 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network-Based Time-Frequency-Bin-Wise Linear Combination of Beamformers for Underdetermined Target Source Extraction
Mar 16, 2026Extracting a target source from underdetermined mixtures is challenging for beamforming approaches. Recently proposed time-frequency-bin-wise switching (TFS) and linear combination (TFLC) strategies mitigate this by combining multiple beamformers in each time-frequency (TF) bin and choosing combination weights that minimize the output power. However, making this decision independently for each TF bin can weaken temporal-spectral coherence, causing discontinuities and consequently degrading extraction performance. In this paper, we propose a novel neural network-based time-frequency-bin-wise linear combination (NN-TFLC) framework that constructs minimum power distortionless response (MPDR) beamformers without explicit noise covariance estimation. The network encodes the mixture and beamformer outputs, and predicts temporally and spectrally coherent linear combination weights via a cross-attention mechanism. On dual-microphone mixtures with multiple interferers, NN-TFLC-MPDR consistently outperforms TFS/TFLC-MPDR and achieves competitive performance with TFS/TFLC built on the minimum variance distortionless response (MVDR) beamformers that require noise priors.
Dual Diffusion Models for Multi-modal Guided 3D Avatar Generation
Mar 04, 2026Generating high-fidelity 3D avatars from text or image prompts is highly sought after in virtual reality and human-computer interaction. However, existing text-driven methods often rely on iterative Score Distillation Sampling (SDS) or CLIP optimization, which struggle with fine-grained semantic control and suffer from excessively slow inference. Meanwhile, image-driven approaches are severely bottlenecked by the scarcity and high acquisition cost of high-quality 3D facial scans, limiting model generalization. To address these challenges, we first construct a novel, large-scale dataset comprising over 100,000 pairs across four modalities: fine-grained textual descriptions, in-the-wild face images, high-quality light-normalized texture UV maps, and 3D geometric shapes. Leveraging this comprehensive dataset, we propose PromptAvatar, a framework featuring dual diffusion models. Specifically, it integrates a Texture Diffusion Model (TDM) that supports flexible multi-condition guidance from text and/or image prompts, alongside a Geometry Diffusion Model (GDM) guided by text prompts. By learning the direct mapping from multi-modal prompts to 3D representations, PromptAvatar eliminates the need for time-consuming iterative optimization, successfully generating high-fidelity, shading-free 3D avatars in under 10 seconds. Extensive quantitative and qualitative experiments demonstrate that our method significantly outperforms existing state-of-the-art approaches in generation quality, fine-grained detail alignment, and computational efficiency.
Robust Online Overdetermined Independent Vector Analysis Based on Bilinear Decomposition
Jan 18, 2026Online blind source separation is essential for both speech communication and human-machine interaction. Among existing approaches, overdetermined independent vector analysis (OverIVA) delivers strong performance by exploiting the statistical independence of source signals and the orthogonality between source and noise subspaces. However, when applied to large microphone arrays, the number of parameters grows rapidly, which can degrade online estimation accuracy. To overcome this challenge, we propose decomposing each long separation filter into a bilinear form of two shorter filters, thereby reducing the number of parameters. Because the two filters are closely coupled, we design an alternating iterative projection algorithm to update them in turn. Simulation results show that, with far fewer parameters, the proposed method achieves improved performance and robustness.
DynaQuant: Dynamic Mixed-Precision Quantization for Learned Image Compression
Nov 11, 2025Prevailing quantization techniques in Learned Image Compression (LIC) typically employ a static, uniform bit-width across all layers, failing to adapt to the highly diverse data distributions and sensitivity characteristics inherent in LIC models. This leads to a suboptimal trade-off between performance and efficiency. In this paper, we introduce DynaQuant, a novel framework for dynamic mixed-precision quantization that operates on two complementary levels. First, we propose content-aware quantization, where learnable scaling and offset parameters dynamically adapt to the statistical variations of latent features. This fine-grained adaptation is trained end-to-end using a novel Distance-aware Gradient Modulator (DGM), which provides a more informative learning signal than the standard Straight-Through Estimator. Second, we introduce a data-driven, dynamic bit-width selector that learns to assign an optimal bit precision to each layer, dynamically reconfiguring the network's precision profile based on the input data. Our fully dynamic approach offers substantial flexibility in balancing rate-distortion (R-D) performance and computational cost. Experiments demonstrate that DynaQuant achieves rd performance comparable to full-precision models while significantly reducing computational and storage requirements, thereby enabling the practical deployment of advanced LIC on diverse hardware platforms.
