 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Implicit Advantage Symmetry: Why GRPO Struggles with Exploration and Difficulty Adaptation
Feb 05, 2026Reinforcement Learning with Verifiable Rewards (RLVR), particularly GRPO, has become the standard for eliciting LLM reasoning. However, its efficiency in exploration and difficulty adaptation remains an open challenge. In this work, we argue that these bottlenecks stem from an implicit advantage symmetry inherent in Group Relative Advantage Estimation (GRAE). This symmetry induces two critical limitations: (i) at the group level, strict symmetry in weights between correct and incorrect trajectories leaves unsampled action logits unchanged, thereby hindering exploration of novel correct solution. (ii) at the sample level, the algorithm implicitly prioritizes medium-difficulty samples, remaining agnostic to the non-stationary demands of difficulty focus. Through controlled experiments, we reveal that this symmetric property is sub-optimal, yielding two pivotal insights: (i) asymmetrically suppressing the advantages of correct trajectories encourages essential exploration. (ii) learning efficiency is maximized by a curriculum-like transition-prioritizing simpler samples initially before gradually shifting to complex ones. Motivated by these findings, we propose Asymmetric GRAE (A-GRAE), which dynamically modulates exploration incentives and sample-difficulty focus. Experiments across seven benchmarks demonstrate that A-GRAE consistently improves GRPO and its variants across both LLMs and MLLMs.
Unsupervised Tissue Segmentation via Deep Constrained Gaussian Network
Aug 04, 2022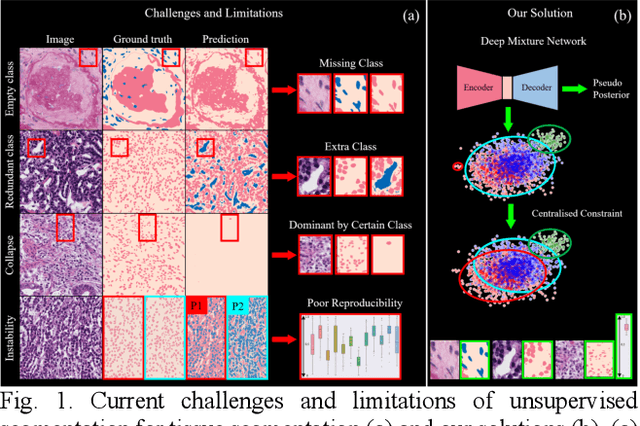
