 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCGAN: Enhancing GAN Training with Regression-Based Generator Loss
May 27, 2024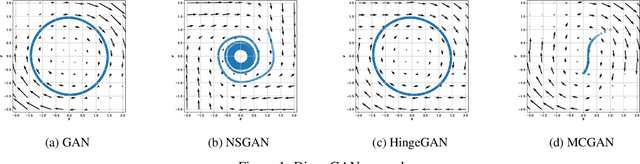

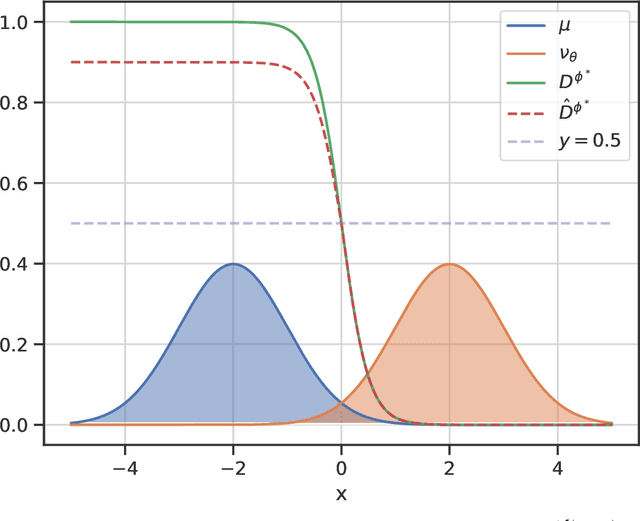
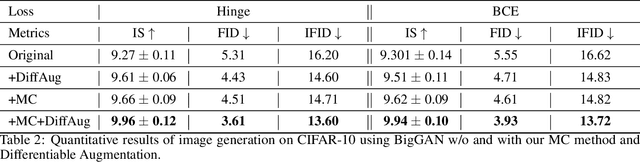
Generative adversarial networks (GANs) have emerged as a powerful tool for generating high-fidelity data. However, the main bottleneck of existing approaches is the lack of supervision on the generator training, which often results in undamped oscillation and unsatisfactory performance. To address this issue, we propose an algorithm called Monte Carlo GAN (MCGAN). This approach, utilizing an innovative generative loss function, termly the regression loss, reformulates the generator training as a regression task and enables the generator training by minimizing the mean squared error between the discriminator's output of real data and the expected discriminator of fake data. We demonstrate the desirable analytic properties of the regression loss, including discriminability and optimality, and show that our method requires a weaker condition on the discriminator for effective generator training. These properties justify the strength of this approach to improve the training stability while retaining the optimality of GAN by leveraging strong supervision of the regression loss. Numerical results on CIFAR-10 and CIFAR-100 datasets demonstrate that the proposed MCGAN significantly and consistently improves the existing state-of-the-art GAN models in terms of quality, accuracy, training stability, and learned latent space. Furthermore, the proposed algorithm exhibits great flexibility for integrating with a variety of backbone models to generate spatial images, temporal time-series, and spatio-temporal video data.