Low algorithmic delay implementation of convolutional beamformer for online joint source separation and dereverberation
Jun 14, 2024Blind-audio-source-separation (BASS) techniques, particularly those with low latency, play an important role in a wide range of real-time systems, e.g., hearing aids, in-car hand-free voice communication, real-time human-machine interaction, etc. Most existing BASS algorithms are deduced to run on batch mode, and therefore large latency is unavoidable. Recently, some online algorithms were developed, which achieve separation on a frame-by-frame basis in the short-time-Fourier-transform (STFT) domain and the latency is significantly reduced as compared to those batch methods. However, the latency with these algorithms may still be too long for many real-time systems to bear. To further reduce latency while achieving good separation performance, we propose in this work to integrate a weighted prediction error (WPE) module into a non-causal sample-truncating-based independent vector analysis (NST-IVA). The resulting algorithm can maintain the algorithmic delay as NST-IVA if the delay with WPE is appropriately controlled while achieving significantly better performance, which is validated by simulations.
Fast Adversarial Training against Textual Adversarial Attacks
Jan 23, 2024Many adversarial defense methods have been proposed to enhance the adversarial robustness of natural language processing models. However, most of them introduce additional pre-set linguistic knowledge and assume that the synonym candidates used by attackers are accessible, which is an ideal assumption. We delve into adversarial training in the embedding space and propose a Fast Adversarial Training (FAT) method to improve the model robustness in the synonym-unaware scenario from the perspective of single-step perturbation generation and perturbation initialization. Based on the observation that the adversarial perturbations crafted by single-step and multi-step gradient ascent are similar, FAT uses single-step gradient