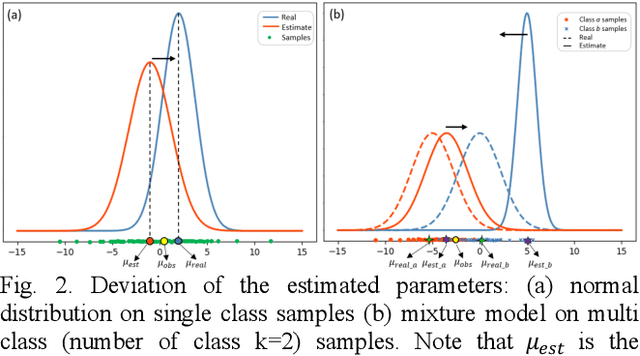
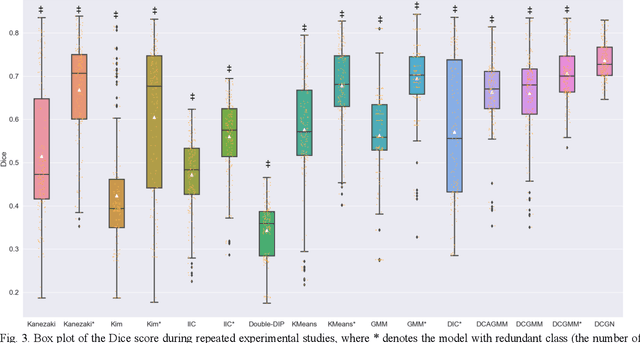
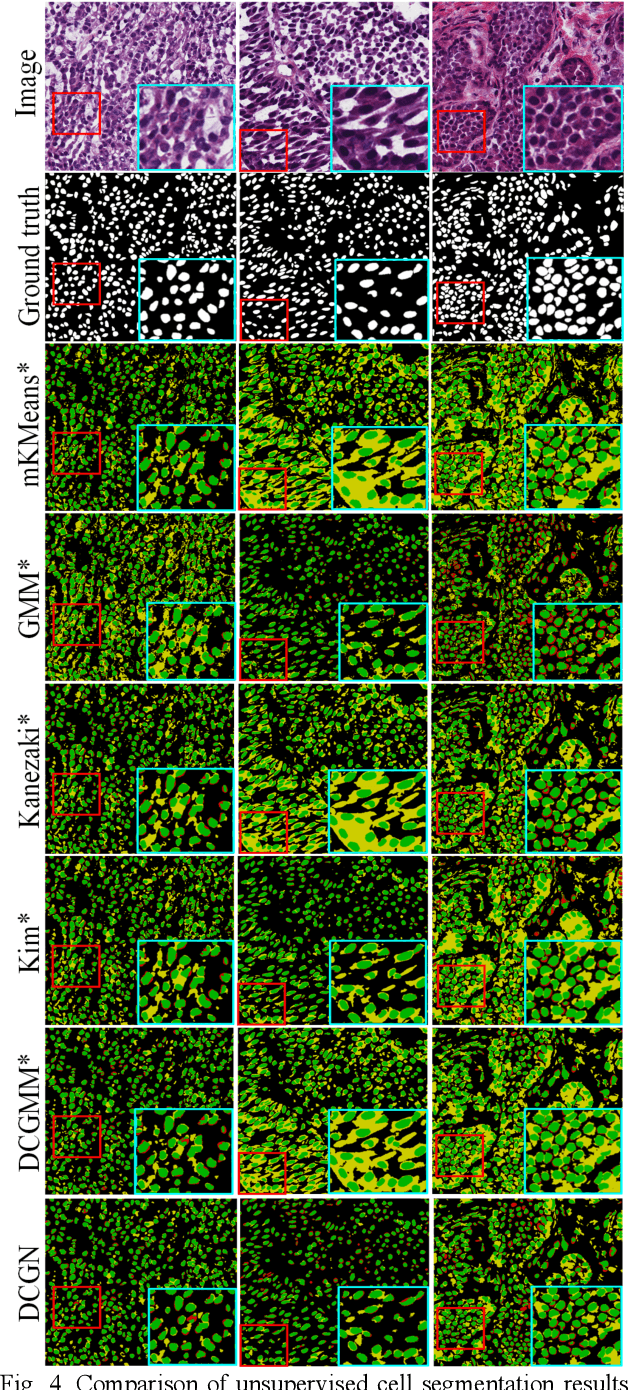
Tissue segmentation is the mainstay of pathological examination, whereas the manual delineation is unduly burdensome. To assist this time-consuming and subjective manual step, researchers have devised methods to automatically segment structures in pathological images. Recently, automated machine and deep learning based methods dominate tissue segmentation research studies. However, most machine and deep learning based approaches are supervised and developed using a large number of training samples, in which the pixelwise annotations are expensive and sometimes can be impossible to obtain. This paper introduces a novel unsupervised learning paradigm by integrating an end-to-end deep mixture model with a constrained indicator to acquire accurate semantic tissue segmentation. This constraint aims to centralise the components of deep mixture models during the calculation of the optimisation function. In so doing, the redundant or empty class issues, which are common in current unsupervised learning methods, can be greatly reduced. By validation on both public and in-house datasets, the proposed deep constrained Gaussian network achieves significantly (Wilcoxon signed-rank test) better performance (with the average Dice scores of 0.737 and 0.735, respectively) on tissue segmentation with improved stability and robustness, compared to other existing unsupervised segmentation approaches. Furthermore, the proposed method presents a similar performance (p-value > 0.05) compared to the fully supervised U-Net.
