 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAM-GT: Dual Positional Encoding-Based Attention Masking Graph Transformer for Node Classification
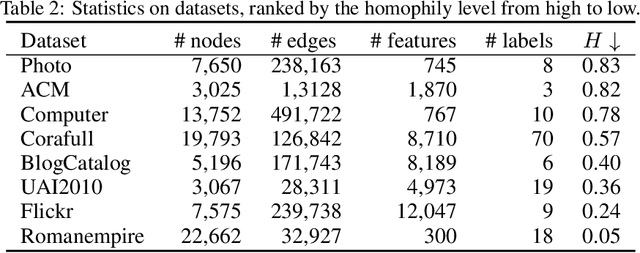
May 23, 2025Neighborhood-aware tokenized graph Transformers have recently shown great potential for node classification tasks. Despite their effectiveness, our in-depth analysis of neighborhood tokens reveals two critical limitations in the existing paradigm. First, current neighborhood token generation methods fail to adequately capture attribute correlations within a neighborhood. Second, the conventional self-attention mechanism suffers from attention diversion when processing neighborhood tokens, where high-hop neighborhoods receive disproportionate focus, severely disrupting information interactions between the target node and its neighborhood tokens. To address these challenges, we propose DAM-GT, Dual positional encoding-based Attention Masking graph Transformer. DAM-GT introduces a novel dual positional encoding scheme that incorporates attribute-aware encoding via an attribute clustering strategy, effectively preserving node correlations in both topological and attribute spaces. In addition, DAM-GT formulates a new attention mechanism with a simple yet effective masking strategy to guide interactions between target nodes and their neighborhood tokens, overcoming the issue of attention diversion. Extensive experiments on various graphs with different homophily levels as well as different scales demonstrate that DAM-GT consistently outperforms state-of-the-art methods in node classification tasks.
Enhancing Pre-Trained Model-Based Class-Incremental Learning through Neural Collapse
Apr 25, 2025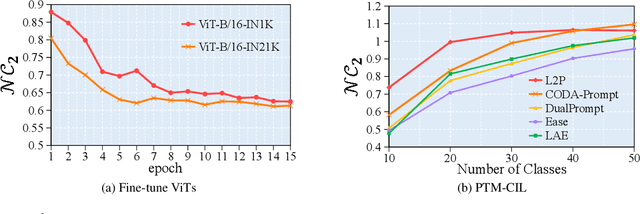
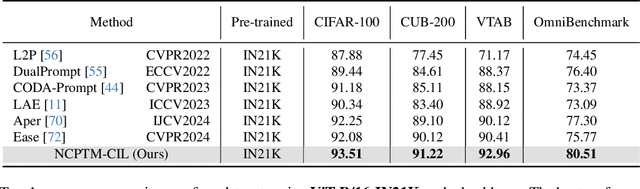
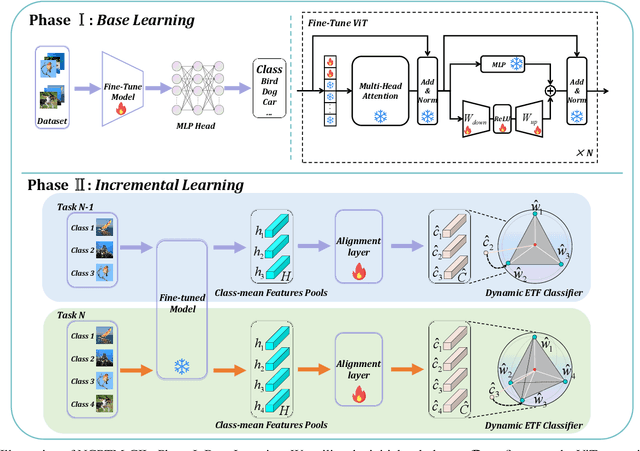