GCN-DevLSTM: Path Development for Skeleton-Based Action Recognition
Mar 22, 2024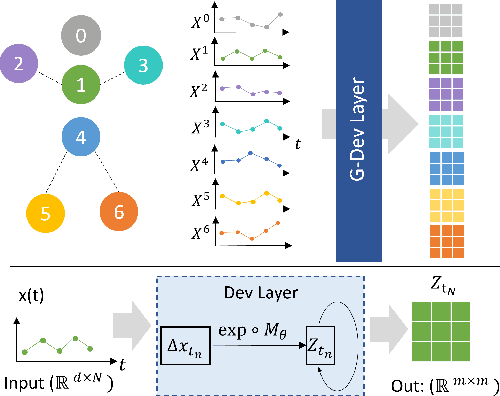
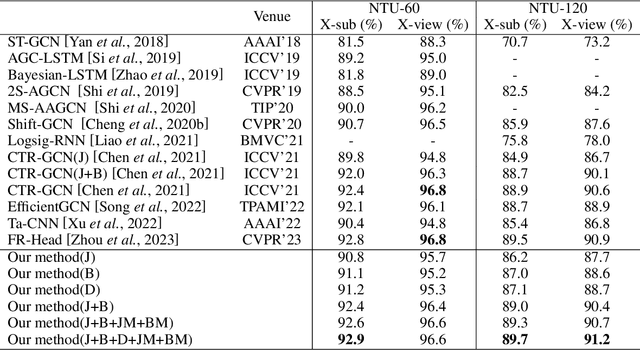
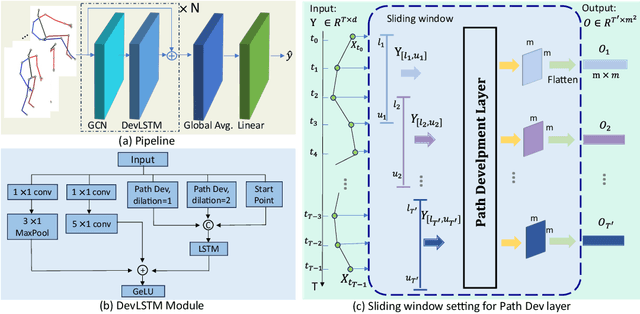

Skeleton-based action recognition (SAR) in videos is an important but challenging task in computer vision. The recent state-of-the-art models for SAR are primarily based on graph convolutional neural networks (GCNs), which are powerful in extracting the spatial information of skeleton data. However, it is yet clear that such GCN-based models can effectively capture the temporal dynamics of human action sequences. To this end, we propose the DevLSTM module, which exploits the path development -- a principled and parsimonious representation for sequential data by leveraging the Lie group structure. The path development, originated from Rough path theory, can effectively capture the order of events in high-dimensional stream data with massive dimension reduction and consequently enhance the LSTM module substantially. Our proposed G-DevLSTM module can be conveniently plugged into the temporal graph, complementing existing advanced GCN-based models. Our empirical studies on the NTU60, NTU120 and Chalearn2013 datasets demonstrate that our proposed hybrid model significantly outperforms the current best-performing methods in SAR tasks. The code is available at https://github.com/DeepIntoStreams/GCN-DevLSTM.
Logsig-RNN: a novel network for robust and efficient skeleton-based action recognition
Nov 01, 2021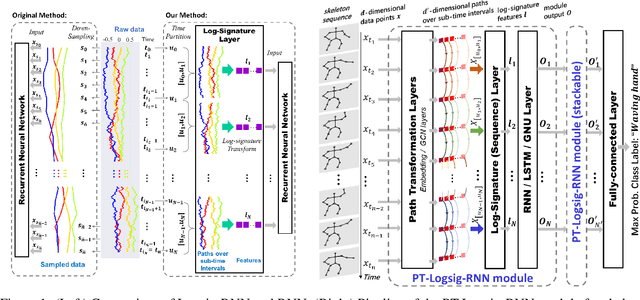
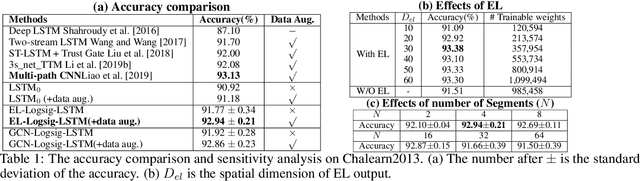


This paper contributes to the challenge of skeleton-based human action recognition in videos. The key step is to develop a generic network architecture to extract discriminative features for the spatio-temporal skeleton data. In this paper, we propose a novel module, namely Logsig-RNN, which is the combination of the log-signature layer and recurrent type neural networks (RNNs). The former one comes from the mathematically principled technology of signatures and log-signatures as representations for streamed data, which can manage high sample rate streams, non-uniform sampling and time series of variable length. It serves as an enhancement of the recurrent layer, which can be conveniently plugged into neural networks. Besides we propose two path transformation layers to significantly reduce path dimension while retaining the essential information fed into the Logsig-RNN module. Finally, numerical results demonstrate that replacing the RNN module by the Logsig-RNN module in SOTA networks consistently improves the performance on both Chalearn gesture data and NTU RGB+D 120 action data in terms of accuracy and robustness. In particular, we achieve the state-of-the-art accuracy on Chalearn2013 gesture data by combining simple path transformation layers with the Logsig-RNN. Codes are available at https://github.com/steveliao93/GCN_LogsigRNN.
