 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Generalization Capabilities of Large Language Models on Code Reasoning
Apr 07, 2025We assess how the code reasoning abilities of large language models (LLMs) generalize to different kinds of programs. We present techniques for obtaining in- and out-of-distribution programs with different characteristics: code sampled from a domain-specific language, code automatically generated by an LLM, code collected from competitive programming contests, and mutated versions of these programs. We also present an experimental methodology for evaluating LLM generalization by comparing their performance on these programs. We perform an extensive evaluation across 10 state-of-the-art models from the past year, obtaining insights into their generalization capabilities over time and across different classes of programs. Our results highlight that while earlier models exhibit behavior consistent with pattern matching, the latest models exhibit strong generalization abilities on code reasoning.
Depth-bounded Epistemic Logic
Jul 11, 2023
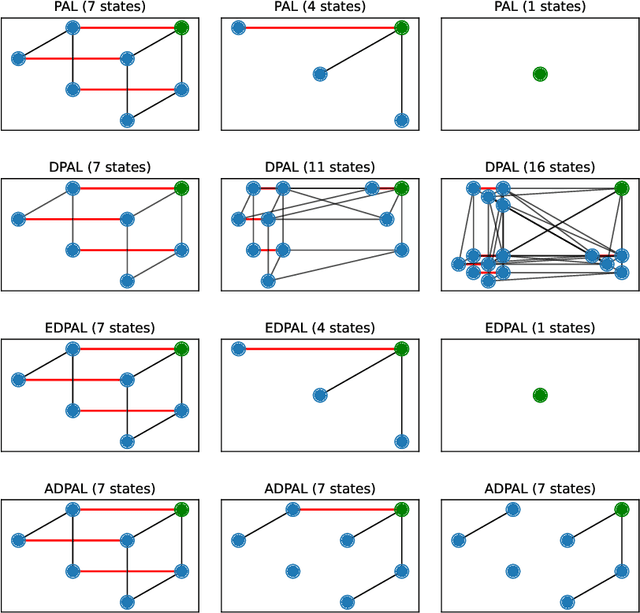

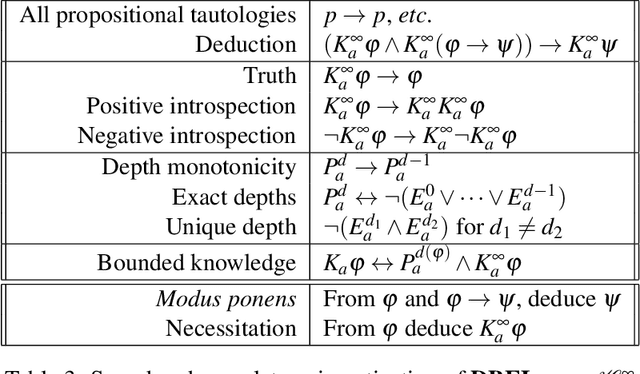
Epistemic logics model how agents reason about their beliefs and the beliefs of other agents. Existing logics typically assume the ability of agents to reason perfectly about propositions of unbounded modal depth. We present DBEL, an extension of S5 that models agents that can reason about epistemic formulas only up to a specific modal depth. To support explicit reasoning about agent depths, DBEL includes depth atoms Ead (agent a has depth exactly d) and Pad (agent a has depth at least d). We provide a sound and complete axiomatization of DBEL. We extend DBEL to support public announcements for bounded depth agents and show how the resulting DPAL logic generalizes standard axioms from public announcement logic. We present two alternate extensions and identify two undesirable properties, amnesia and knowledge leakage, that these extensions have but DPAL does not. We provide axiomatizations of these logics as well as complexity results for satisfiability and model checking. Finally, we use these logics to illustrate how agents with bounded modal depth reason in the classical muddy children problem, including upper and lower bounds on the depth knowledge necessary for agents to successfully solve the problem.