Class-Incremental Learning (CIL) is a critical capability for real-world applications, enabling learning systems to adapt to new tasks while retaining knowledge from previous ones. Recent advancements in pre-trained models (PTMs) have significantly advanced the field of CIL, demonstrating superior performance over traditional methods. However, understanding how features evolve and are distributed across incremental tasks remains an open challenge. In this paper, we propose a novel approach to modeling feature evolution in PTM-based CIL through the lens of neural collapse (NC), a striking phenomenon observed in the final phase of training, which leads to a well-separated, equiangular feature space. We explore the connection between NC and CIL effectiveness, showing that aligning feature distributions with the NC geometry enhances the ability to capture the dynamic behavior of continual learning. Based on this insight, we introduce Neural Collapse-inspired Pre-Trained Model-based CIL (NCPTM-CIL), a method that dynamically adjusts the feature space to conform to the elegant NC structure, thereby enhancing the continual learning process. Extensive experiments demonstrate that NCPTM-CIL outperforms state-of-the-art methods across four benchmark datasets. Notably, when initialized with ViT-B/16-IN1K, NCPTM-CIL surpasses the runner-up method by 6.73% on VTAB, 1.25% on CIFAR-100, and 2.5% on OmniBenchmark.
Rethinking Tokenized Graph Transformers for Node Classification
Feb 12, 2025Node tokenized graph Transformers (GTs) have shown promising performance in node classification. The generation of token sequences is the key module in existing tokenized GTs which transforms the input graph into token sequences, facilitating the node representation learning via Transformer. In this paper, we observe that the generations of token sequences in existing GTs only focus on the first-order neighbors on the constructed similarity graphs, which leads to the limited usage of nodes to generate diverse token sequences, further restricting the potential of tokenized GTs for node classification. To this end, we propose a new method termed SwapGT. SwapGT first introduces a novel token swapping operation based on the characteristics of token sequences that fully leverages the semantic relevance of nodes to generate more informative token sequences. Then, SwapGT leverages a Transformer-based backbone to learn node representations from the generated token sequences. Moreover, SwapGT develops a center alignment loss to constrain the representation learning from multiple token sequences, further enhancing the model performance. Extensive empirical results on various datasets showcase the superiority of SwapGT for node classification.
Tokenizing 3D Molecule Structure with Quantized Spherical Coordinates
Dec 02, 2024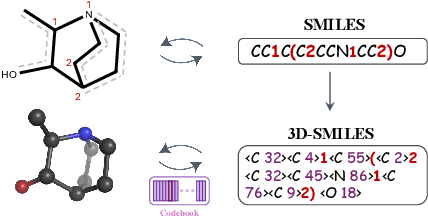
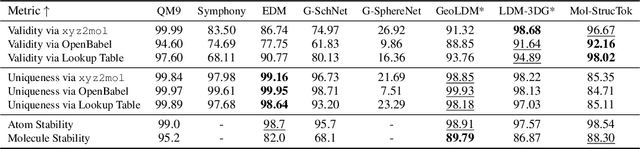
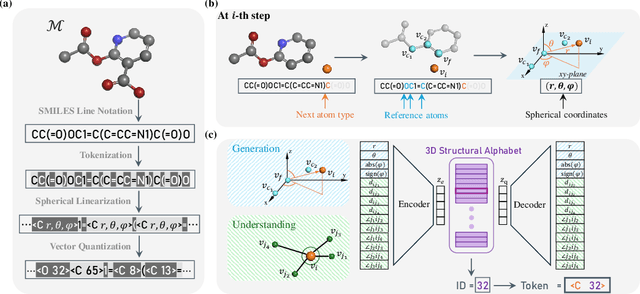

The application of language models (LMs) to molecular structure generation using line notations such as SMILES and SELFIES has been well-established in the field of cheminformatics. However, extending these models to generate 3D molecular structures presents significant challenges. Two primary obstacles emerge: (1) the difficulty in designing a 3D line notation that ensures SE(3)-invariant atomic coordinates, and (2) the non-trivial task of tokenizing continuous coordinates for use in LMs, which inherently require discrete inputs. To address these challenges, we propose Mol-StrucTok, a novel method for tokenizing 3D molecular structures. Our approach comprises two key innovations: (1) We design a line notation for 3D molecules by extracting local atomic coordinates in a spherical coordinate system. This notation builds upon existing 2D line notations and remains agnostic to their specific forms, ensuring compatibility with various molecular representation schemes. (2) We employ a Vector Quantized Variational Autoencoder (VQ-VAE) to tokenize these coordinates, treating them as generation descriptors. To further enhance the representation, we incorporate neighborhood bond lengths and bond angles as understanding descriptors. Leveraging this tokenization framework, we train a GPT-2 style model for 3D molecular generation tasks. Results demonstrate strong performance with significantly faster generation speeds and competitive chemical stability compared to previous methods. Further, by integrating our learned discrete representations into Graphormer model for property prediction on QM9 dataset, Mol-StrucTok reveals consistent improvements across various molecular properties, underscoring the versatility and robustness of our approach.
Leveraging Contrastive Learning for Enhanced Node Representations in Tokenized Graph Transformers
Jun 27, 2024