ascent to craft adversarial examples in the embedding space to expedite the training process. Based on the observation that the perturbations generated on the identical training sample in successive epochs are similar, FAT fully utilizes historical information when initializing the perturbation. Extensive experiments demonstrate that FAT significantly boosts the robustness of BERT models in the synonym-unaware scenario, and outperforms the defense baselines under various attacks with character-level and word-level modifications.
PIAT: Parameter Interpolation based Adversarial Training for Image Classification
Mar 24, 2023
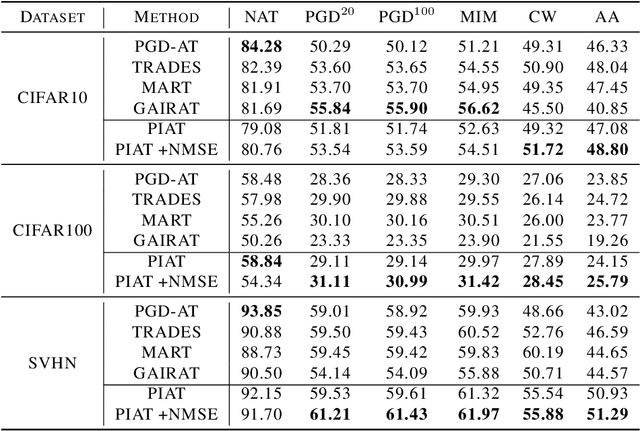
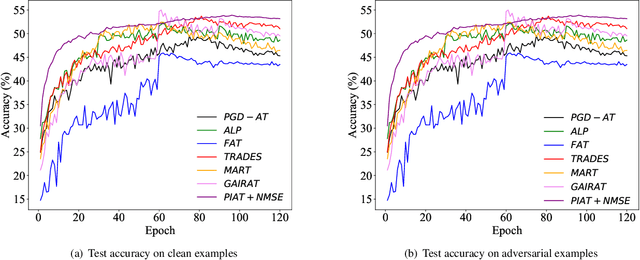
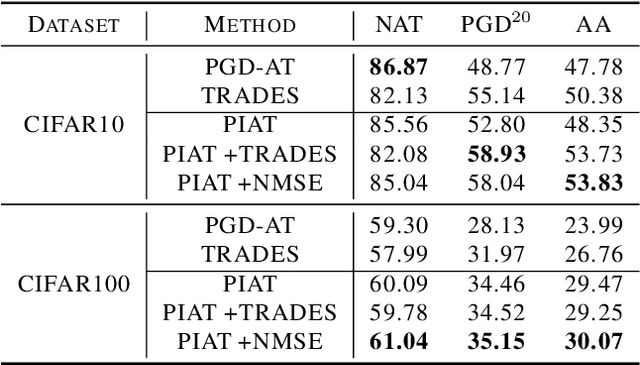
Adversarial training has been demonstrated to be the most effective approach to defend against adversarial attacks. However, existing adversarial training methods show apparent oscillations and overfitting issue in the training process, degrading the defense efficacy. In this work, we propose a novel framework, termed Parameter Interpolation based Adversarial Training (PIAT), that makes full use of the historical information during training. Specifically, at the end of each epoch, PIAT tunes the model parameters as the interpolation of the parameters of the previous and current epochs. Besides, we suggest to use the Normalized Mean Square Error (NMSE) to further improve the robustness by aligning the clean and adversarial examples. Compared with other regularization methods, NMSE focuses more on the relative magnitude of the logits rather than the absolute magnitude. Extensive experiments on several benchmark datasets and various networks show that our method could prominently improve the model robustness and reduce the generalization error. Moreover, our framework is general and could further boost the robust accuracy when combined with other adversarial training methods.
Robust Textual Embedding against Word-level Adversarial Attacks
Feb 28, 2022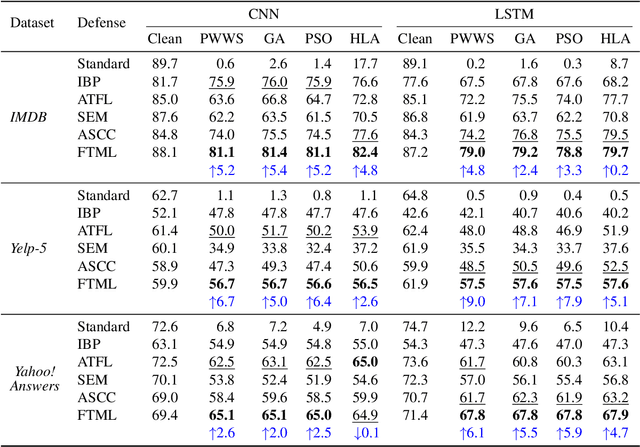
