 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAR$^2$-RAG: Planned Active Retrieval and Reasoning for Multi-Hop Question Answering
Mar 30, 2026Large language models (LLMs) remain brittle on multi-hop question answering (MHQA), where answering requires combining evidence across documents through retrieval and reasoning. Iterative retrieval systems can fail by locking onto an early low-recall trajectory and amplifying downstream errors, while planning-only approaches may produce static query sets that cannot adapt when intermediate evidence changes. We propose \textbf{Planned Active Retrieval and Reasoning RAG (PAR$^2$-RAG)}, a two-stage framework that separates \emph{coverage} from \emph{commitment}. PAR$^2$-RAG first performs breadth-first anchoring to build a high-recall evidence frontier, then applies depth-first refinement with evidence sufficiency control in an iterative loop. Across four MHQA benchmarks, PAR$^2$-RAG consistently outperforms existing state-of-the-art baselines, compared with IRCoT, PAR$^2$-RAG achieves up to \textbf{23.5\%} higher accuracy, with retrieval gains of up to \textbf{10.5\%} in NDCG.
GraphER: An Efficient Graph-Based Enrichment and Reranking Method for Retrieval-Augmented Generation
Mar 26, 2026Semantic search in retrieval-augmented generation (RAG) systems is often insufficient for complex information needs, particularly when relevant evidence is scattered across multiple sources. Prior approaches to this problem include agentic retrieval strategies, which expand the semantic search space by generating additional queries. However, these methods do not fully leverage the organizational structure of the data and instead rely on iterative exploration, which can lead to inefficient retrieval. Another class of approaches employs knowledge graphs to model non-semantic relationships through graph edges. Although effective in capturing richer proximities, such methods incur significant maintenance costs and are often incompatible with the vector stores used in most production systems. To address these limitations, we propose GraphER, a graph-based enrichment and reranking method that captures multiple forms of proximity beyond semantic similarity. GraphER independently enriches data objects during offline indexing and performs graph-based reranking over candidate objects at query time. This design does not require a knowledge graph, allowing GraphER to integrate seamlessly with standard vector stores. In addition, GraphER is retriever-agnostic and introduces negligible latency overhead. Experiments on multiple retrieval benchmarks demonstrate the effectiveness of the proposed approach.
The Dresden Dataset for 4D Reconstruction of Non-Rigid Abdominal Surgical Scenes
Mar 03, 2026The D4D Dataset provides paired endoscopic video and high-quality structured-light geometry for evaluating 3D reconstruction of deforming abdominal soft tissue in realistic surgical conditions. Data were acquired from six porcine cadaver sessions using a da Vinci Xi stereo endoscope and a Zivid structured-light camera, registered via optical tracking and manually curated iterative alignment methods. Three sequence types - whole deformations, incremental deformations, and moved-camera clips - probe algorithm robustness to non-rigid motion, deformation magnitude, and out-of-view updates. Each clip provides rectified stereo images, per-frame instrument masks, stereo depth, start/end structured-light point clouds, curated camera poses and camera intrinsics. In postprocessing, ICP and semi-automatic registration techniques are used to register data, and instrument masks are created. The dataset enables quantitative geometric evaluation in both visible and occluded regions, alongside photometric view-synthesis baselines. Comprising over 300,000 frames and 369 point clouds across 98 curated recordings, this resource can serve as a comprehensive benchmark for developing and evaluating non-rigid SLAM, 4D reconstruction, and depth estimation methods.
DTP: A Simple yet Effective Distracting Token Pruning Framework for Vision-Language Action Models
Jan 22, 2026Vision-Language Action (VLA) models have shown remarkable progress in robotic manipulation by leveraging the powerful perception abilities of Vision-Language Models (VLMs) to understand environments and directly output actions. However, by default, VLA models may overly attend to image tokens in the task-irrelevant region, which we describe as 'distracting tokens'. This behavior can disturb the model from the generation of the desired action tokens in each step, affecting the success rate of tasks. In this paper, we introduce a simple yet effective plug-and-play Distracting Token Pruning (DTP) framework, which dynamically detects and prunes these distracting image tokens. By correcting the model's visual attention patterns, we aim to improve the task success rate, as well as exploring the performance upper boundaries of the model without altering its original architecture or adding additional inputs. Experiments on the SIMPLER Benchmark (Li et al., 2024) show that our method consistently achieving relative improvements in task success rates across different types of novel VLA models, demonstrating generalizability to transformer-based VLAs. Further analysis reveals a negative correlation between the task success rate and the amount of attentions in the task-irrelevant region for all models tested, highlighting a common phenomenon of VLA models that could guide future research. We also publish our code at: https://anonymous.4open.science/r/CBD3.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
LexRel: Benchmarking Legal Relation Extraction for Chinese Civil Cases
Dec 14, 2025Legal relations form a highly consequential analytical framework of civil law system, serving as a crucial foundation for resolving disputes and realizing values of the rule of law in judicial practice. However, legal relations in Chinese civil cases remain underexplored in the field of legal artificial intelligence (legal AI), largely due to the absence of comprehensive schemas. In this work, we firstly introduce a comprehensive schema, which contains a hierarchical taxonomy and definitions of arguments, for AI systems to capture legal relations in Chinese civil cases. Based on this schema, we then formulate legal relation extraction task and present LexRel, an expert-annotated benchmark for legal relation extraction in Chinese civil law. We use LexRel to evaluate state-of-the-art large language models (LLMs) on legal relation extractions, showing that current LLMs exhibit significant limitations in accurately identifying civil legal relations. Furthermore, we demonstrate that incorporating legal relations information leads to consistent performance gains on other downstream legal AI tasks.