Multi-domain Integrative Swin Transformer network for Sparse-View Tomographic Reconstruction
Dec 10, 2021
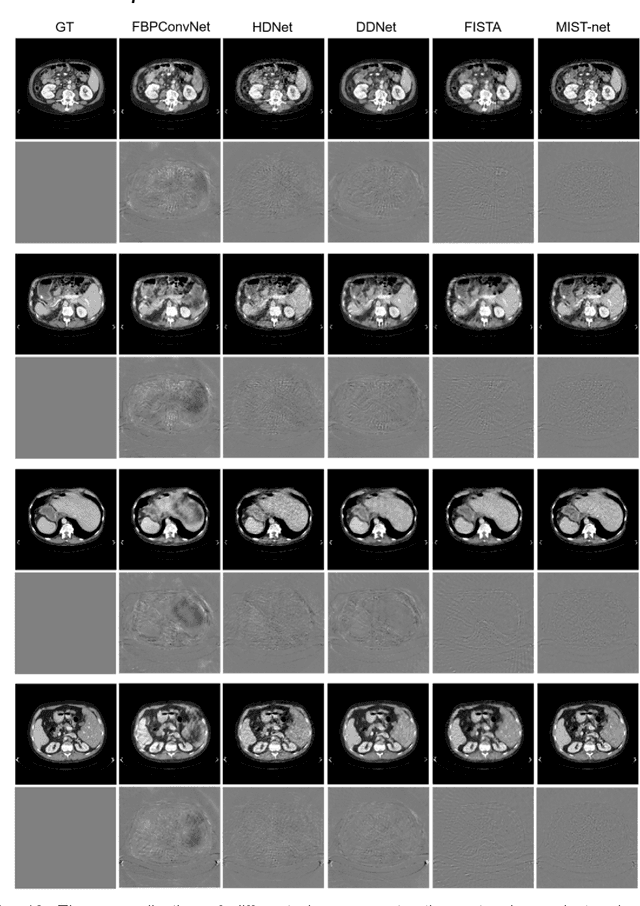
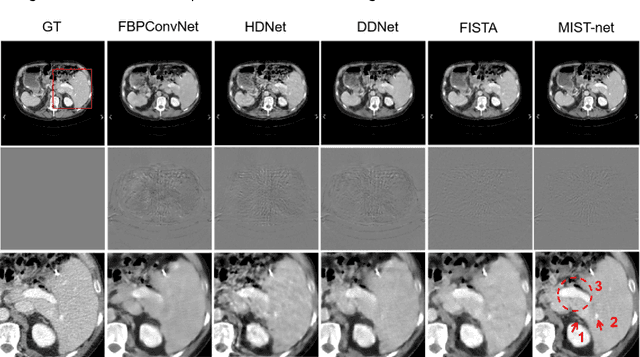
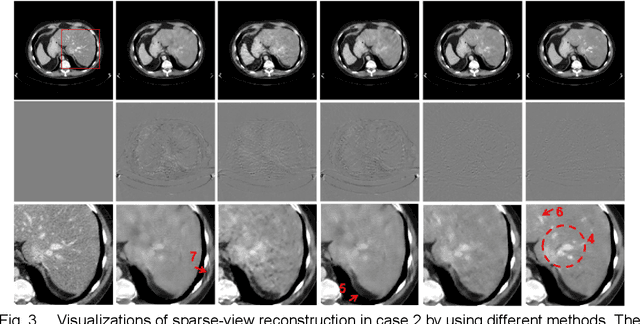
The deep learning-based tomographic image reconstruction methods have been attracting much attention among these years. The sparse-view data reconstruction is one of typical underdetermined inverse problems, how to reconstruct high-quality CT images from dozens of projections is still a challenge in practice. To address this challenge, in this article we proposed a Multi-domain Integrative Swin Transformer network (MIST-net). First, the proposed MIST-net incorporated lavish domain features from data, residual-data, image, and residual-image using flexible network architectures. Here, the residual-data and residual-image domains network components can be considered as data consistency module to eliminate interpolation errors in both residual data and image domains, and then further retain image details. Second, to detect image features and further protect image edge, the trainable edge enhancement filter was incorporated into sub-network to improve encode-decode ability. Third, with classical Swin Transformer, we further designed a high-quality reconstruction transformer (i.e., Recformer) to improve reconstruction performance. Recformer inherited the power of Swin transformer to capture global and local features of reconstructed image. The experiments on numerical datasets with 48 views demonstrated our proposed MIST-net provided higher reconstructed image quality with small feature recovery and edge protection than other competitors including advanced unrolled networks. The trained network was transferred to real cardiac CT dataset to further validate the advantages as well as good robustness of our MIST-net in clinical applications.
