 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-constrained Language-informed Diffusion Model for Unpaired Low-dose Computed Tomography Angiography Reconstruction
Jan 28, 2026The application of iodinated contrast media (ICM) improves the sensitivity and specificity of computed tomography (CT) for a wide range of clinical indications. However, overdose of ICM can cause problems such as kidney damage and life-threatening allergic reactions. Deep learning methods can generate CT images of normal-dose ICM from low-dose ICM, reducing the required dose while maintaining diagnostic power. However, existing methods are difficult to realize accurate enhancement with incompletely paired images, mainly because of the limited ability of the model to recognize specific structures. To overcome this limitation, we propose a Structure-constrained Language-informed Diffusion Model (SLDM), a unified medical generation model that integrates structural synergy and spatial intelligence. First, the structural prior information of the image is effectively extracted to constrain the model inference process, thus ensuring structural consistency in the enhancement process. Subsequently, semantic supervision strategy with spatial intelligence is introduced, which integrates the functions of visual perception and spatial reasoning, thus prompting the model to achieve accurate enhancement. Finally, the subtraction angiography enhancement module is applied, which serves to improve the contrast of the ICM agent region to suitable interval for observation. Qualitative analysis of visual comparison and quantitative results of several metrics demonstrate the effectiveness of our method in angiographic reconstruction for low-dose contrast medium CT angiography.
Iterative Diffusion-Refined Neural Attenuation Fields for Multi-Source Stationary CT Reconstruction: NAF Meets Diffusion Model
Nov 18, 2025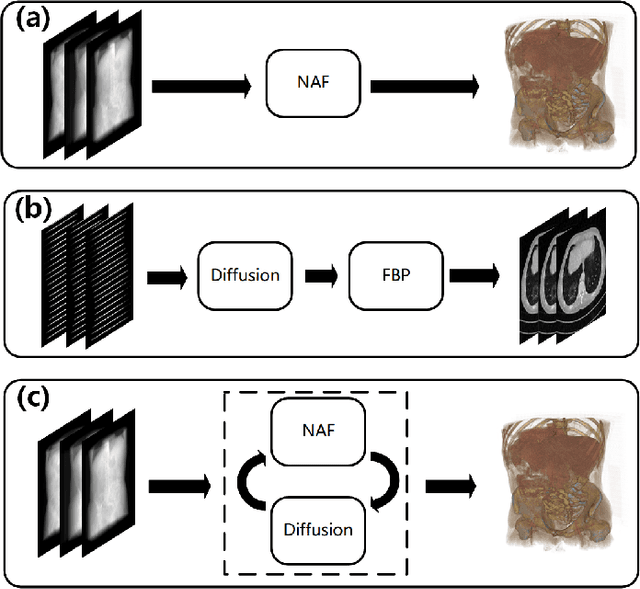
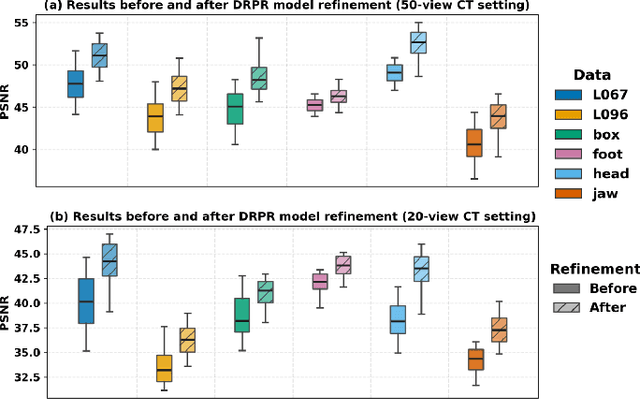
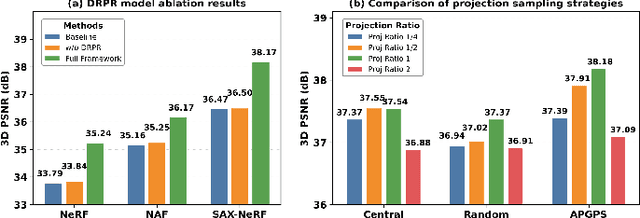
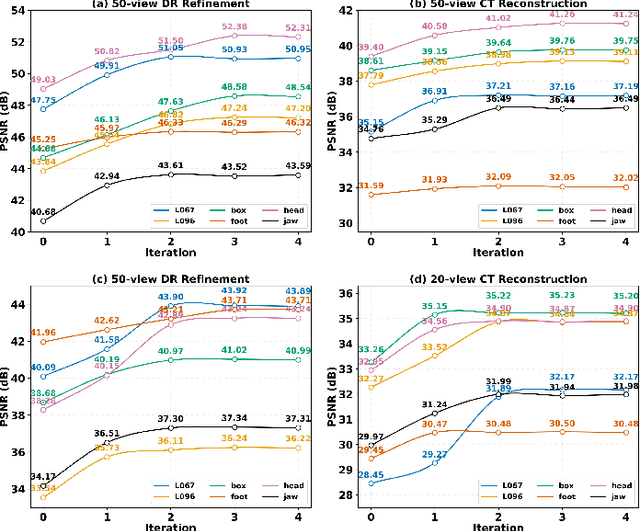
Multi-source stationary computed tomography (CT) has recently attracted attention for its ability to achieve rapid image reconstruction, making it suitable for time-sensitive clinical and industrial applications. However, practical systems are often constrained by ultra-sparse-view sampling, which significantly degrades reconstruction quality. Traditional methods struggle under ultra-sparse-view settings, where interpolation becomes inaccurate and the resulting reconstructions are unsatisfactory. To address this challenge, this study