While tokenized graph Transformers have demonstrated strong performance in node classification tasks, their reliance on a limited subset of nodes with high similarity scores for constructing token sequences overlooks valuable information from other nodes, hindering their ability to fully harness graph information for learning optimal node representations. To address this limitation, we propose a novel graph Transformer called GCFormer. Unlike previous approaches, GCFormer develops a hybrid token generator to create two types of token sequences, positive and negative, to capture diverse graph information. And a tailored Transformer-based backbone is adopted to learn meaningful node representations from these generated token sequences. Additionally, GCFormer introduces contrastive learning to extract valuable information from both positive and negative token sequences, enhancing the quality of learned node representations. Extensive experimental results across various datasets, including homophily and heterophily graphs, demonstrate the superiority of GCFormer in node classification, when compared to representative graph neural networks (GNNs) and graph Transformers.
Diversified Node Sampling based Hierarchical Transformer Pooling for Graph Representation Learning
Oct 31, 2023



Graph pooling methods have been widely used on downsampling graphs, achieving impressive results on multiple graph-level tasks like graph classification and graph generation. An important line called node dropping pooling aims at exploiting learnable scoring functions to drop nodes with comparatively lower significance scores. However, existing node dropping methods suffer from two limitations: (1) for each pooled node, these models struggle to capture long-range dependencies since they mainly take GNNs as the backbones; (2) pooling only the highest-scoring nodes tends to preserve similar nodes, thus discarding the affluent information of low-scoring nodes. To address these issues, we propose a Graph Transformer Pooling method termed GTPool, which introduces Transformer to node dropping pooling to efficiently capture long-range pairwise interactions and meanwhile sample nodes diversely. Specifically, we design a scoring module based on the self-attention mechanism that takes both global context and local context into consideration, measuring the importance of nodes more comprehensively. GTPool further utilizes a diversified sampling method named Roulette Wheel Sampling (RWS) that is able to flexibly preserve nodes across different scoring intervals instead of only higher scoring nodes. In this way, GTPool could effectively obtain long-range information and select more representative nodes. Extensive experiments on 11 benchmark datasets demonstrate the superiority of GTPool over existing popular graph pooling methods.
SignGT: Signed Attention-based Graph Transformer for Graph Representation Learning
Oct 17, 2023



The emerging graph Transformers have achieved impressive performance for graph representation learning over graph neural networks (GNNs). In this work, we regard the self-attention mechanism, the core module of graph Transformers, as a two-step aggregation operation on a fully connected graph. Due to the property of generating positive attention values, the self-attention mechanism is equal to conducting a smooth operation on all nodes, preserving the low-frequency information. However, only capturing the low-frequency information is inefficient in learning complex relations of nodes on diverse graphs, such as heterophily graphs where the high-frequency information is crucial. To this end, we propose a Signed Attention-based Graph Transformer (SignGT) to adaptively capture various frequency information from the graphs. Specifically, SignGT develops a new signed self-attention mechanism (SignSA) that produces signed attention values according to the semantic relevance of node pairs. Hence, the diverse frequency information between different node pairs could be carefully preserved. Besides, SignGT proposes a structure-aware feed-forward network (SFFN) that introduces the neighborhood bias to preserve the local topology information. In this way, SignGT could learn informative node representations from both long-range dependencies and local topology information. Extensive empirical results on both node-level and graph-level tasks indicate the superiority of SignGT against state-of-the-art graph Transformers as well as advanced GNNs.
PIAT: Parameter Interpolation based Adversarial Training for Image Classification
Mar 24, 2023
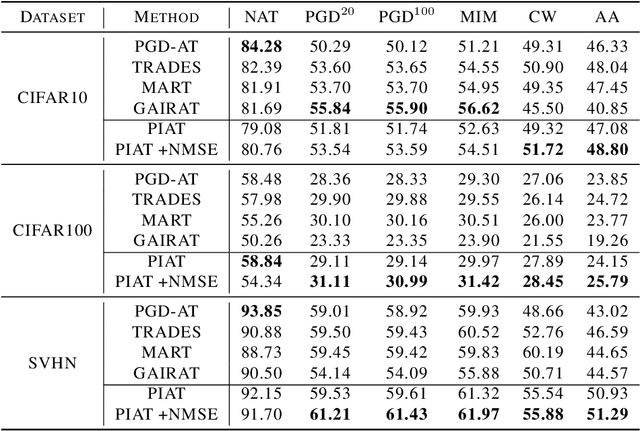
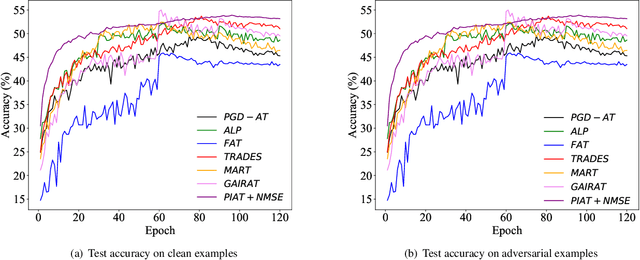
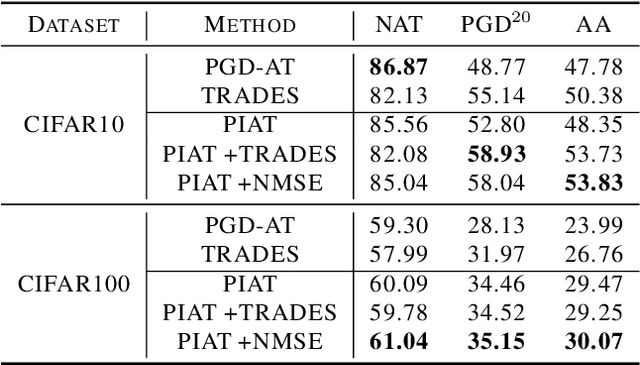
Adversarial training has been demonstrated to be the most effective approach to defend against adversarial attacks. However, existing adversarial training methods show apparent oscillations and overfitting issue in the training process, degrading the defense efficacy. In this work, we propose a novel framework, termed Parameter Interpolation based Adversarial Training (PIAT), that makes full use of the historical information during training. Specifically, at the end of each epoch, PIAT tunes the model parameters as the interpolation of the parameters of the previous and current epochs. Besides, we suggest to use the Normalized Mean Square Error (NMSE) to further improve the robustness by aligning the clean and adversarial examples. Compared with other regularization methods, NMSE focuses more on the relative magnitude of the logits rather than the absolute magnitude. Extensive experiments on several benchmark datasets and various networks show that our method could prominently improve the model robustness and reduce the generalization error. Moreover, our framework is general and could further boost the robust accuracy when combined with other adversarial training methods.
Class-aware Information for Logit-based Knowledge Distillation
Nov 27, 2022