* In Proceedings TARK 2023, arXiv:2307.04005
Sound Explanation for Trustworthy Machine Learning
Jun 08, 2023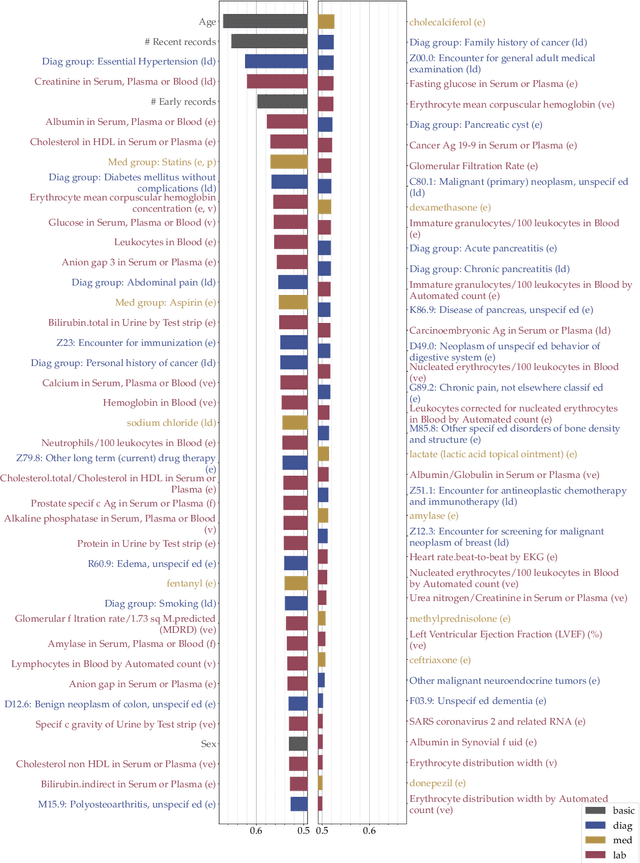
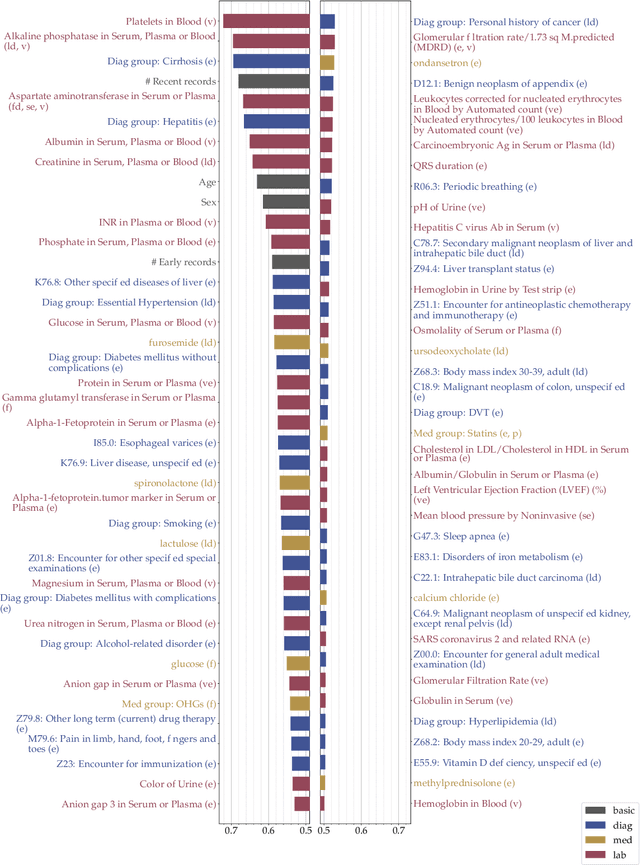
We take a formal approach to the explainability problem of machine learning systems. We argue against the practice of interpreting black-box models via attributing scores to input components due to inherently conflicting goals of attribution-based interpretation. We prove that no attribution algorithm satisfies specificity, additivity, completeness, and baseline invariance. We then formalize the concept, sound explanation, that has been informally adopted in prior work. A sound explanation entails providing sufficient information to causally explain the predictions made by a system. Finally, we present the application of feature selection as a sound explanation for cancer prediction models to cultivate trust among clinicians.