proposes Diffusion-Refined Neural Attenuation Fields (Diff-NAF), an iterative framework tailored for multi-source stationary CT under ultra-sparse-view conditions. Diff-NAF combines a Neural Attenuation Field representation with a dual-branch conditional diffusion model. The process begins by training an initial NAF using ultra-sparse-view projections. New projections are then generated through an Angle-Prior Guided Projection Synthesis strategy that exploits inter view priors, and are subsequently refined by a Diffusion-driven Reuse Projection Refinement Module. The refined projections are incorporated as pseudo-labels into the training set for the next iteration. Through iterative refinement, Diff-NAF progressively enhances projection completeness and reconstruction fidelity under ultra-sparse-view conditions, ultimately yielding high-quality CT reconstructions. Experimental results on multiple simulated 3D CT volumes and real projection data demonstrate that Diff-NAF achieves the best performance under ultra-sparse-view conditions.
Ordered-subsets Multi-diffusion Model for Sparse-view CT Reconstruction
May 15, 2025Score-based diffusion models have shown significant promise in the field of sparse-view CT reconstruction. However, the projection dataset is large and riddled with redundancy. Consequently, applying the diffusion model to unprocessed data results in lower learning effectiveness and higher learning difficulty, frequently leading to reconstructed images that lack fine details. To address these issues, we propose the ordered-subsets multi-diffusion model (OSMM) for sparse-view CT reconstruction. The OSMM innovatively divides the CT projection data into equal subsets and employs multi-subsets diffusion model (MSDM) to learn from each subset independently. This targeted learning approach reduces complexity and enhances the reconstruction of fine details. Furthermore, the integration of one-whole diffusion model (OWDM) with complete sinogram data acts as a global information constraint, which can reduce the possibility of generating erroneous or inconsistent sinogram information. Moreover, the OSMM's unsupervised learning framework provides strong robustness and generalizability, adapting seamlessly to varying sparsity levels of CT sinograms. This ensures consistent and reliable performance across different clinical scenarios. Experimental results demonstrate that OSMM outperforms traditional diffusion models in terms of image quality and noise resilience, offering a powerful and versatile solution for advanced CT imaging in sparse-view scenarios.