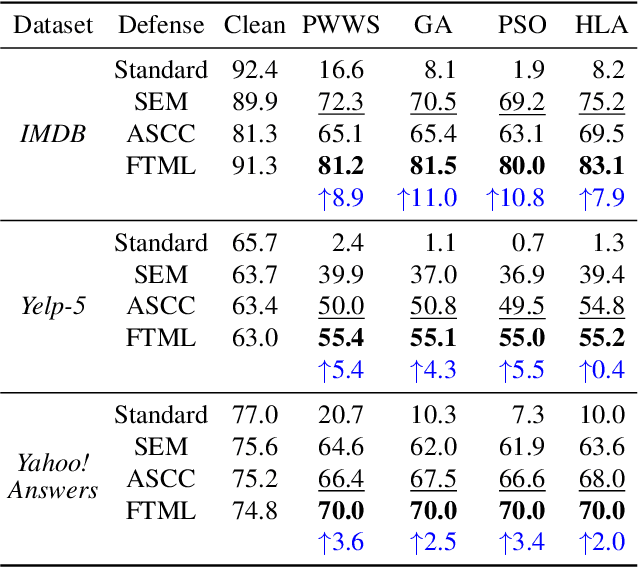
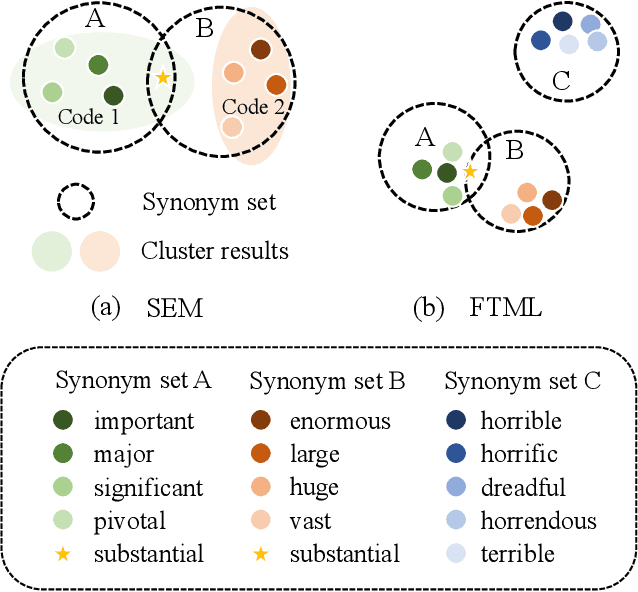
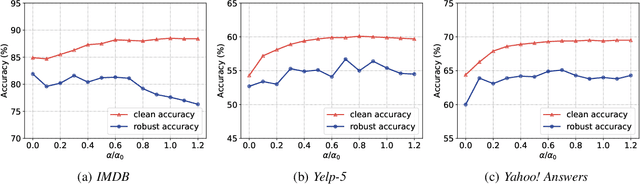
We attribute the vulnerability of natural language processing models to the fact that similar inputs are converted to dissimilar representations in the embedding space, leading to inconsistent outputs, and propose a novel robust training method, termed Fast Triplet Metric Learning (FTML). Specifically, we argue that the original sample should have similar representation with its adversarial counterparts and distinguish its representation from other samples for better robustness. To this end, we adopt the triplet metric learning into the standard training to pull the words closer to their positive samples (i.e., synonyms) and push away their negative samples (i.e., non-synonyms) in the embedding space. Extensive experiments demonstrate that FTML can significantly promote the model robustness against various advanced adversarial attacks while keeping competitive classification accuracy on original samples. Besides, our method is efficient as it only needs to adjust the embedding and introduces very little overhead on the standard training. Our work shows the great potential of improving the textual robustness through robust word embedding.
Regional Adversarial Training for Better Robust Generalization
Sep 04, 2021
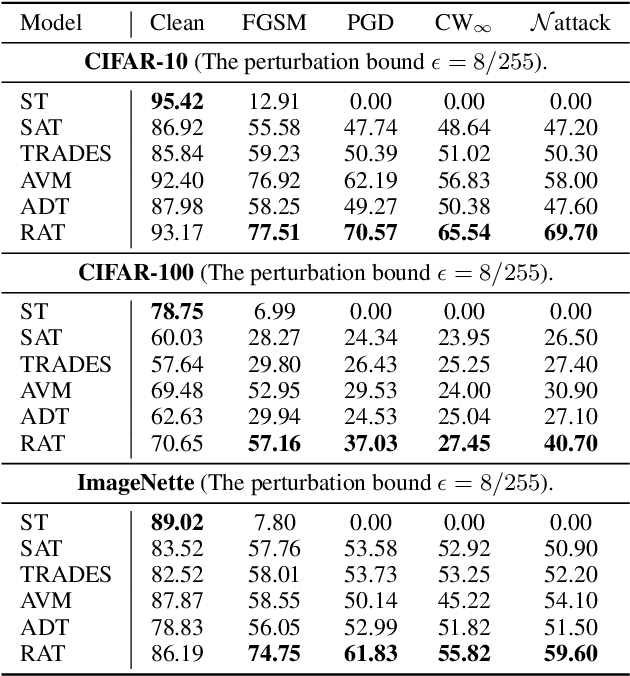
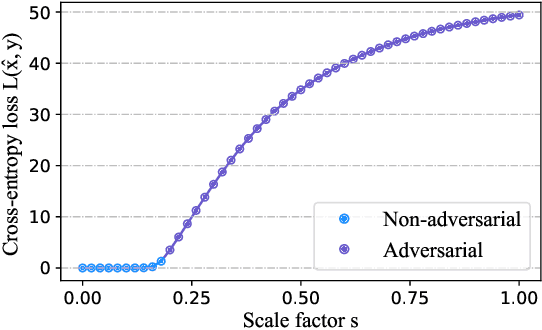
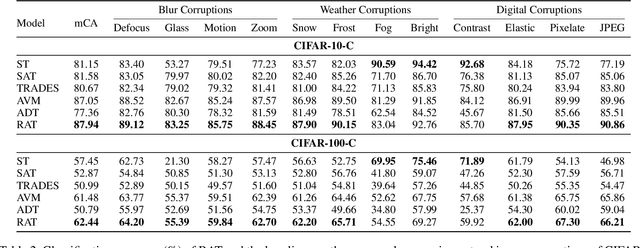
Adversarial training (AT) has been demonstrated as one of the most promising defense methods against various adversarial attacks. To our knowledge, existing AT-based methods usually train with the locally most adversarial perturbed points and treat all the perturbed points equally, which may lead to considerably weaker adversarial robust generalization on test data. In this work, we introduce a new adversarial training framework that considers the diversity as well as characteristics of the perturbed points in the vicinity of benign samples. To realize