Adaptive Hierarchical Dual Consistency for Semi-Supervised Left Atrium Segmentation on Cross-Domain Data
Sep 20, 2021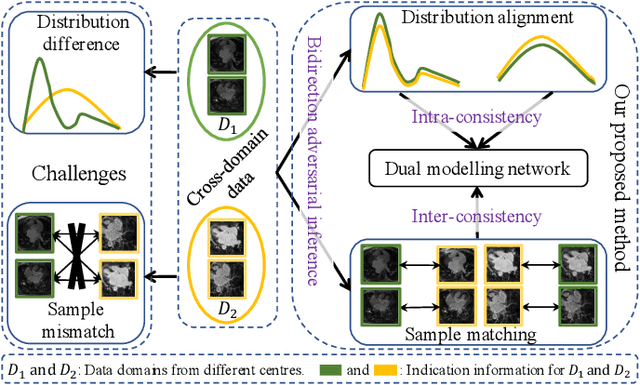
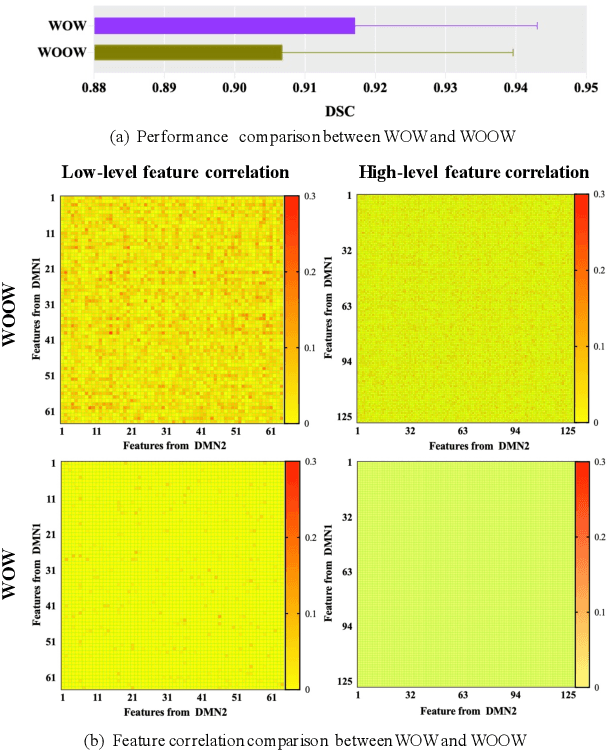
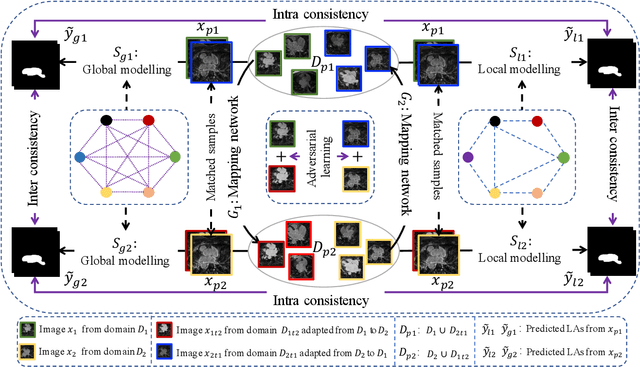
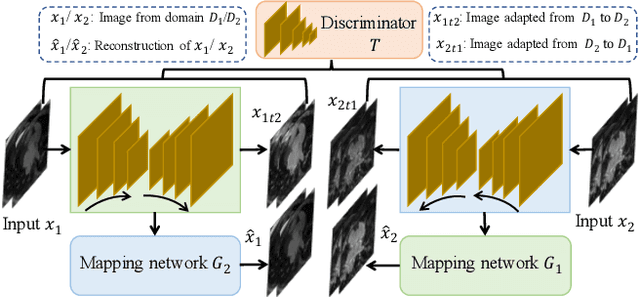
Semi-supervised learning provides great significance in left atrium (LA) segmentation model learning with insufficient labelled data. Generalising semi-supervised learning to cross-domain data is of high importance to further improve model robustness. However, the widely existing distribution difference and sample mismatch between different data domains hinder the generalisation of semi-supervised learning. In this study, we alleviate these problems by proposing an Adaptive Hierarchical Dual Consistency (AHDC) for the semi-supervised LA segmentation on cross-domain data. The AHDC mainly consists of a Bidirectional Adversarial Inference module (BAI) and a Hierarchical Dual Consistency learning module (HDC). The BAI overcomes the difference of distributions and the sample mismatch between two different domains. It mainly learns two mapping networks adversarially to obtain two matched domains through mutual adaptation. The HDC investigates a hierarchical dual learning paradigm for cross-domain semi-supervised segmentation based on the obtained matched domains. It mainly builds two dual-modelling networks for mining the complementary information in both intra-domain and inter-domain. For the intra-domain learning, a consistency constraint is applied to the dual-modelling targets to exploit the complementary modelling information. For the inter-domain learning, a consistency constraint is applied to the LAs modelled by two dual-modelling networks to exploit the complementary knowledge among different data domains. We demonstrated the performance of our proposed AHDC on four 3D late gadolinium enhancement cardiac MR (LGE-CMR) datasets from different centres and a 3D CT dataset. Compared to other state-of-the-art methods, our proposed AHDC achieved higher segmentation accuracy, which indicated its capability in the cross-domain semi-supervised LA segmentation.