Computing the full signature kernel as the solution of a Goursat problem
Jun 26, 2020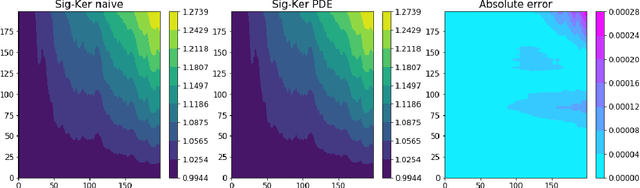
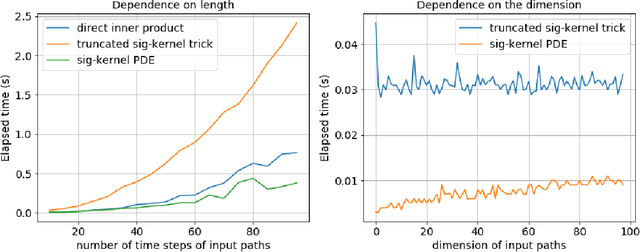
Recently there has been an increased interested in the development of kernel methods for sequential data. An inner product between the signatures of two paths can be shown to be a reproducing kernel and therefore suitable to be used in the context of data science. An efficient algorithm has been proposed to compute the signature kernel by truncating the two input signatures at a certain level, mainly focusing on the case of continuous paths of bounded variation. In this paper we show that the full (i.e. untruncated) signature kernel is the solution of a Goursat problem which can be efficiently computed by finite different schemes (python code can be found in https://github.com/crispitagorico/SignatureKernel). In practice, this result provides a kernel trick for computing the full signature kernel. Furthermore, we use a density argument to extend the previous analysis to the space of geometric rough paths, and prove using classical theory of integration of one-forms along rough paths that the full signature kernel solves a rough integral equation analogous to the PDE derived for the bounded variation case.
Learning stochastic differential equations using RNN with log signature features
Sep 22, 2019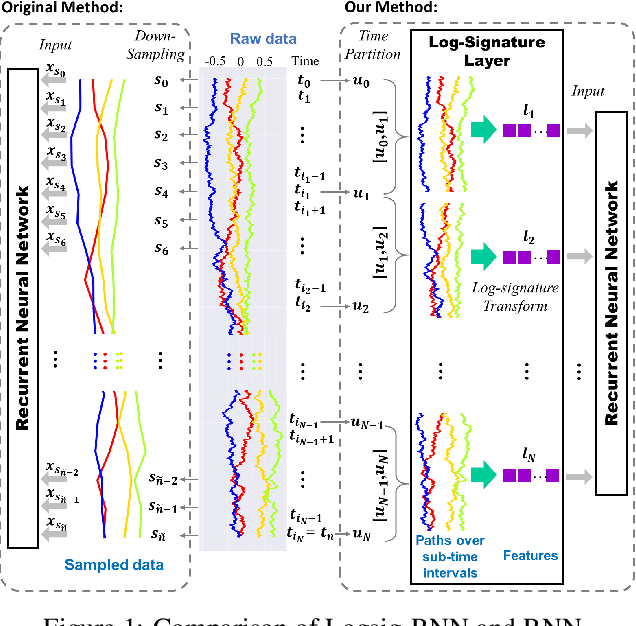



This paper contributes to the challenge of learning a function on streamed multimodal data through evaluation. The core of the result of our paper is the combination of two quite different approaches to this problem. One comes from the mathematically principled technology of signatures and log-signatures as representations for streamed data, while the other draws on the techniques of recurrent neural networks (RNN). The ability of the former to manage high sample rate streams and the latter to manage large scale nonlinear interactions allows hybrid algorithms that are easy to code, quicker to train, and of lower complexity for a given accuracy. We illustrate the approach by approximating the unknown functional as a controlled differential equation. Linear functionals on solutions of controlled differential equations are the natural universal class of functions on data streams. Following this approach, we propose a hybrid Logsig-RNN algorithm that learns functionals on streamed data. By testing on various datasets, i.e. synthetic data, NTU RGB+D 120 skeletal action data, and Chalearn2013 gesture data, our algorithm achieves the outstanding accuracy with superior efficiency and robustness.