Knowledge distillation aims to transfer knowledge to the student model by utilizing the predictions/features of the teacher model, and feature-based distillation has recently shown its superiority over logit-based distillation. However, due to the cumbersome computation and storage of extra feature transformation, the training overhead of feature-based methods is much higher than that of logit-based distillation. In this work, we revisit the logit-based knowledge distillation, and observe that the existing logit-based distillation methods treat the prediction logits only in the instance level, while many other useful semantic information is overlooked. To address this issue, we propose a Class-aware Logit Knowledge Distillation (CLKD) method, that extents the logit distillation in both instance-level and class-level. CLKD enables the student model mimic higher semantic information from the teacher model, hence improving the distillation performance. We further introduce a novel loss called Class Correlation Loss to force the student learn the inherent class-level correlation of the teacher. Empirical comparisons demonstrate the superiority of the proposed method over several prevailing logit-based methods and feature-based methods, in which CLKD achieves compelling results on various visual classification tasks and outperforms the state-of-the-art baselines.
On the Complexity of Bayesian Generalization
Nov 26, 2022



We consider concept generalization at a large scale in the diverse and natural visual spectrum. Established computational modes (i.e., rule-based or similarity-based) are primarily studied isolated and focus on confined and abstract problem spaces. In this work, we study these two modes when the problem space scales up, and the $complexity$ of concepts becomes diverse. Specifically, at the $representational \ level$, we seek to answer how the complexity varies when a visual concept is mapped to the representation space. Prior psychology literature has shown that two types of complexities (i.e., subjective complexity and visual complexity) (Griffiths and Tenenbaum, 2003) build an inverted-U relation (Donderi, 2006; Sun and Firestone, 2021). Leveraging Representativeness of Attribute (RoA), we computationally confirm the following observation: Models use attributes with high RoA to describe visual concepts, and the description length falls in an inverted-U relation with the increment in visual complexity. At the $computational \ level$, we aim to answer how the complexity of representation affects the shift between the rule- and similarity-based generalization. We hypothesize that category-conditioned visual modeling estimates the co-occurrence frequency between visual and categorical attributes, thus potentially serving as the prior for the natural visual world. Experimental results show that representations with relatively high subjective complexity outperform those with relatively low subjective complexity in the rule-based generalization, while the trend is the opposite in the similarity-based generalization.