JAS-GAN: Generative Adversarial Network Based Joint Atrium and Scar Segmentations on Unbalanced Atrial Targets
May 01, 2021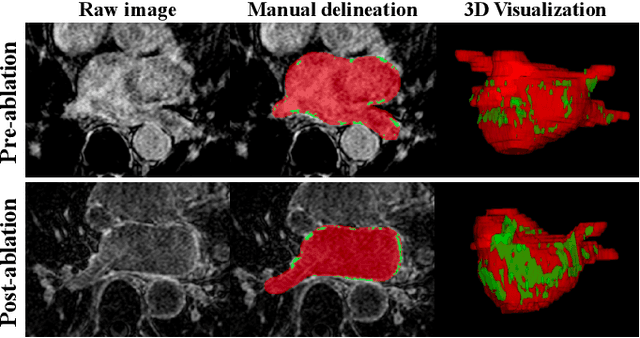
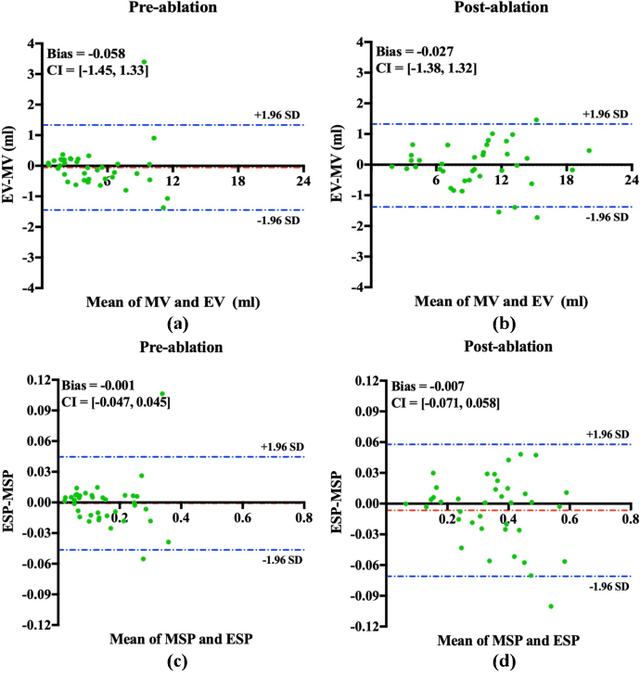
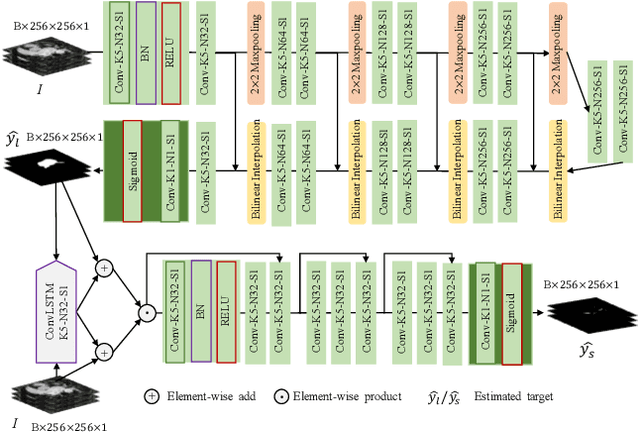
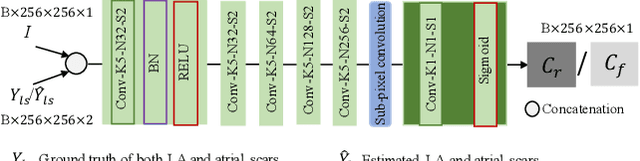
Automated and accurate segmentations of left atrium (LA) and atrial scars from late gadolinium-enhanced cardiac magnetic resonance (LGE CMR) images are in high demand for quantifying atrial scars. The previous quantification of atrial scars relies on a two-phase segmentation for LA and atrial scars due to their large volume difference (unbalanced atrial targets). In this paper, we propose an inter-cascade generative adversarial network, namely JAS-GAN, to segment the unbalanced atrial targets from LGE CMR images automatically and accurately in an end-to-end way. Firstly, JAS-GAN investigates an adaptive attention cascade to automatically correlate the segmentation tasks of the unbalanced atrial targets. The adaptive attention cascade mainly models the inclusion relationship of the two unbalanced atrial targets, where the estimated LA acts as the attention map to adaptively focus on the small atrial scars roughly. Then, an adversarial regularization is applied to the segmentation tasks of the unbalanced atrial targets for making a consistent optimization. It mainly forces the estimated joint distribution of LA and atrial scars to match the real ones. We evaluated the performance of our JAS-GAN on a 3D LGE CMR dataset with 192 scans. Compared with the state-of-the-art methods, our proposed approach yielded better segmentation performance (Average Dice Similarity Coefficient (DSC) values of 0.946 and 0.821 for LA and atrial scars, respectively), which indicated the effectiveness of our proposed approach for segmenting unbalanced atrial targets.
Annealing Genetic GAN for Minority Oversampling
Aug 05, 2020



The key to overcome class imbalance problems is to capture the distribution of minority class accurately. Generative Adversarial Networks (GANs) have shown some potentials to tackle class imbalance problems due to their capability of reproducing data distributions given ample training data samples. However, the scarce samples of one or more classes still pose a great challenge for GANs to learn accurate distributions for the minority classes. In this work, we propose