Skeleton-based Gesture Recognition Using Several Fully Connected Layers with Path Signature Features and Temporal Transformer Module
Dec 07, 2018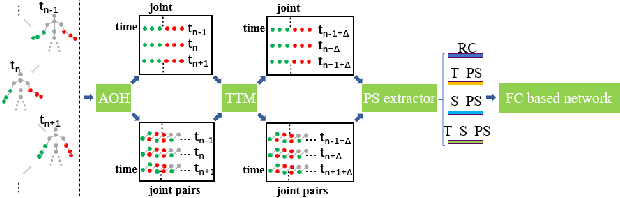
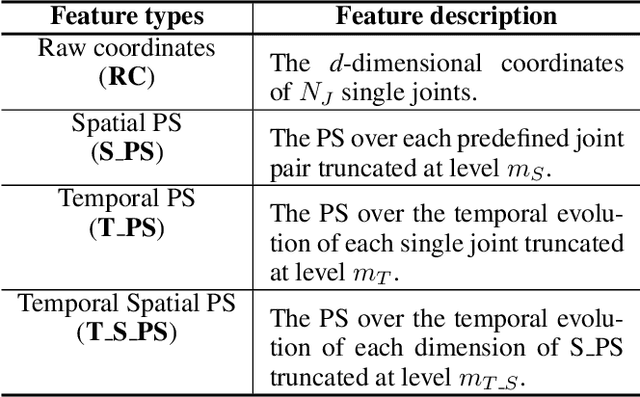
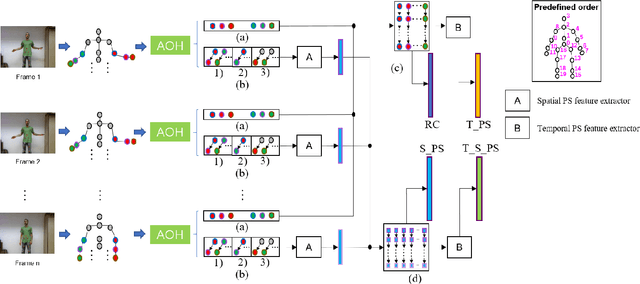
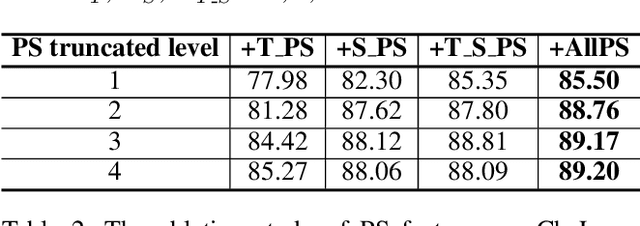
The skeleton based gesture recognition is gaining more popularity due to its wide possible applications. The key issues are how to extract discriminative features and how to design the classification model. In this paper, we first leverage a robust feature descriptor, path signature (PS), and propose three PS features to explicitly represent the spatial and temporal motion characteristics, i.e., spatial PS (S_PS), temporal PS (T_PS) and temporal spatial PS (T_S_PS). Considering the significance of fine hand movements in the gesture, we propose an "attention on hand" (AOH) principle to define joint pairs for the S_PS and select single joint for the T_PS. In addition, the dyadic method is employed to extract the T_PS and T_S_PS features that encode global and local temporal dynamics in the motion. Secondly, without the recurrent strategy, the classification model still faces challenges on temporal variation among different sequences. We propose a new temporal transformer module (TTM) that can match the sequence key frames by learning the temporal shifting parameter for each input. This is a learning-based module that can be included into standard neural network architecture. Finally, we design a multi-stream fully connected layer based network to treat spatial and temporal features separately and fused them together for the final result. We have tested our method on three benchmark gesture datasets, i.e., ChaLearn 2016, ChaLearn 2013 and MSRC-12. Experimental results demonstrate that we achieve the state-of-the-art performance on skeleton-based gesture recognition with high computational efficiency.