Shedding Light on VLN Robustness: A Black-box Framework for Indoor Lighting-based Adversarial Attack
Nov 17, 2025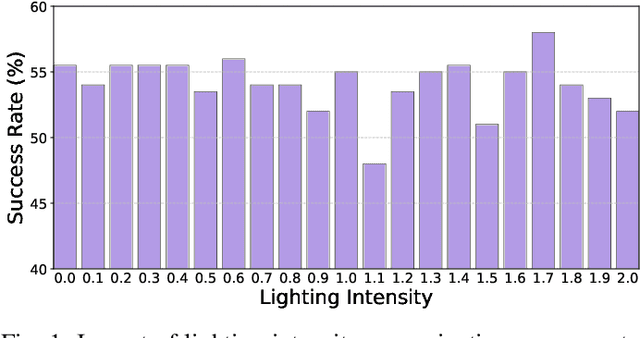
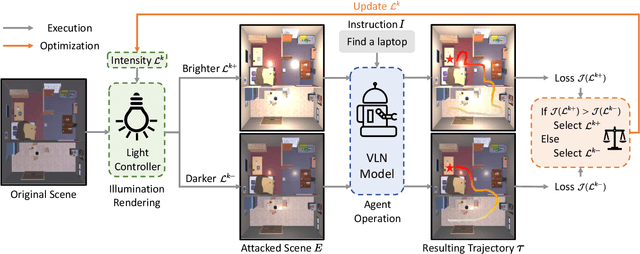
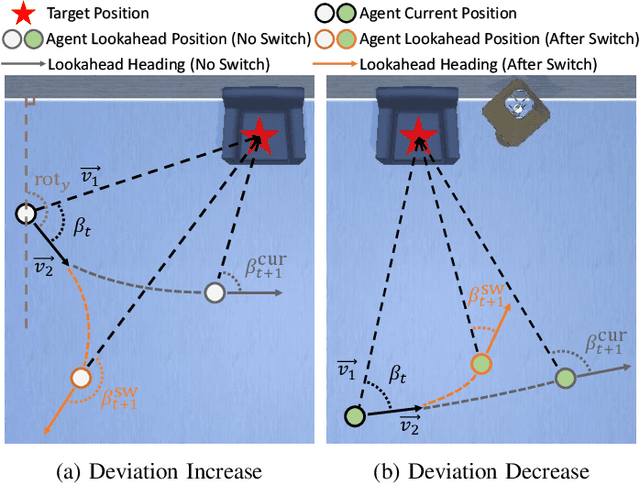

Vision-and-Language Navigation (VLN) agents have made remarkable progress, but their robustness remains insufficiently studied. Existing adversarial evaluations often rely on perturbations that manifest as unusual textures rarely encountered in everyday indoor environments. Errors under such contrived conditions have limited practical relevance, as real-world agents are unlikely to encounter such artificial patterns. In this work, we focus on indoor lighting, an intrinsic yet largely overlooked scene attribute that strongly influences navigation. We propose Indoor Lighting-based Adversarial Attack (ILA), a black-box framework that manipulates global illumination to disrupt VLN agents. Motivated by typical household lighting usage, we design two attack modes: Static Indoor Lighting-based Attack (SILA), where the lighting intensity remains constant throughout an episode, and Dynamic Indoor Lighting-based Attack (DILA), where lights are switched on or off at critical moments to induce abrupt illumination changes. We evaluate ILA on two state-of-the-art VLN models across three navigation tasks. Results show that ILA significantly increases failure rates while reducing trajectory efficiency, revealing previously unrecognized vulnerabilities of VLN agents to realistic indoor lighting variations.
