 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSig-DEG for Distillation: Making Diffusion Models Faster and Lighter
Aug 23, 2025Diffusion models have achieved state-of-the-art results in generative modelling but remain computationally intensive at inference time, often requiring thousands of discretization steps. To this end, we propose Sig-DEG (Signature-based Differential Equation Generator), a novel generator for distilling pre-trained diffusion models, which can universally approximate the backward diffusion process at a coarse temporal resolution. Inspired by high-order approximations of stochastic differential equations (SDEs), Sig-DEG leverages partial signatures to efficiently summarize Brownian motion over sub-intervals and adopts a recurrent structure to enable accurate global approximation of the SDE solution. Distillation is formulated as a supervised learning task, where Sig-DEG is trained to match the outputs of a fine-resolution diffusion model on a coarse time grid. During inference, Sig-DEG enables fast generation, as the partial signature terms can be simulated exactly without requiring fine-grained Brownian paths. Experiments demonstrate that Sig-DEG achieves competitive generation quality while reducing the number of inference steps by an order of magnitude. Our results highlight the effectiveness of signature-based approximations for efficient generative modeling.
SPDEBench: An Extensive Benchmark for Learning Regular and Singular Stochastic PDEs
May 24, 2025Stochastic Partial Differential Equations (SPDEs) driven by random noise play a central role in modelling physical processes whose spatio-temporal dynamics can be rough, such as turbulence flows, superconductors, and quantum dynamics. To efficiently model these processes and make predictions, machine learning (ML)-based surrogate models are proposed, with their network architectures incorporating the spatio-temporal roughness in their design. However, it lacks an extensive and unified datasets for SPDE learning; especially, existing datasets do not account for the computational error introduced by noise sampling and the necessary renormalization required for handling singular SPDEs. We thus introduce SPDEBench, which is designed to solve typical SPDEs of physical significance (e.g., the $\Phi^4_d$, wave, incompressible Navier--Stokes, and KdV equations) on 1D or 2D tori driven by white noise via ML methods. New datasets for singular SPDEs based on the renormalization process have been constructed, and novel ML models achieving the best results to date have been proposed. In particular, we investigate the impact of computational error introduced by noise sampling and renormalization on the performance comparison of ML models and highlight the importance of selecting high-quality test data for accurate evaluation. Results are benchmarked with traditional numerical solvers and ML-based models, including FNO, NSPDE and DLR-Net, etc. It is shown that, for singular SPDEs, naively applying ML models on data without specifying the numerical schemes can lead to significant errors and misleading conclusions. Our SPDEBench provides an open-source codebase that ensures full reproducibility of benchmarking across a variety of SPDE datasets while offering the flexibility to incorporate new datasets and machine learning baselines, making it a valuable resource for the community.
MotionPCM: Real-Time Motion Synthesis with Phased Consistency Model
Jan 31, 2025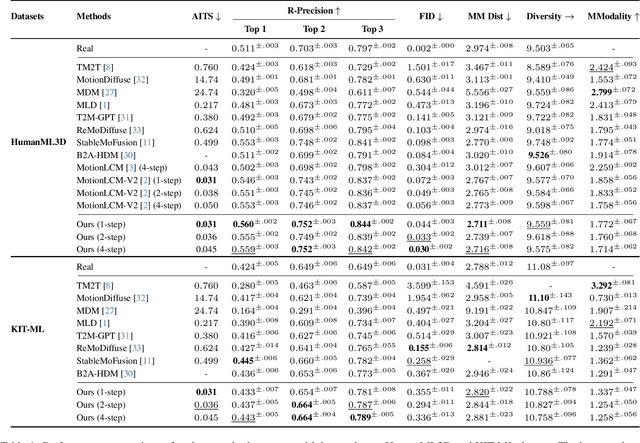

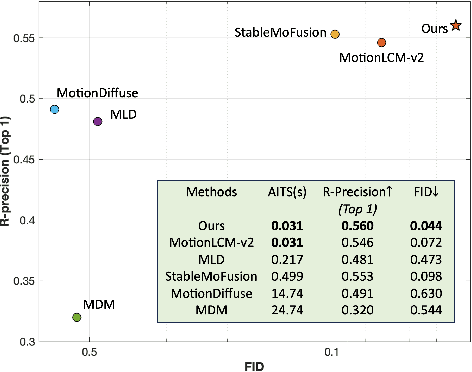
Diffusion models have become a popular choice for human motion synthesis due to their powerful generative capabilities. However, their high computational complexity and large sampling steps pose challenges for real-time applications. Fortunately, the Consistency Model (CM) provides a solution to greatly reduce the number of sampling steps from hundreds to a few, typically fewer than four, significantly accelerating the synthesis of diffusion models. However, its application to text-conditioned human motion synthesis in latent space remains challenging. In this paper, we introduce \textbf{MotionPCM}, a phased consistency model-based approach designed to improve the quality and efficiency of real-time motion synthesis in latent space.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
Using joint angles based on the international biomechanical standards for human action recognition and related tasks
Jun 25, 2024



Keypoint data has received a considerable amount of attention in machine learning for tasks like action detection and recognition. However, human experts in movement such as doctors, physiotherapists, sports scientists and coaches use a notion of joint angles standardised by the International Society of Biomechanics to precisely and efficiently communicate static body poses and movements. In this paper, we introduce the basic biomechanical notions and show how they can be used to convert common keypoint data into joint angles that uniquely describe the given pose and have various desirable mathematical properties, such as independence of both the camera viewpoint and the person performing the action. We experimentally demonstrate that the joint angle representation of keypoint data is suitable for machine learning applications and can in some cases bring an immediate performance gain. The use of joint angles as a human meaningful representation of kinematic data is in particular promising for applications where interpretability and dialog with human experts is important, such as many sports and medical applications. To facilitate further research in this direction, we will release a python package to convert keypoint data into joint angles as outlined in this paper.