Leveraging the Path Signature for Skeleton-based Human Action Recognition
Jul 13, 2017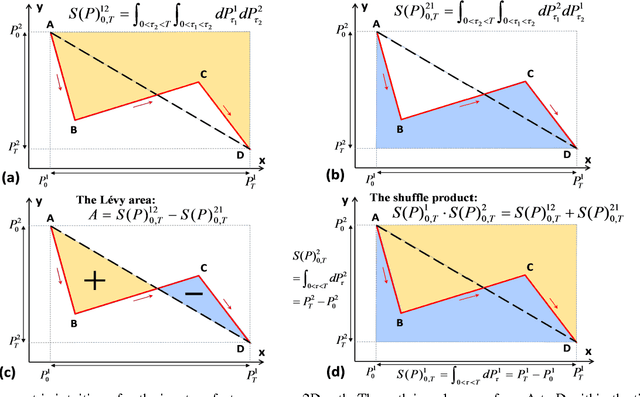
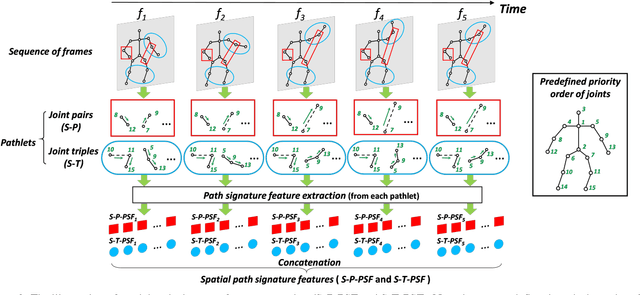
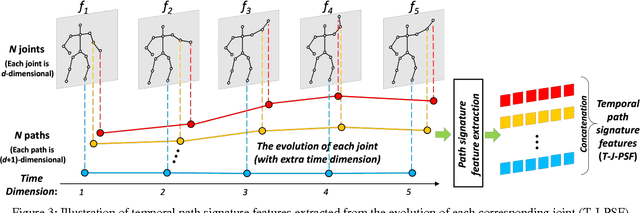
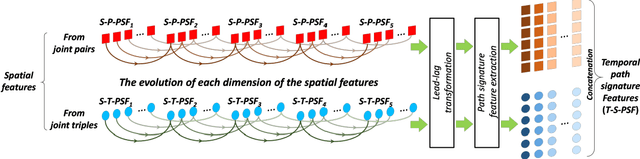
Human action recognition in videos is one of the most challenging tasks in computer vision. One important issue is how to design discriminative features for representing spatial context and temporal dynamics. Here, we introduce a path signature feature to encode information from intra-frame and inter-frame contexts. A key step towards leveraging this feature is to construct the proper trajectories (paths) for the data steam. In each frame, the correlated constraints of human joints are treated as small paths, then the spatial path signature features are extracted from them. In video data, the evolution of these spatial features over time can also be regarded as paths from which the temporal path signature features are extracted. Eventually, all these features are concatenated to constitute the input vector of a fully connected neural network for action classification. Experimental results on four standard benchmark action datasets, J-HMDB, SBU Dataset, Berkeley MHAD, and NTURGB+D demonstrate that the proposed approach achieves state-of-the-art accuracy even in comparison with recent deep learning based models.
