 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of a Very Compact CNN Classifier for Online Handwritten Chinese Character Recognition Using DropWeight and Global Pooling
May 15, 2017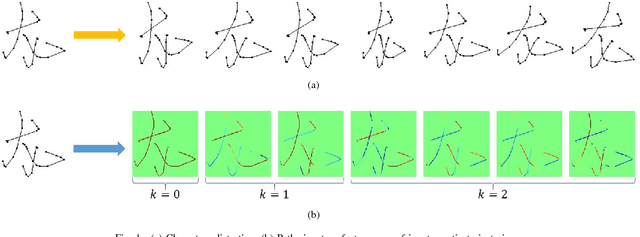
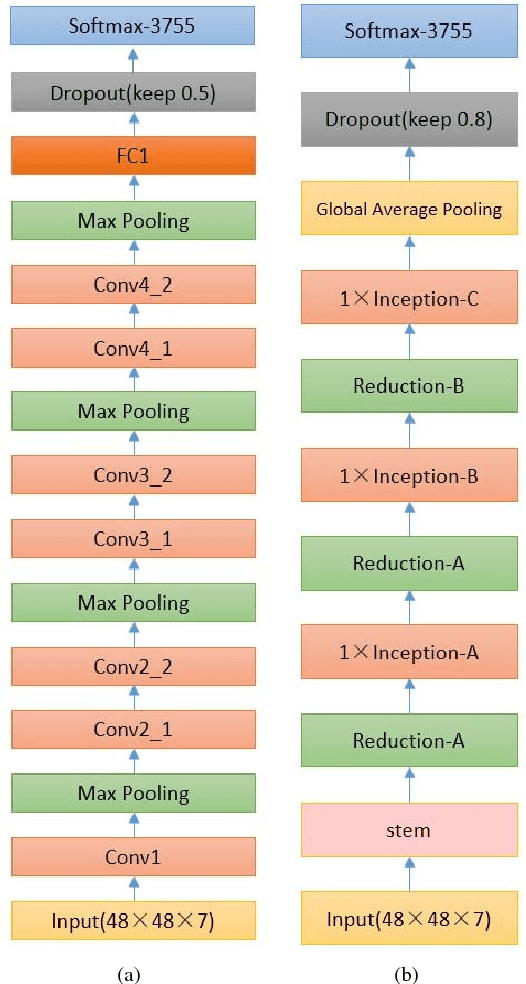

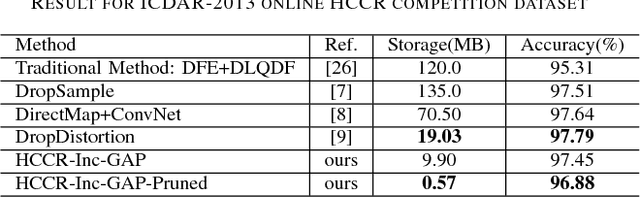
Currently, owing to the ubiquity of mobile devices, online handwritten Chinese character recognition (HCCR) has become one of the suitable choice for feeding input to cell phones and tablet devices. Over the past few years, larger and deeper convolutional neural networks (CNNs) have extensively been employed for improving character recognition performance. However, its substantial storage requirement is a significant obstacle in deploying such networks into portable electronic devices. To circumvent this problem, we propose a novel technique called DropWeight for pruning redundant connections in the CNN architecture. It is revealed that the proposed method not only treats streamlined architectures such as AlexNet and VGGNet well but also exhibits remarkable performance for deep residual network and inception network. We also demonstrate that global pooling is a better choice for building very compact online HCCR systems. Experiments were performed on the ICDAR-2013 online HCCR competition dataset using our proposed network, and it is found that the proposed approach requires only 0.57 MB for storage, whereas state-of-the-art CNN-based methods require up to 135 MB; meanwhile the performance is decreased only by 0.91%.
Building Fast and Compact Convolutional Neural Networks for Offline Handwritten Chinese Character Recognition
Feb 26, 2017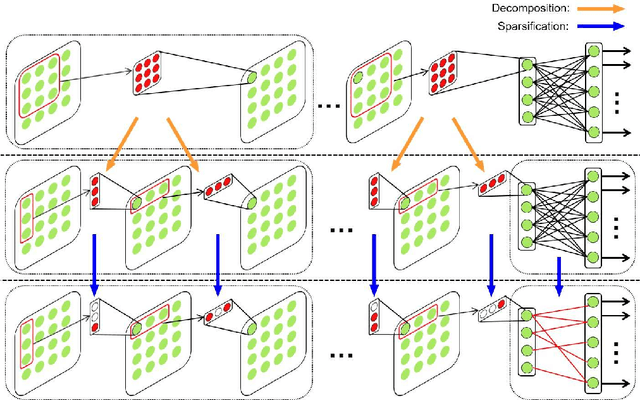


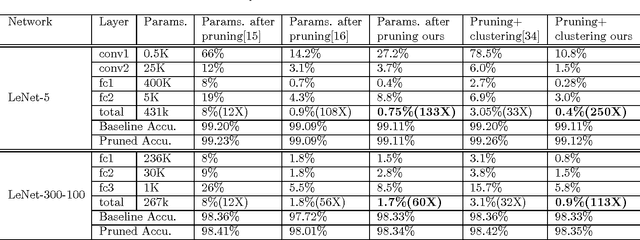
Like other problems in computer vision, offline handwritten Chinese character recognition (HCCR) has achieved impressive results using convolutional neural network (CNN)-based methods. However, larger and deeper networks are needed to deliver state-of-the-art results in this domain. Such networks intuitively appear to incur high computational cost, and require the storage of a large number of parameters, which renders them unfeasible for deployment in portable devices. To solve this problem, we propose a Global Supervised Low-rank Expansion (GSLRE) method and an Adaptive Drop-weight (ADW) technique to solve the problems of speed and storage capacity. We design a nine-layer CNN for HCCR consisting of 3,755 classes, and devise an algorithm that can reduce the networks computational cost by nine times and compress the network to 1/18 of the original size of the baseline model, with only a 0.21% drop in accuracy. In tests, the proposed algorithm surpassed the best single-network performance reported thus far in the literature while requiring only 2.3 MB for storage. Furthermore, when integrated with our effective forward implementation, the recognition of an offline character image took only 9.7 ms on a CPU. Compared with the state-of-the-art CNN model for HCCR, our approach is approximately 30 times faster, yet 10 times more cost efficient.