MCGAN: Enhancing GAN Training with Regression-Based Generator Loss
May 27, 2024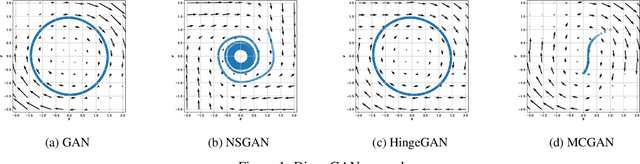

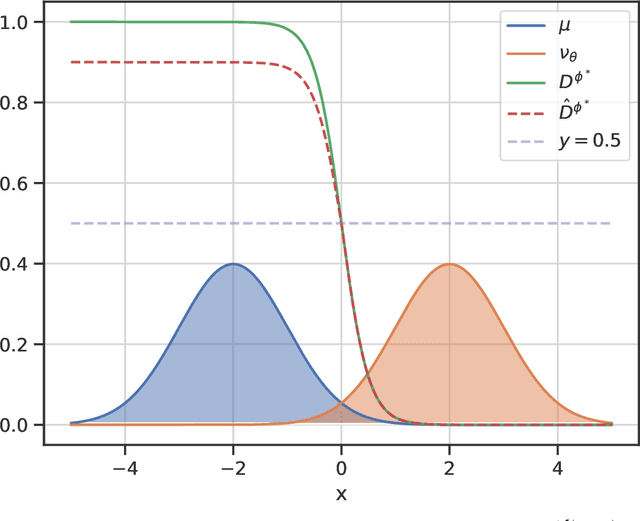
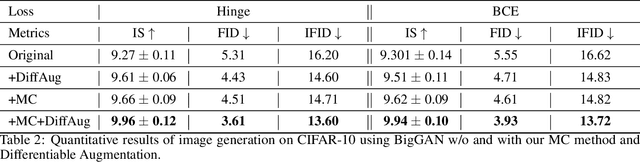
Generative adversarial networks (GANs) have emerged as a powerful tool for generating high-fidelity data. However, the main bottleneck of existing approaches is the lack of supervision on the generator training, which often results in undamped oscillation and unsatisfactory performance. To address this issue, we propose an algorithm called Monte Carlo GAN (MCGAN). This approach, utilizing an innovative generative loss function, termly the regression loss, reformulates the generator training as a regression task and enables the generator training by minimizing the mean squared error between the discriminator's output of real data and the expected discriminator of fake data. We demonstrate the desirable analytic properties of the regression loss, including discriminability and optimality, and show that our method requires a weaker condition on the discriminator for effective generator training. These properties justify the strength of this approach to improve the training stability while retaining the optimality of GAN by leveraging strong supervision of the regression loss. Numerical results on CIFAR-10 and CIFAR-100 datasets demonstrate that the proposed MCGAN significantly and consistently improves the existing state-of-the-art GAN models in terms of quality, accuracy, training stability, and learned latent space. Furthermore, the proposed algorithm exhibits great flexibility for integrating with a variety of backbone models to generate spatial images, temporal time-series, and spatio-temporal video data.