Partitioned Hankel-based Diffusion Models for Few-shot Low-dose CT Reconstruction
May 27, 2024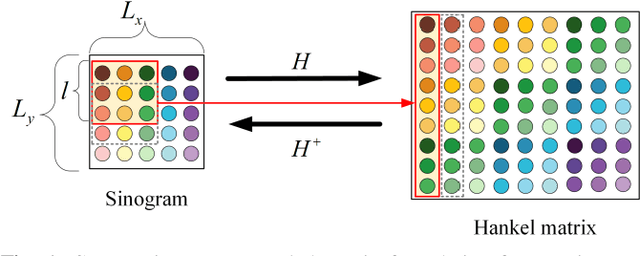

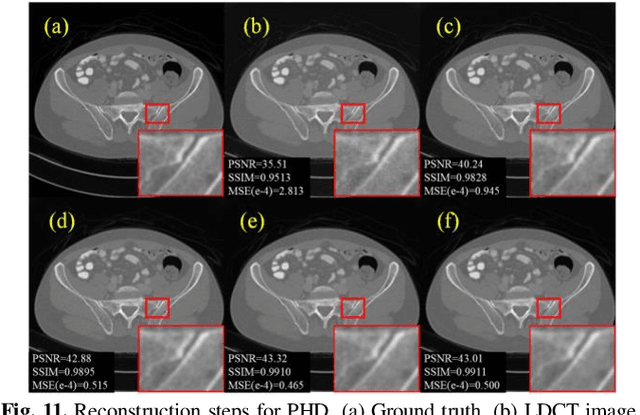
Low-dose computed tomography (LDCT) plays a vital role in clinical applications by mitigating radiation risks. Nevertheless, reducing radiation doses significantly degrades image quality. Concurrently, common deep learning methods demand extensive data, posing concerns about privacy, cost, and time constraints. Consequently, we propose a few-shot low-dose CT reconstruction method using Partitioned Hankel-based Diffusion (PHD) models. During the prior learning stage, the projection data is first transformed into multiple partitioned Hankel matrices. Structured tensors are then extracted from these matrices to facilitate prior learning through multiple diffusion models. In the iterative reconstruction stage, an iterative stochastic differential equation solver is employed along with data consistency constraints to update the acquired projection data. Furthermore, penalized weighted least-squares and total variation techniques are introduced to enhance the resulting image quality. The results approximate those of normal-dose counterparts, validating PHD model as an effective and practical model for reducing artifacts and noise while preserving image quality.
Enhancing Global Sensitivity and Uncertainty Quantification in Medical Image Reconstruction with Monte Carlo Arbitrary-Masked Mamba
May 27, 2024Deep learning has been extensively applied in medical image reconstruction, where Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) represent the predominant paradigms, each possessing distinct advantages and inherent limitations: CNNs exhibit linear complexity with local sensitivity, whereas ViTs demonstrate quadratic complexity with global sensitivity. The emerging Mamba has shown superiority in learning visual representation, which combines the advantages of linear scalability and global sensitivity. In this study, we introduce MambaMIR, an Arbitrary-Masked Mamba-based model with wavelet decomposition for joint medical image reconstruction and uncertainty estimation. A novel Arbitrary Scan Masking (ASM) mechanism ``masks out'' redundant information to introduce randomness for further uncertainty estimation. Compared to the commonly used Monte Carlo (MC) dropout, our proposed MC-ASM provides an uncertainty map without the need for hyperparameter tuning and mitigates the performance drop typically observed when applying dropout to low-level tasks. For further texture preservation and better perceptual quality, we employ the wavelet transformation into MambaMIR and explore its variant based on the Generative Adversarial Network, namely MambaMIR-GAN. Comprehensive experiments have been conducted for multiple representative medical image reconstruction tasks, demonstrating that the proposed MambaMIR and MambaMIR-GAN outperform other baseline and state-of-the-art methods in different reconstruction tasks, where MambaMIR achieves the best reconstruction fidelity and MambaMIR-GAN has the best perceptual quality. In addition, our MC-ASM provides uncertainty maps as an additional tool for clinicians, while mitigating the typical performance drop caused by the commonly used dropout.