Online Signature Verification using Recurrent Neural Network and Length-normalized Path Signature
May 19, 2017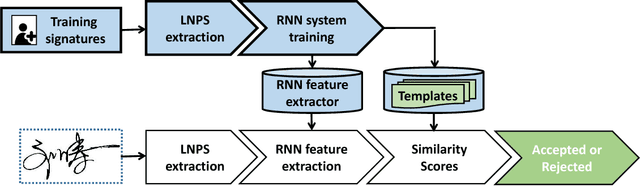
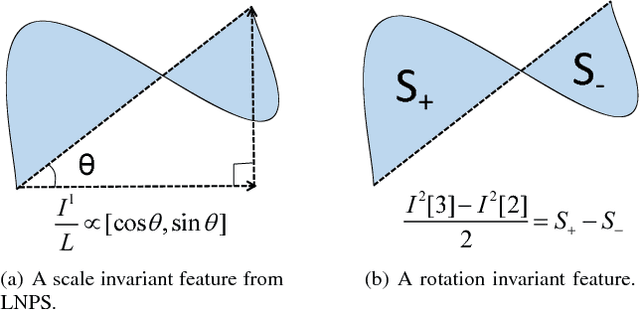
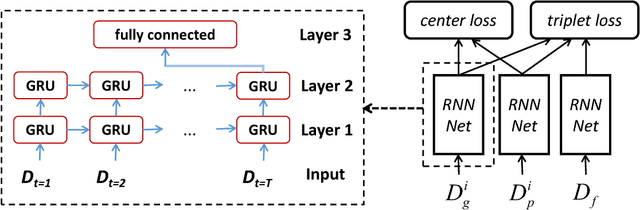
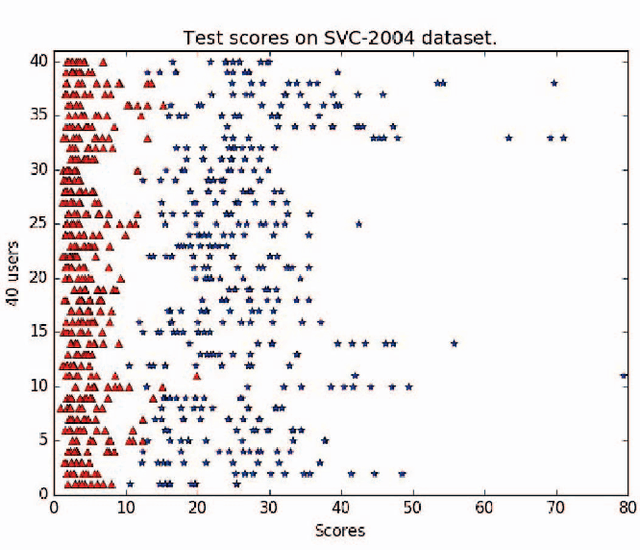
Inspired by the great success of recurrent neural networks (RNNs) in sequential modeling, we introduce a novel RNN system to improve the performance of online signature verification. The training objective is to directly minimize intra-class variations and to push the distances between skilled forgeries and genuine samples above a given threshold. By back-propagating the training signals, our RNN network produced discriminative features with desired metrics. Additionally, we propose a novel descriptor, called the length-normalized path signature (LNPS), and apply it to online signature verification. LNPS has interesting properties, such as scale invariance and rotation invariance after linear combination, and shows promising results in online signature verification. Experiments on the publicly available SVC-2004 dataset yielded state-of-the-art performance of 2.37% equal error rate (EER).