Vibration-Based Energy Metric for Restoring Needle Alignment in Autonomous Robotic Ultrasound
Aug 09, 2025Precise needle alignment is essential for percutaneous needle insertion in robotic ultrasound-guided procedures. However, inherent challenges such as speckle noise, needle-like artifacts, and low image resolution make robust needle detection difficult, particularly when visibility is reduced or lost. In this paper, we propose a method to restore needle alignment when the ultrasound imaging plane and the needle insertion plane are misaligned. Unlike many existing approaches that rely heavily on needle visibility in ultrasound images, our method uses a more robust feature by periodically vibrating the needle using a mechanical system. Specifically, we propose a vibration-based energy metric that remains effective even when the needle is fully out of plane. Using this metric, we develop a control strategy to reposition the ultrasound probe in response to misalignments between the imaging plane and the needle insertion plane in both translation and rotation. Experiments conducted on ex-vivo porcine tissue samples using a dual-arm robotic ultrasound-guided needle insertion system demonstrate the effectiveness of the proposed approach. The experimental results show the translational error of 0.41$\pm$0.27 mm and the rotational error of 0.51$\pm$0.19 degrees.
PIVOTS: Aligning unseen Structures using Preoperative to Intraoperative Volume-To-Surface Registration for Liver Navigation
Jul 27, 2025
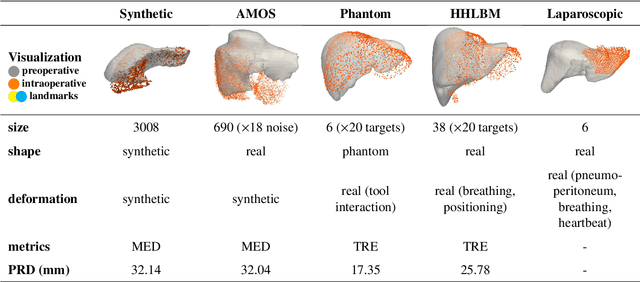


Non-rigid registration is essential for Augmented Reality guided laparoscopic liver surgery by fusing preoperative information, such as tumor location and vascular structures, into the limited intraoperative view, thereby enhancing surgical navigation. A prerequisite is the accurate prediction of intraoperative liver deformation which remains highly challenging due to factors such as large deformation caused by pneumoperitoneum, respiration and tool interaction as well as noisy intraoperative data, and limited field of view due to occlusion and constrained camera movement. To address these challenges, we introduce PIVOTS, a Preoperative to Intraoperative VOlume-To-Surface registration neural network that directly takes point clouds as input for deformation prediction. The geometric feature extraction encoder allows multi-resolution feature extraction, and the decoder, comprising novel deformation aware cross attention modules, enables pre- and intraoperative information interaction and accurate multi-level displacement prediction. We train the neural network on synthetic data simulated from a biomechanical simulation pipeline and validate its performance on both synthetic and real datasets. Results demonstrate superior registration performance of our method compared to baseline methods, exhibiting strong robustness against high amounts of noise, large deformation, and various levels of intraoperative visibility. We publish the training and test sets as evaluation benchmarks and call for a fair comparison of liver registration methods with volume-to-surface data. Code and datasets are available here https://github.com/pengliu-nct/PIVOTS.
DAM-GT: Dual Positional Encoding-Based Attention Masking Graph Transformer for Node Classification
May 23, 2025Neighborhood-aware tokenized graph Transformers have recently shown great potential for node classification tasks. Despite their effectiveness, our in-depth analysis of neighborhood tokens reveals two critical limitations in the existing paradigm. First, current neighborhood token generation methods fail to adequately capture attribute correlations within a neighborhood. Second, the conventional self-attention mechanism suffers from attention diversion when processing neighborhood tokens, where high-hop neighborhoods receive disproportionate focus, severely disrupting information interactions between the target node and its neighborhood tokens. To address these challenges, we propose DAM-GT, Dual positional encoding-based Attention Masking graph Transformer. DAM-GT introduces a novel dual positional encoding scheme that incorporates attribute-aware encoding via an attribute clustering strategy, effectively preserving node correlations in both topological and attribute spaces. In addition, DAM-GT formulates a new attention mechanism with a simple yet effective masking strategy to guide interactions between target nodes and their neighborhood tokens, overcoming the issue of attention diversion. Extensive experiments on various graphs with different homophily levels as well as different scales demonstrate that DAM-GT consistently outperforms state-of-the-art methods in node classification tasks.