Evidence of Meaning in Language Models Trained on Programs
May 24, 2023We present evidence that language models can learn meaning despite being trained only to perform next token prediction on text, specifically a corpus of programs. Each program is preceded by a specification in the form of (textual) input-output examples. Working with programs enables us to precisely define concepts relevant to meaning in language (e.g., correctness and semantics), making program synthesis well-suited as an intermediate testbed for characterizing the presence (or absence) of meaning in language models. We first train a Transformer model on the corpus of programs, then probe the trained model's hidden states as it completes a program given a specification. Despite providing no inductive bias toward learning the semantics of the language, we find that a linear probe is able to extract abstractions of both current and future program states from the model states. Moreover, there is a strong, statistically significant correlation between the accuracy of the probe and the model's ability to generate a program that implements the specification. To evaluate whether the semantics are represented in the model states rather than learned by the probe, we design a novel experimental procedure that intervenes on the semantics of the language while preserving the lexicon and syntax. We also demonstrate that the model learns to generate correct programs that are, on average, shorter than those in the training set, which is evidence that language model outputs may differ from the training distribution in semantically meaningful ways. In summary, this paper does not propose any new techniques for training language models, but develops an experimental framework for and provides insights into the acquisition and representation of (formal) meaning in language models.
Effective Neural Network $L_0$ Regularization With BinMask
Apr 21, 2023
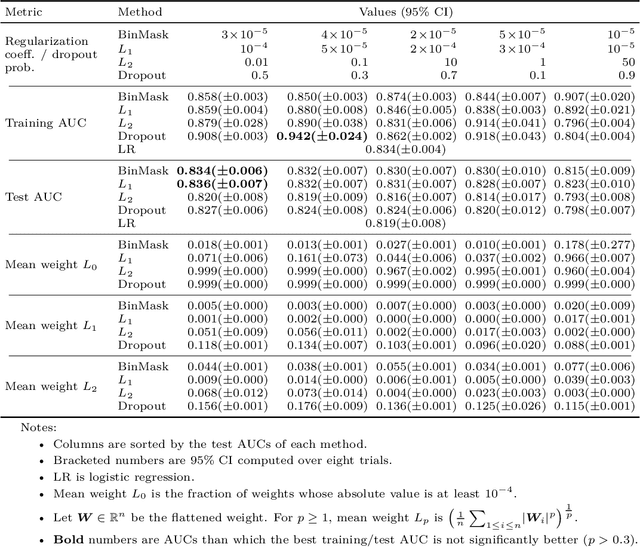
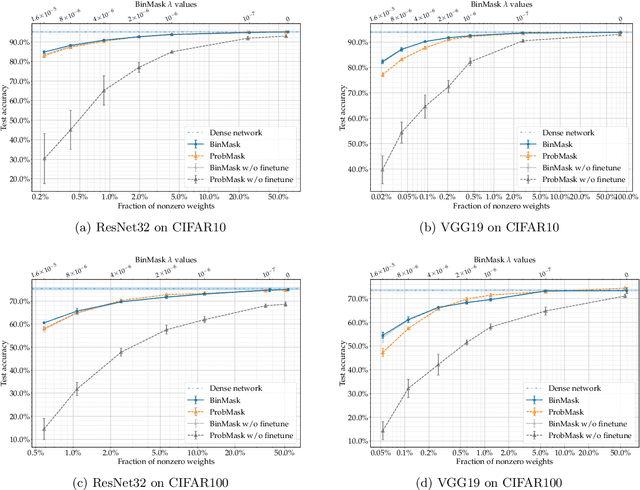
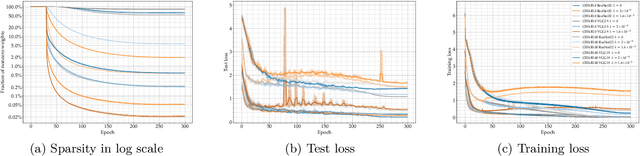
$L_0$ regularization of neural networks is a fundamental problem. In addition to regularizing models for better generalizability, $L_0$ regularization also applies to selecting input features and training sparse neural networks. There is a large body of research on related topics, some with quite complicated methods. In this paper, we show that a straightforward formulation, BinMask, which multiplies weights with deterministic binary masks and uses the identity straight-through estimator for backpropagation, is an effective $L_0$ regularizer. We evaluate BinMask on three tasks: feature selection, network sparsification, and model regularization. Despite its simplicity, BinMask achieves competitive performance on all the benchmarks without task-specific tuning compared to methods designed for each task. Our results suggest that decoupling weights from mask optimization, which has been widely adopted by previous work, is a key component for effective $L_0$ regularization.