Building Fast and Compact Convolutional Neural Networks for Offline Handwritten Chinese Character Recognition
Feb 26, 2017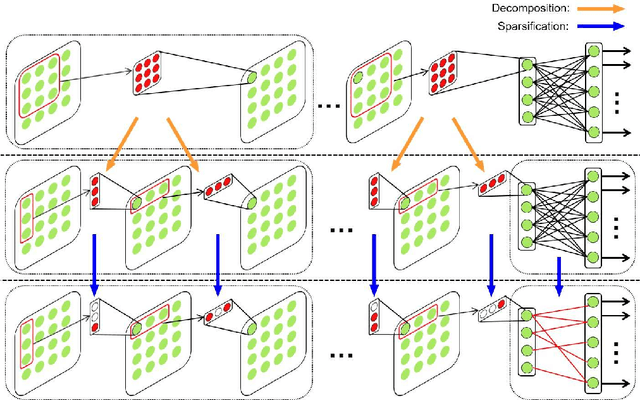


Like other problems in computer vision, offline handwritten Chinese character recognition (HCCR) has achieved impressive results using convolutional neural network (CNN)-based methods. However, larger and deeper networks are needed to deliver state-of-the-art results in this domain. Such networks intuitively appear to incur high computational cost, and require the storage of a large number of parameters, which renders them unfeasible for deployment in portable devices. To solve this problem, we propose a Global Supervised Low-rank Expansion (GSLRE) method and an Adaptive Drop-weight (ADW) technique to solve the problems of speed and storage capacity. We design a nine-layer CNN for HCCR consisting of 3,755 classes, and devise an algorithm that can reduce the networks computational cost by nine times and compress the network to 1/18 of the original size of the baseline model, with only a 0.21% drop in accuracy. In tests, the proposed algorithm surpassed the best single-network performance reported thus far in the literature while requiring only 2.3 MB for storage. Furthermore, when integrated with our effective forward implementation, the recognition of an offline character image took only 9.7 ms on a CPU. Compared with the state-of-the-art CNN model for HCCR, our approach is approximately 30 times faster, yet 10 times more cost efficient.
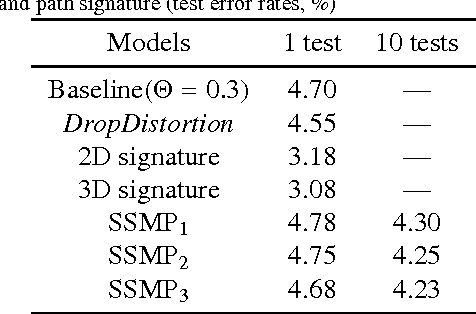
Toward high-performance online HCCR: a CNN approach with DropDistortion, path signature and spatial stochastic max-pooling
Feb 24, 2017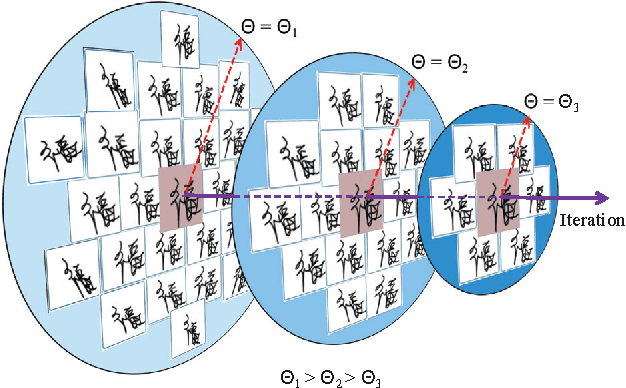


This paper presents an investigation of several techniques that increase the accuracy of online handwritten Chinese character recognition (HCCR). We propose a new training strategy named DropDistortion to train a deep convolutional neural network (DCNN) with distorted samples. DropDistortion gradually lowers the degree of character distortion during training, which allows the DCNN to better generalize. Path signature is used to extract effective features for online characters. Further improvement is achieved by employing spatial stochastic max-pooling as a method of feature map distortion and model averaging. Experiments were carried out on three publicly available datasets, namely CASIA-OLHWDB 1.0, CASIA-OLHWDB 1.1, and the ICDAR2013 online HCCR competition dataset. The proposed techniques yield state-of-the-art recognition accuracies of 97.67%, 97.30%, and 97.99%, respectively.