Data and Physics driven Deep Learning Models for Fast MRI Reconstruction: Fundamentals and Methodologies
Jan 29, 2024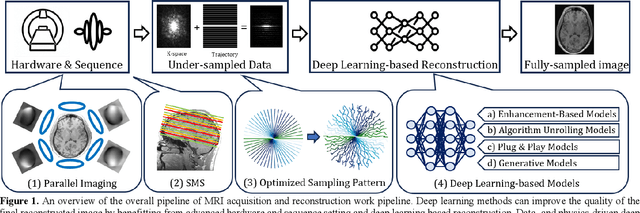


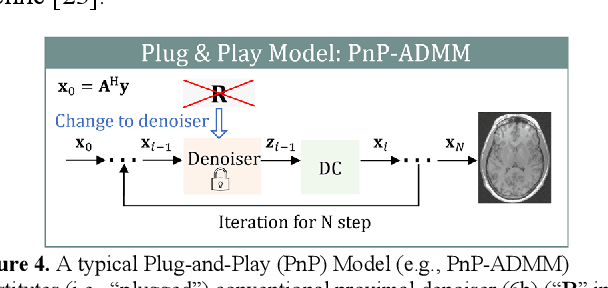
Magnetic Resonance Imaging (MRI) is a pivotal clinical diagnostic tool, yet its extended scanning times often compromise patient comfort and image quality, especially in volumetric, temporal and quantitative scans. This review elucidates recent advances in MRI acceleration via data and physics-driven models, leveraging techniques from algorithm unrolling models, enhancement-based models, and plug-and-play models to emergent full spectrum of generative models. We also explore the synergistic integration of data models with physics-based insights, encompassing the advancements in multi-coil hardware accelerations like parallel imaging and simultaneous multi-slice imaging, and the optimization of sampling patterns. We then focus on domain-specific challenges and opportunities, including image redundancy exploitation, image integrity, evaluation metrics, data heterogeneity, and model generalization. This work also discusses potential solutions and future research directions, emphasizing the role of data harmonization, and federated learning for further improving the general applicability and performance of these methods in MRI reconstruction.
Stage-by-stage Wavelet Optimization Refinement Diffusion Model for Sparse-View CT Reconstruction
Sep 03, 2023Diffusion models have emerged as potential tools to tackle the challenge of sparse-view CT reconstruction, displaying superior performance compared to conventional methods. Nevertheless, these prevailing diffusion models predominantly focus on the sinogram or image domains, which can lead to instability during model training, potentially culminating in convergence towards local minimal solutions. The wavelet trans-form serves to disentangle image contents and features into distinct frequency-component bands at varying scales, adeptly capturing diverse directional structures. Employing the Wavelet transform as a guiding sparsity prior significantly enhances the robustness of diffusion models. In this study, we present an innovative approach named the Stage-by-stage Wavelet Optimization Refinement Diffusion (SWORD) model for sparse-view CT reconstruction. Specifically, we establish a unified mathematical model integrating low-frequency and high-frequency generative models, achieving the solution with optimization procedure. Furthermore, we perform the low-frequency and high-frequency generative models on wavelet's decomposed components rather than sinogram or image domains, ensuring the stability of model training. Our method rooted in established optimization theory, comprising three distinct stages, including low-frequency generation, high-frequency refinement and domain transform. Our experimental results demonstrate that the proposed method outperforms existing state-of-the-art methods both quantitatively and qualitatively.
Data-iterative Optimization Score Model for Stable Ultra-Sparse-View CT Reconstruction
Aug 28, 2023



Score-based generative models (SGMs) have gained prominence in sparse-view CT reconstruction for their precise sampling of complex distributions. In SGM-based reconstruction, data consistency in the score-based diffusion model ensures close adherence of generated samples to observed data distribution, crucial for improving image quality. Shortcomings in data consistency characterization manifest in three aspects. Firstly, data from the optimization process can lead to artifacts in reconstructed images. Secondly, it often neglects that the generation model and original data constraints are independently completed, fragmenting unity. Thirdly, it predominantly focuses on constraining intermediate results in the inverse sampling process, rather than ideal real images. Thus, we propose an iterative optimization data scoring model. This paper introduces the data-iterative optimization score-based model (DOSM), integrating innovative data consistency into the Stochastic Differential Equation, a valuable constraint for ultra-sparse-view CT reconstruction. The novelty of this data consistency element lies in its sole reliance on original measurement data to confine generation outcomes, effectively balancing measurement data and generative model constraints. Additionally, we pioneer an inference strategy that traces back from current iteration results to ideal truth, enhancing reconstruction stability. We leverage conventional iteration techniques to optimize DOSM updates. Quantitative and qualitative results from 23 views of numerical and clinical cardiac datasets demonstrate DOSM's superiority over other methods. Remarkably, even with 10 views, our method achieves excellent performance.