Verifying Low-dimensional Input Neural Networks via Input Quantization
Aug 18, 2021

Deep neural networks are an attractive tool for compressing the control policy lookup tables in systems such as the Airborne Collision Avoidance System (ACAS). It is vital to ensure the safety of such neural controllers via verification techniques. The problem of analyzing ACAS Xu networks has motivated many successful neural network verifiers. These verifiers typically analyze the internal computation of neural networks to decide whether a property regarding the input/output holds. The intrinsic complexity of neural network computation renders such verifiers slow to run and vulnerable to floating-point error. This paper revisits the original problem of verifying ACAS Xu networks. The networks take low-dimensional sensory inputs with training data provided by a precomputed lookup table. We propose to prepend an input quantization layer to the network. Quantization allows efficient verification via input state enumeration, whose complexity is bounded by the size of the quantization space. Quantization is equivalent to nearest-neighbor interpolation at run time, which has been shown to provide acceptable accuracy for ACAS in simulation. Moreover, our technique can deliver exact verification results immune to floating-point error if we directly enumerate the network outputs on the target inference implementation or on an accurate simulation of the target implementation.
Provable Guarantees against Data Poisoning Using Self-Expansion and Compatibility
May 08, 2021
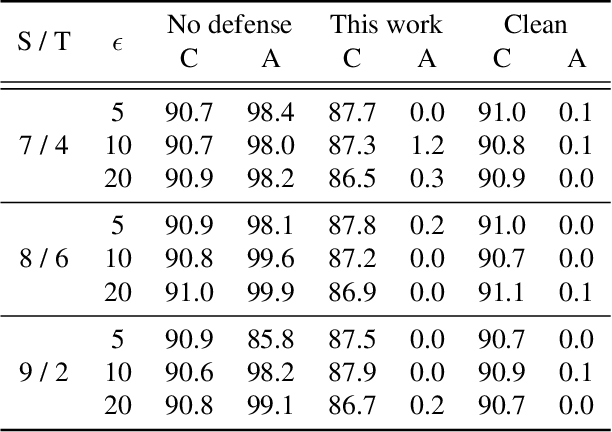

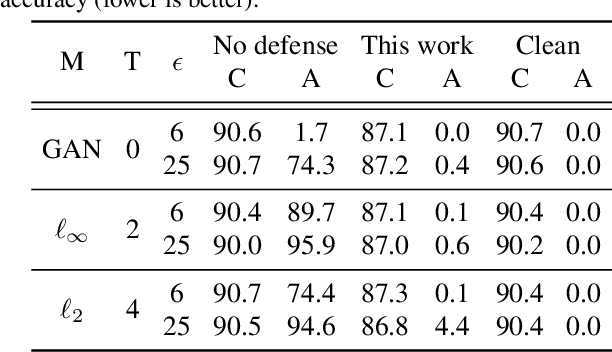
A recent line of work has shown that deep networks are highly susceptible to backdoor data poisoning attacks. Specifically, by injecting a small amount of malicious data into the training distribution, an adversary gains the ability to control the model's behavior during inference. In this work, we propose an iterative training procedure for removing poisoned data from the training set. Our approach consists of two steps. We first train an ensemble of weak learners to automatically discover distinct subpopulations in the training set. We then leverage a boosting framework to recover the clean data. Empirically, our method successfully defends against several state-of-the-art backdoor attacks, including both clean and dirty label attacks. We also present results from an independent third-party evaluation including a recent \textit{adaptive} poisoning adversary. The results indicate our approach is competitive with existing defenses against backdoor attacks on deep neural networks, and significantly outperforms the state-of-the-art in several scenarios.
