain for sparse-view CT reconstruction. Specifically, we first train a score-based generative model on full-view sinogram data and use multi-channel strategy to form highdimensional tensor as the network input to capture their prior distribution. Then, at the inference stage, the stochastic differential equation (SDE) solver and data-consistency step were performed iteratively to achieve fullview projection. Filtered back-projection (FBP) algorithm was used to achieve the final image reconstruction. Qualitative and quantitative studies were implemented to evaluate the presented method with several CT data. Experimental results demonstrated that our method achieved comparable or better performance than the supervised learning counterparts.
Iterative Reconstruction for Low-Dose CT using Deep Gradient Priors of Generative Model
Sep 27, 2020
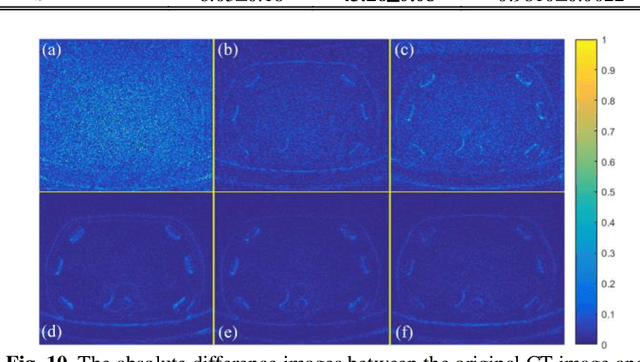
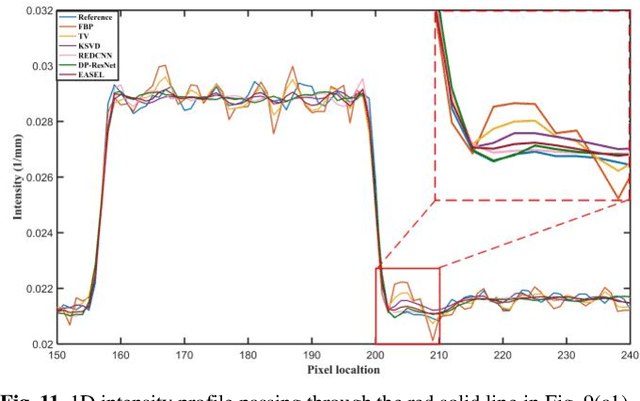
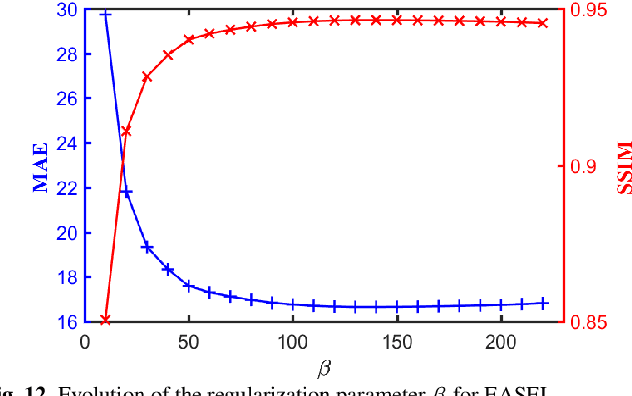
Dose reduction in computed tomography (CT) is essential for decreasing radiation risk in clinical applications. Iterative reconstruction is one of the most promising ways to compensate for the increased noise due to reduction of photon flux. Rather than most existing prior-driven algorithms that benefit from manually designed prior functions or supervised learning schemes, in this work we integrate the data-consistency as a conditional term into the iterative generative model for low-dose CT. At first, a score-based generative network is used for unsupervised distribution learning and the gradient of generative density prior is learned from normal-dose images. Then, the annealing Langevin dynamics is employed to update the trained priors with conditional scheme, i.e., the distance between the reconstructed image and the manifold is minimized along with data fidelity during reconstruction. Experimental comparisons demonstrated the noise reduction and detail preservation abilities of the proposed method.
Convolutional Sparse Coding for Compressed Sensing CT Reconstruction
Mar 20, 2019


Over the past few years, dictionary learning (DL)-based methods have been successfully used in various image reconstruction problems. However, traditional DL-based computed tomography (CT) reconstruction methods are patch-based and ignore the consistency of pixels in overlapped patches. In addition, the features learned by these methods always contain shifted versions of the same features. In recent years, convolutional sparse coding (CSC) has been developed to address these problems. In this paper, inspired by several successful applications of CSC in the field of signal processing, we explore the potential of CSC in sparse-view CT reconstruction. By directly working on the whole image, without the necessity of dividing the image into overlapped patches in DL-based methods, the proposed methods can maintain more details and avoid artifacts caused by patch aggregation. With predetermined filters, an alternating scheme is developed to optimize the objective function. Extensive experiments with simulated and real CT data were performed to validate the effectiveness of the proposed methods. Qualitative and quantitative results demonstrate that the proposed methods achieve better performance than several existing state-of-the-art methods.