Two-and-a-half Order Score-based Model for Solving 3D Ill-posed Inverse Problems
Aug 17, 2023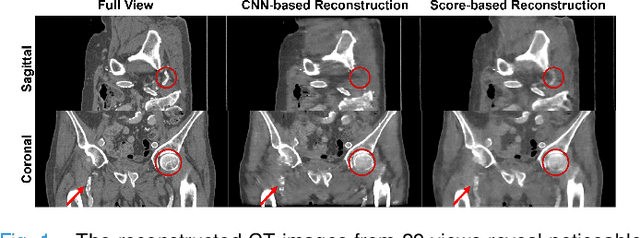

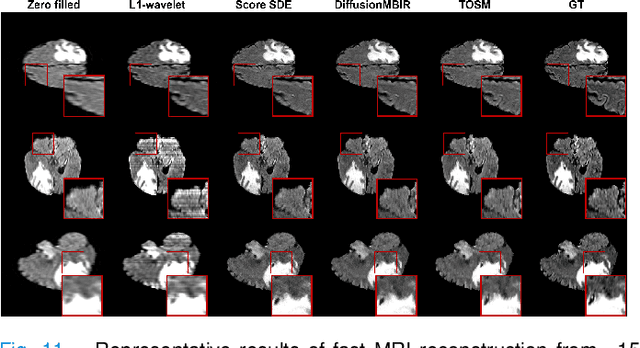

Computed Tomography (CT) and Magnetic Resonance Imaging (MRI) are crucial technologies in the field of medical imaging. Score-based models have proven to be effective in addressing different inverse problems encountered in CT and MRI, such as sparse-view CT and fast MRI reconstruction. However, these models face challenges in achieving accurate three dimensional (3D) volumetric reconstruction. The existing score-based models primarily focus on reconstructing two dimensional (2D) data distribution, leading to inconsistencies between adjacent slices in the reconstructed 3D volumetric images. To overcome this limitation, we propose a novel two-and-a-half order score-based model (TOSM). During the training phase, our TOSM learns data distributions in 2D space, which reduces the complexity of training compared to directly working on 3D volumes. However, in the reconstruction phase, the TOSM updates the data distribution in 3D space, utilizing complementary scores along three directions (sagittal, coronal, and transaxial) to achieve a more precise reconstruction. The development of TOSM is built on robust theoretical principles, ensuring its reliability and efficacy. Through extensive experimentation on large-scale sparse-view CT and fast MRI datasets, our method demonstrates remarkable advancements and attains state-of-the-art results in solving 3D ill-posed inverse problems. Notably, the proposed TOSM effectively addresses the inter-slice inconsistency issue, resulting in high-quality 3D volumetric reconstruction.
One Sample Diffusion Model in Projection Domain for Low-Dose CT Imaging
Dec 07, 2022



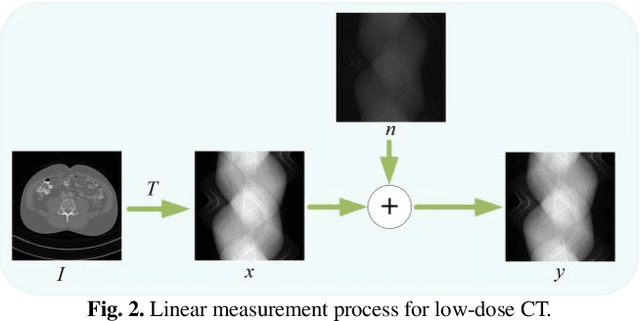
Low-dose computed tomography (CT) plays a significant role in reducing the radiation risk in clinical applications. However, lowering the radiation dose will significantly degrade the image quality. With the rapid development and wide application of deep learning, it has brought new directions for the development of low-dose CT imaging algorithms. Therefore, we propose a fully unsupervised one sample diffusion model (OSDM)in projection domain for low-dose CT reconstruction. To extract sufficient prior information from single sample, the Hankel matrix formulation is employed. Besides, the penalized weighted least-squares and total variation are introduced to achieve superior image quality. Specifically, we first train a score-based generative model on one sinogram by extracting a great number of tensors from the structural-Hankel matrix as the network input to capture prior distribution. Then, at the inference stage, the stochastic differential equation solver and data consistency step are performed iteratively to obtain the sinogram data. Finally, the final image is obtained through the filtered back-projection algorithm. The reconstructed results are approaching to the normal-dose counterparts. The results prove that OSDM is practical and effective model for reducing the artifacts and preserving the image quality.