Inductive Program Synthesis over Noisy Datasets using Abstraction Refinement Based Optimization
Apr 27, 2021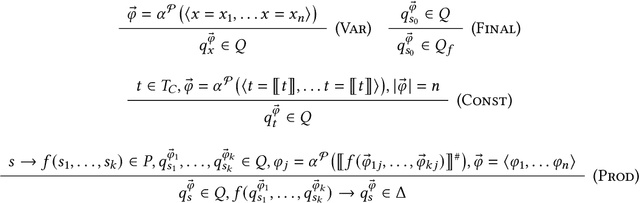
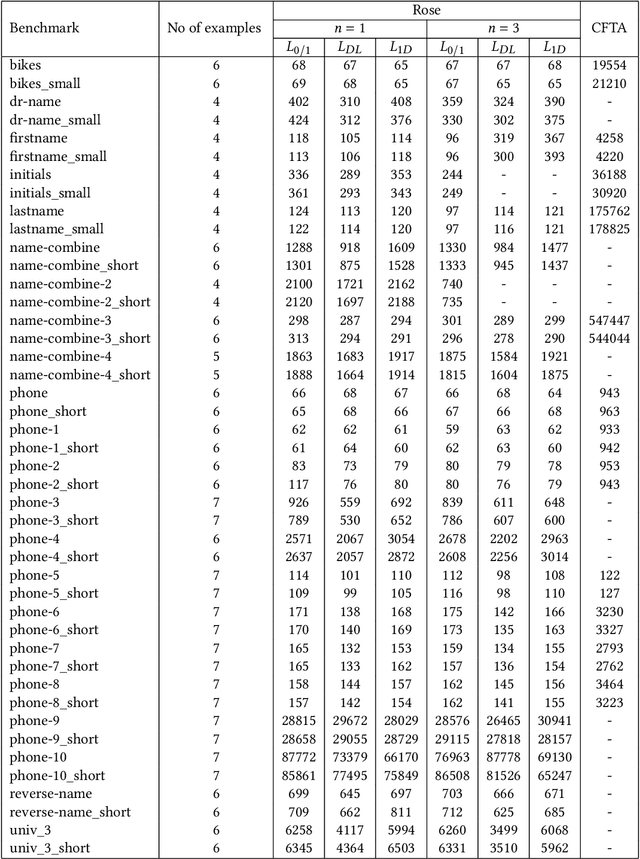

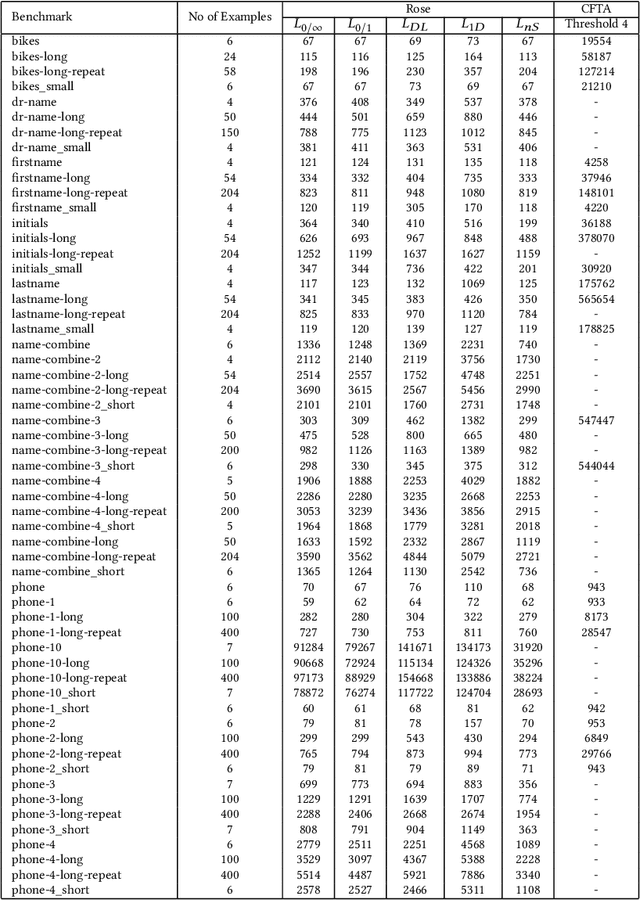
We present a new synthesis algorithm to solve program synthesis over noisy datasets, i.e., data that may contain incorrect/corrupted input-output examples. Our algorithm uses an abstraction refinement based optimization process to synthesize programs which optimize the tradeoff between the loss over the noisy dataset and the complexity of the synthesized program. The algorithm uses abstractions to divide the search space of programs into subspaces by computing an abstract value that represents outputs for all programs in a subspace. The abstract value allows our algorithm to compute, for each subspace, a sound approximate lower bound of the loss over all programs in the subspace. It iteratively refines these abstractions to further subdivide the space into smaller subspaces, prune subspaces that do not contain an optimal program, and eventually synthesize an optimal program. We implemented this algorithm in a tool called Rose. We compare Rose to a current state-of-the-art noisy program synthesis system using the SyGuS 2018 benchmark suite. Our evaluation demonstrates that Rose significantly outperforms this previous system: on two noisy benchmark program synthesis problems sets drawn from the SyGus 2018 benchmark suite, Rose delivers speedups of up to 1587 and 81.7, with median speedups of 20.5 and 81.7. Rose also terminates on 20 (out of 54) and 4 (out of 11) more benchmark problems than the previous system. Both Rose and the previous system synthesize programs that are optimal over the provided noisy data sets. For the majority of the problems in the benchmark sets ($272$ out of $286$), the synthesized programs also produce correct outputs for all inputs in the original (unseen) noise-free data set. These results highlight the benefits that Rose can deliver for effective noisy program synthesis.