an Annealing Genetic GAN (AGGAN) method, which aims to reproduce the distributions closest to the ones of the minority classes using only limited data samples. Our AGGAN renovates the training of GANs as an evolutionary process that incorporates the mechanism of simulated annealing. In particular, the generator uses different training strategies to generate multiple offspring and retain the best. Then, we use the Metropolis criterion in the simulated annealing to decide whether we should update the best offspring for the generator. As the Metropolis criterion allows a certain chance to accept the worse solutions, it enables our AGGAN steering away from the local optimum. According to both theoretical analysis and experimental studies on multiple imbalanced image datasets, we prove that the proposed training strategy can enable our AGGAN to reproduce the distributions of minority classes from scarce samples and provide an effective and robust solution for the class imbalance problem.
Deep Attentive Wasserstein Generative Adversarial Networks for MRI Reconstruction with Recurrent Context-Awareness
Jun 23, 2020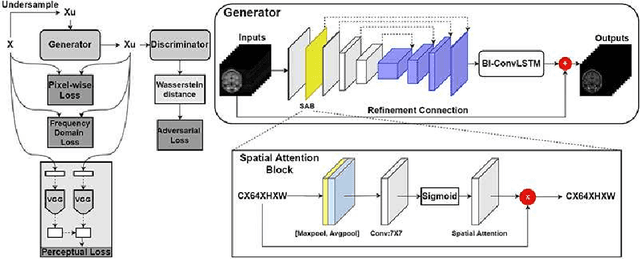
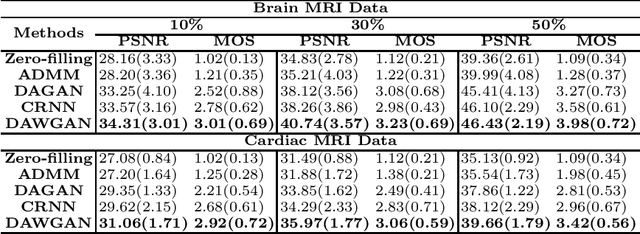
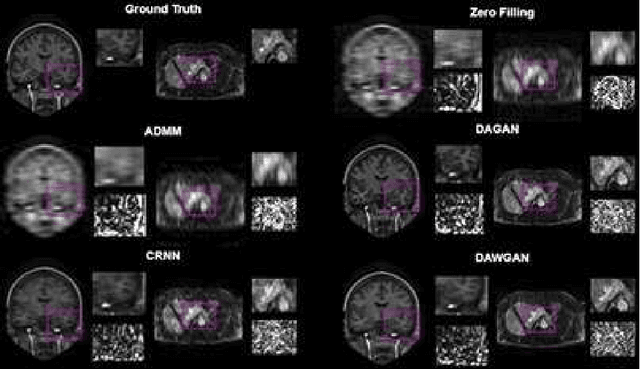

The performance of traditional compressive sensing-based MRI (CS-MRI) reconstruction is affected by its slow iterative procedure and noise-induced artefacts. Although many deep learning-based CS-MRI methods have been proposed to mitigate the problems of traditional methods, they have not been able to achieve more robust results at higher acceleration factors. Most of the deep learning-based CS-MRI methods still can not fully mine the information from the k-space, which leads to unsatisfactory results in the MRI reconstruction. In this study, we propose a new deep learning-based CS-MRI reconstruction method to fully utilise the relationship among sequential MRI slices by coupling Wasserstein Generative Adversarial Networks (WGAN) with Recurrent Neural Networks. Further development of an attentive unit enables our model to reconstruct more accurate anatomical structures for the MRI data. By experimenting on different MRI datasets, we have demonstrated that our method can not only achieve better results compared to the state-of-the-arts but can also effectively reduce residual noise generated during the reconstruction process.