the framework, we propose a Regional Adversarial Training (RAT) defense method that first utilizes the attack path generated by the typical iterative attack method of projected gradient descent (PGD), and constructs an adversarial region based on the attack path. Then, RAT samples diverse perturbed training points efficiently inside this region, and utilizes a distance-aware label smoothing mechanism to capture our intuition that perturbed points at different locations should have different impact on the model performance. Extensive experiments on several benchmark datasets show that RAT consistently makes significant improvement on standard adversarial training (SAT), and exhibits better robust generalization.
Program Synthesis Guided Reinforcement Learning
Feb 22, 2021


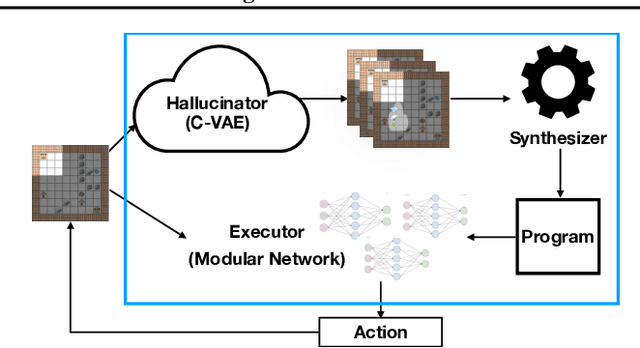
A key challenge for reinforcement learning is solving long-horizon planning and control problems. Recent work has proposed leveraging programs to help guide the learning algorithm in these settings. However, these approaches impose a high manual burden on the user since they must provide a guiding program for every new task they seek to achieve. We propose an approach that leverages program synthesis to automatically generate the guiding program. A key challenge is how to handle partially observable environments. We propose model predictive program synthesis, which trains a generative model to predict the unobserved portions of the world, and then synthesizes a program based on samples from this model in a way that is robust to its uncertainty. We evaluate our approach on a set of challenging benchmarks, including a 2D Minecraft-inspired ``craft'' environment where the agent must perform a complex sequence of subtasks to achieve its goal, a box-world environment that requires abstract reasoning, and a variant of the craft environment where the agent is a MuJoCo Ant. Our approach significantly outperforms several baselines, and performs essentially as well as an oracle that is given an effective program.