Program Synthesis Over Noisy Data with Guarantees
Mar 20, 2021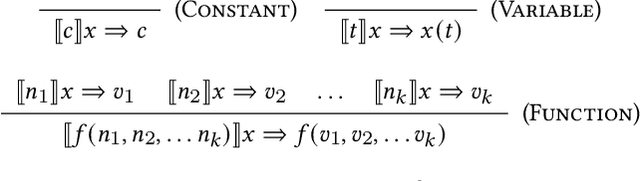
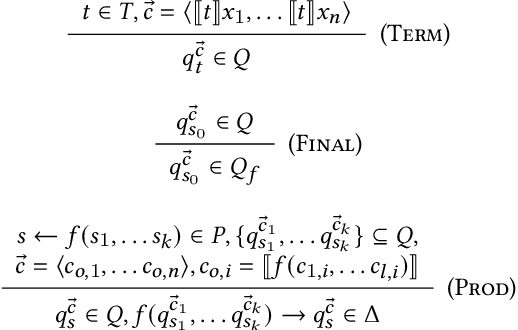
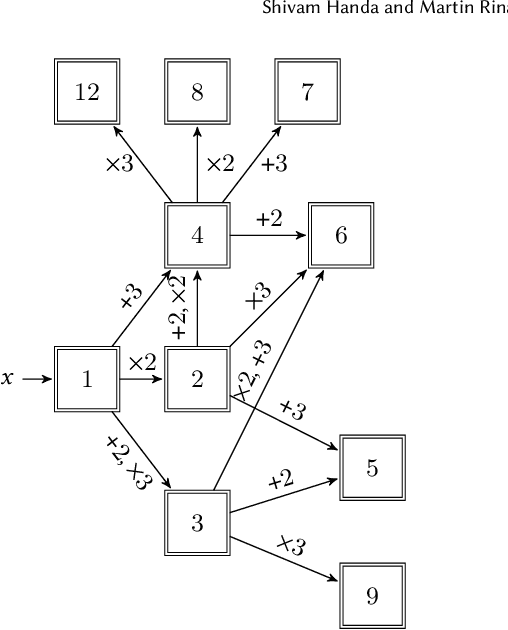
We explore and formalize the task of synthesizing programs over noisy data, i.e., data that may contain corrupted input-output examples. By formalizing the concept of a Noise Source, an Input Source, and a prior distribution over programs, we formalize the probabilistic process which constructs a noisy dataset. This formalism allows us to define the correctness of a synthesis algorithm, in terms of its ability to synthesize the hidden underlying program. The probability of a synthesis algorithm being correct depends upon the match between the Noise Source and the Loss Function used in the synthesis algorithm's optimization process. We formalize the concept of an optimal Loss Function given prior information about the Noise Source. We provide a technique to design optimal Loss Functions given perfect and imperfect information about the Noise Sources. We also formalize the concept and conditions required for convergence, i.e., conditions under which the probability that the synthesis algorithm produces a correct program increases as the size of the noisy data set increases. This paper presents the first formalization of the concept of optimal Loss Functions, the first closed form definition of optimal Loss Functions, and the first conditions that ensure that a noisy synthesis algorithm will have convergence guarantees.
Program Synthesis Guided Reinforcement Learning
Feb 22, 2021


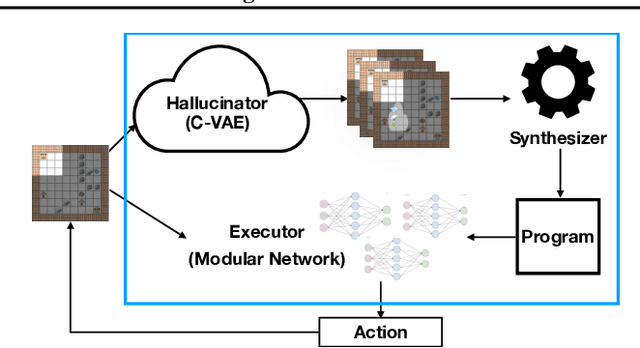
A key challenge for reinforcement learning is solving long-horizon planning and control problems. Recent work has proposed leveraging programs to help guide the learning algorithm in these settings. However, these approaches impose a high manual burden on the user since they must provide a guiding program for every new task they seek to achieve. We propose an approach that leverages program synthesis to automatically generate the guiding program. A key challenge is how to handle partially observable environments. We propose model predictive program synthesis, which trains a generative model to predict the unobserved portions of the world, and then synthesizes a program based on samples from this model in a way that is robust to its uncertainty. We evaluate our approach on a set of challenging benchmarks, including a 2D Minecraft-inspired ``craft'' environment where the agent must perform a complex sequence of subtasks to achieve its goal, a box-world environment that requires abstract reasoning, and a variant of the craft environment where the agent is a MuJoCo Ant. Our approach significantly outperforms several baselines, and performs essentially as well as an oracle that is given an effective program.