Simultaneous Left Atrium Anatomy and Scar Segmentations via Deep Learning in Multiview Information with Attention
Feb 02, 2020
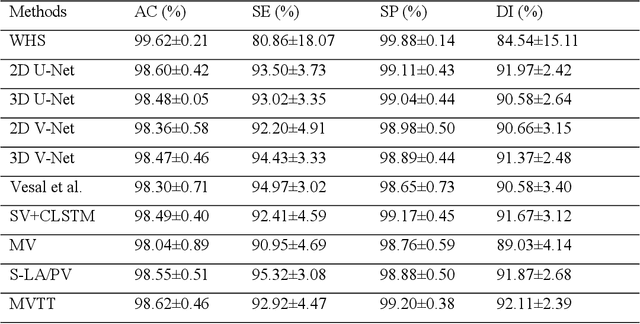

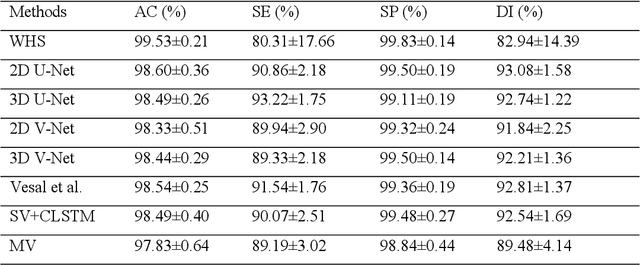
Three-dimensional late gadolinium enhanced (LGE) cardiac MR (CMR) of left atrial scar in patients with atrial fibrillation (AF) has recently emerged as a promising technique to stratify patients, to guide ablation therapy and to predict treatment success. This requires a segmentation of the high intensity scar tissue and also a segmentation of the left atrium (LA) anatomy, the latter usually being derived from a separate bright-blood acquisition. Performing both segmentations automatically from a single 3D LGE CMR acquisition would eliminate the need for an additional acquisition and avoid subsequent registration issues. In this paper, we propose a joint segmentation method based on multiview two-task (MVTT) recursive attention model working directly on 3D LGE CMR images to segment the LA (and proximal pulmonary veins) and to delineate the scar on the same dataset. Using our MVTT recursive attention model, both the LA anatomy and scar can be segmented accurately (mean Dice score of 93% for the LA anatomy and 87% for the scar segmentations) and efficiently (~0.27 seconds to simultaneously segment the LA anatomy and scars directly from the 3D LGE CMR dataset with 60-68 2D slices). Compared to conventional unsupervised learning and other state-of-the-art deep learning based methods, the proposed MVTT model achieved excellent results, leading to an automatic generation of a patient-specific anatomical model combined with scar segmentation for patients in AF.