High Rank Path Development: an approach of learning the filtration of stochastic processes
May 23, 2024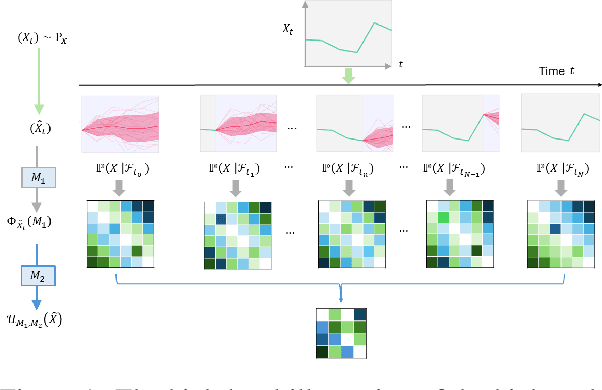
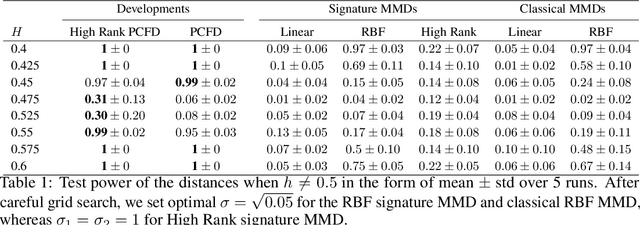
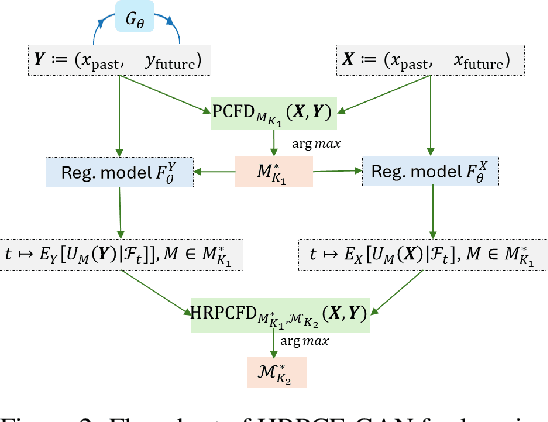
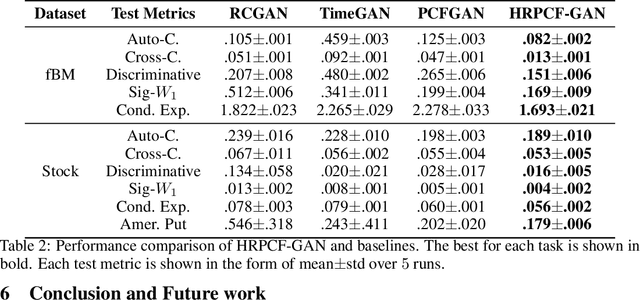
Since the weak convergence for stochastic processes does not account for the growth of information over time which is represented by the underlying filtration, a slightly erroneous stochastic model in weak topology may cause huge loss in multi-periods decision making problems. To address such discontinuities Aldous introduced the extended weak convergence, which can fully characterise all essential properties, including the filtration, of stochastic processes; however was considered to be hard to find efficient numerical implementations. In this paper, we introduce a novel metric called High Rank PCF Distance (HRPCFD) for extended weak convergence based on the high rank path development method from rough path theory, which also defines the characteristic function for measure-valued processes. We then show that such HRPCFD admits many favourable analytic properties which allows us to design an efficient algorithm for training HRPCFD from data and construct the HRPCF-GAN by using HRPCFD as the discriminator for conditional time series generation. Our numerical experiments on both hypothesis testing and generative modelling validate the out-performance of our approach compared with several state-of-the-art methods, highlighting its potential in broad applications of synthetic time series generation and in addressing classic financial and economic challenges, such as optimal stopping or utility maximisation problems.