Direct Quantification for Coronary Artery Stenosis Using Multiview Learning
Aug 02, 2019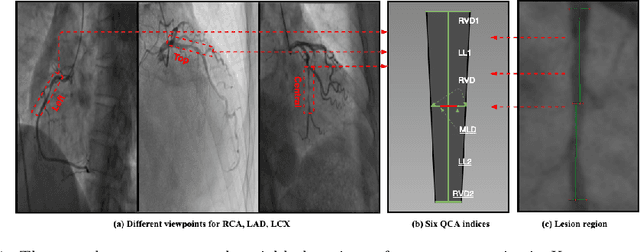
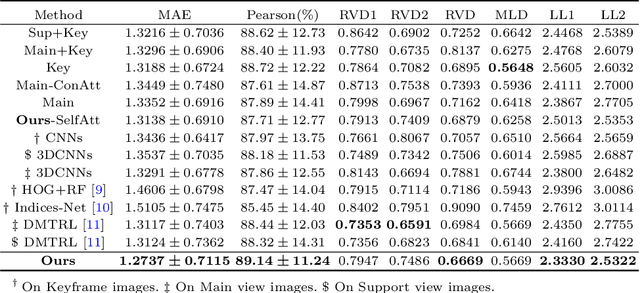
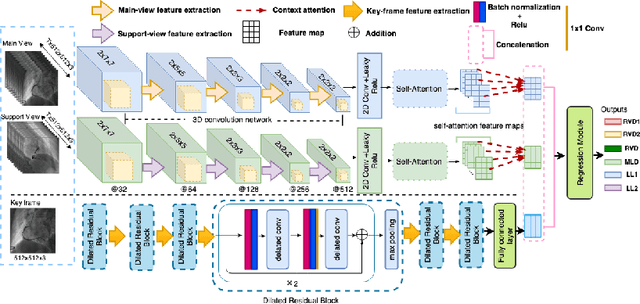
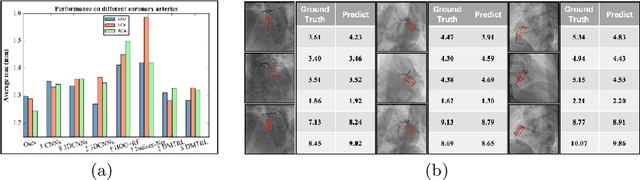
The quantification of the coronary artery stenosis is of significant clinical importance in coronary artery disease diagnosis and intervention treatment. It aims to quantify the morphological indices of the coronary artery lesions such as minimum lumen diameter, reference vessel diameter, lesion length, and these indices are the reference of the interventional stent placement. In this study, we propose a direct multiview quantitative coronary angiography (DMQCA) model as an automatic clinical tool to quantify the coronary artery stenosis from X-ray coronary angiography images. The proposed DMQCA model consists of a multiview module with two attention mechanisms, a key-frame module, and a regression module, to achieve direct accurate multiple-index estimation. The multi-view module comprehensively learns the Spatio-temporal features of coronary arteries through a three-dimensional convolution. The attention mechanisms of each view focus on the subtle feature of the lesion region and capture the important context information. The key-frame module learns the subtle features of the stenosis through successive dilated residual blocks. The regression module finally generates the indices estimation from multiple features.
Recurrent Aggregation Learning for Multi-View Echocardiographic Sequences Segmentation
Jul 24, 2019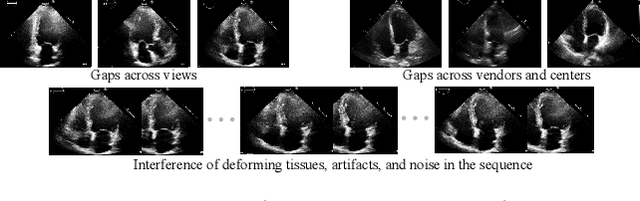



Multi-view echocardiographic sequences segmentation is crucial for clinical diagnosis. However, this task is challenging due to limited labeled data, huge noise, and large gaps across views. Here we propose a recurrent aggregation learning method to tackle this challenging task. By pyramid ConvBlocks, multi-level and multi-scale features are extracted efficiently. Hierarchical ConvLSTMs next fuse these features and capture spatial-temporal information in multi-level and multi-scale space. We further introduce a double-branch aggregation mechanism for segmentation and classification which are mutually promoted by deep aggregation of multi-level and multi-scale features. The segmentation branch provides information to guide the classification while the classification branch affords multi-view regularization to refine segmentations and further lessen gaps across views. Our method is built as an end-to-end framework for segmentation and classification. Adequate experiments on our multi-view dataset (9000 labeled images) and the CAMUS dataset (1800 labeled images) corroborate that our method achieves not only superior segmentation and classification accuracy but also prominent temporal stability.