GCN-DevLSTM: Path Development for Skeleton-Based Action Recognition
Mar 22, 2024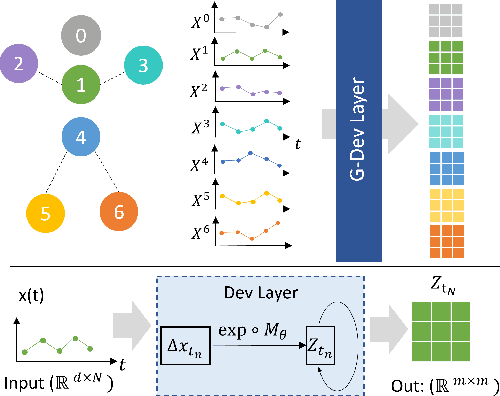
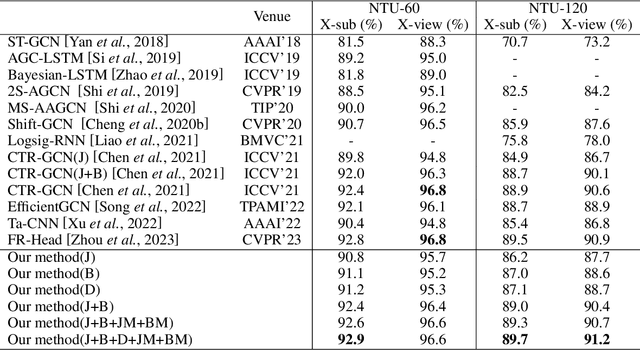
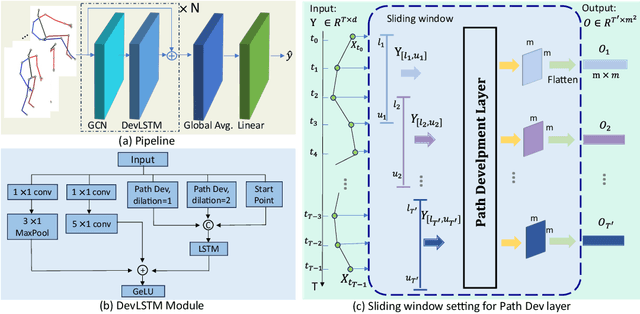

Skeleton-based action recognition (SAR) in videos is an important but challenging task in computer vision. The recent state-of-the-art models for SAR are primarily based on graph convolutional neural networks (GCNs), which are powerful in extracting the spatial information of skeleton data. However, it is yet clear that such GCN-based models can effectively capture the temporal dynamics of human action sequences. To this end, we propose the DevLSTM module, which exploits the path development -- a principled and parsimonious representation for sequential data by leveraging the Lie group structure. The path development, originated from Rough path theory, can effectively capture the order of events in high-dimensional stream data with massive dimension reduction and consequently enhance the LSTM module substantially. Our proposed G-DevLSTM module can be conveniently plugged into the temporal graph, complementing existing advanced GCN-based models. Our empirical studies on the NTU60, NTU120 and Chalearn2013 datasets demonstrate that our proposed hybrid model significantly outperforms the current best-performing methods in SAR tasks. The code is available at https://github.com/DeepIntoStreams/GCN-DevLSTM.
Part-Aware Transformer for Generalizable Person Re-identification
Aug 07, 2023Domain generalization person re-identification (DG-ReID) aims to train a model on source domains and generalize well on unseen domains. Vision Transformer usually yields better generalization ability than common CNN networks under distribution shifts. However, Transformer-based ReID models inevitably over-fit to domain-specific biases due to the supervised learning strategy on the source domain. We observe that while the global images of different IDs should have different features, their similar local parts (e.g., black backpack) are not bounded by this constraint. Motivated by this, we propose a pure Transformer model (termed Part-aware Transformer) for DG-ReID by designing a proxy task, named Cross-ID Similarity Learning (CSL), to mine local visual information shared by different IDs. This proxy task allows the model to learn generic features because it only cares about the visual similarity of the parts regardless of the ID labels, thus alleviating the side effect of domain-specific biases. Based on the local similarity obtained in CSL, a Part-guided Self-Distillation (PSD) is proposed to further improve the generalization of global features. Our method achieves state-of-the-art performance under most DG ReID settings. Under the Market$\to$Duke setting, our method exceeds state-of-the-art by 10.9% and 12.8% in Rank1 and mAP, respectively. The code is available at https://github.com/liyuke65535/Part-Aware-Transformer.
Generative Modelling of Lévy Area for High Order SDE Simulation
Aug 04, 2023It is well known that, when numerically simulating solutions to SDEs, achieving a strong convergence rate better than O(\sqrt{h}) (where h is the step size) requires the use of certain iterated integrals of Brownian motion, commonly referred to as its "L\'{e}vy areas". However, these stochastic integrals are difficult to simulate due to their non-Gaussian nature and for a d-dimensional Brownian motion with d > 2, no fast almost-exact sampling algorithm is known. In this paper, we propose L\'{e}vyGAN, a deep-learning-based model for generating approximate samples of L\'{e}vy area conditional on a Brownian increment. Due to our "Bridge-flipping" operation, the output samples match all joint and conditional odd moments exactly. Our generator employs a tailored GNN-inspired architecture, which enforces the correct dependency structure between the output distribution and the conditioning variable. Furthermore, we incorporate a mathematically principled characteristic-function based discriminator. Lastly, we introduce a novel training mechanism termed "Chen-training", which circumvents the need for expensive-to-generate training data-sets. This new training procedure is underpinned by our two main theoretical results. For 4-dimensional Brownian motion, we show that L\'{e}vyGAN exhibits state-of-the-art performance across several metrics which measure both the joint and marginal distributions. We conclude with a numerical experiment on the log-Heston model, a popular SDE in mathematical finance, demonstrating that high-quality synthetic L\'{e}vy area can lead to high order weak convergence and variance reduction when using multilevel Monte Carlo (MLMC).